mai
2012
 Un article de Sergejack
Un article de Sergejack

Et si on se passait des clés étrangères ?
Calmons tout de suite l’appréhension qu’une telle question pourrait faire naître dans l’esprit aguerri des routards du SQL. Ce sujet n’a pas pour but de convaincre le lecteur que toutes les clés étrangères seraient inutiles voire néfastes (car ce n’est pas le cas). Plutôt, il existe des situations dans lesquelles ne pas définir les clés étrangères est un choix légitime et faire connaître ces situations est l’objectif que je me donne dans ce sujet.
Avant d’aller plus loin, il me faut préciser que ce sujet ne pourrait voir l’application de son propos que régit à la plus grande des prudences. En effet, les clés étrangères sont de précieux garde-fous et ne devraient pas être ignorées à la légère.
Note :
Quand je parle de clé étrangère, je parle de la contrainte (« FOREIGN KEY ») et non de la présence d’un ensemble de données permettant la relation entre les lignes d’une ou plusieurs tables.
Pourquoi et Quand ?
Lorsque que vous avez une relation (entre plusieurs tables ou récursive) qui rendent certaines lignes indissociables de certaines autres (scénario dans lequel vous auriez habituellement des clés étrangères), alors, suite à la suppression de lignes (influentes) dont en dépendent d’autres (dépendantes), il vous faudrait tôt ou tard répercuter cette suppression à ces lignes dépendantes (afin de ne pas conserver de données inutiles).
Lorsque la charge de vos serveurs le permet, vous pouvez tout à fait réaliser ces suppressions « en même temps » que les suppressions qui les provoquent.
Vous faites habituellement cela par la clause « ON DELETE CASCADE » d’une contrainte de clé étrangère et/ou par le biais de triggers.
Dans ce cas-là, l’intérêt d’avoir des clés étrangères est entier et ce sujet ne relativisera pas leur emploie
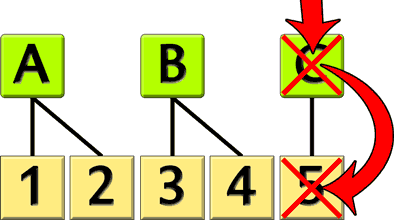
La suppression de « C » dans la « table verte » cause « immédiatement » la suppression de « 5 » dans la « table jaune ».
Par contre, lorsque la charge de vos serveurs vous incite à différer ces suppressions, vous devez choisir une stratégie pour permettre à ces suppressions d’avoir ultérieurement lieu.
Couramment, il est choisi de rompre la dépendance tout en marquant les lignes qui doivent être supprimée par une seule et même action. Soit en recréant un lien entre ces lignes à supprimer et une ligne factice et prédéterminée qui sert d’indicateur (il s’agit de la clause « ON DELETE SET DEFAULT »). Soit en laissant le lien se perdre (clause « ON DELETE SET NULL »).
Ces deux façon de faire ont un impact sur les performances qui, bien que généralement moindre à une suppression effective, restent significatifs.
En effet, toutes les lignes dépendantes à celles qui sont supprimés sont « simultanément » mises à jour (écritures disques, ré-indexation potentielle et risques de race condition).
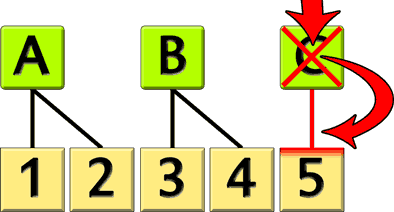
Suite à la suppression de « C », cause « immédiatement » la modification de « 5 » pour que la liaison soit supprimée (« SET NULL »).
C’est en partant du constat de cet impact sur les performances que commence à s’envisager la possibilité de se passer de la clé étrangère.
Pourquoi pas ?
Comme précisé plus haut, il faut être et resté prudent (prudence est mère de sûreté).
En se passant de la clé étrangère et en n’employant aucun marqueur sur les lignes dépendantes qui doivent à terme être supprimées (à partir de ce point, je dirai de telles lignes qu’elles sont virtuellement supprimées), il devient moins évident qu’une ligne virtuellement supprimée, l’est.
En effet, pour se rendre compte que le lien d’une ligne dépendante à une ligne influente est rompu, il faudra systématiquement vérifier l’existence de la ligne influente. Cela n’est pas gênant quand, dans toutes vos requêtes, vous soumettez déjà les lectures des lignes dépendantes à leur relation aux lignes influentes (typiquement, « INNER JOIN »). Mais, dans le cas contraire, si dans certaines requêtes, vous consultez les lignes dépendantes sans « vérifier » leur relation aux lignes influentes dont elles dépendent, vous serez alors en train de consulter des lignes virtuellement supprimées. Ce dernier scénario pourrait, vous vous en rendez compte, vous causez un certain nombre de surprises et donc de problèmes.
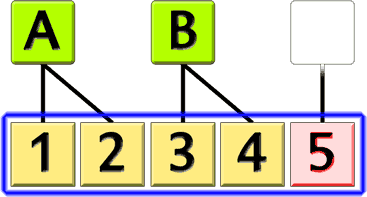
Si la relation de la « table jaune » à la « table verte » n’est pas vérifiée, la ligne « 5 » virtuellement supprimée pourrait apparaître dans le résultat.
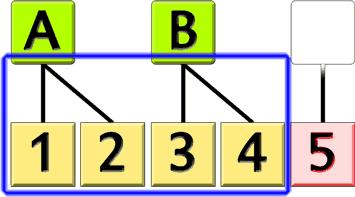
Si la relation de la « table jaune » à la « table verte » est vérifiée, la ligne « 5 » virtuellement supprimée ne pourrait pas apparaître dans le résultat.
Comment ?
Voici la partie la plus simple, pour de nouvelles tables il suffit de ne pas définir la clé étrangère et pour les tables existantes, il suffit de la supprimer. Par ailleurs il faut quand même créer/adapter les processus de nettoyage pour qu’ils détectent les lignes virtuellement supprimées non plus directement grâce à un marqueur (clé étrangère à « NULL » par exemple) mais en vérifiant l’existantes des lignes influentes.
Conclusion :
Les clés étrangères sont des garde-fous importants mais avec une réflexion et une prudence suffisante, ce qu’elles coûtent aux performances lors des suppressions peut vous faire préférer d’en éviter certaines. Atteindre certains sommets implique une prise de risque que seule une grande maîtrise pourrait justifier. Donc, si vous êtes sûrs de vous, je vous le dit : ne pas définir une clé étrangère ne vous tuera pas et a des bénéfices certains.
8 Commentaires + Ajouter un commentaire
Commentaires récents
- dans Et si on se passait des clés étrangères ?
- dans Quand les fonctions tables surpassent les vues et CTE.
- dans Quelques choses à savoir sur les espaces en fin de chaîne
- dans Assigner des variables et renvoyer un résultat en une seule opération
- dans Quelques choses à savoir sur les espaces en fin de chaîne
Ce que vous dîtes, tout aussi croustillante soit-il, ne concerne pas la mécanique défendue dans ce billet.
Il s’agit ici d’un scénario tout à fait analogue à ce que vous avez l’habitude de faire en jouant de SET DEFAULT.
La seule différence (encore une fois, soulignée dans ce billet) est la nécessité de ne jamais récupérer/modifier/insérer des lignes « dépendantes » sans jointure avec les lignes « influentes » (à une ou plusieurs niveaux).
Si vos tomodachi avaient procédé ainsi (sans que cela aurait forcément été judicieux) il n’auraient pas eu une seule ligne orpheline.
Quant aux suppressions, elles sont faites par batch aux heures creuse.
Il existe des solutions robustes et performante où des tables de schemas différents sont en relation, comme quoi la vie sans FK est possible.
Ce n’est pas spécialement pour abonder dans le sens de SQLPRO mais votre approche me semble bien naïve…
Vous partez du POSTULAT que votre « technique » est infaillible car « tout le monde il est gentil tout le monde il est compétent, et personne ne ferait de requête en oubliant la jointure ».
Et bien on ne vit pas dans le même monde…
Impossible pour moi de cautionner cela, il y aura toujours des « boulettes » de faites d’autant plus probables à la vue du niveau moyen en SQL des développeurs (non DBA j’entends…)…
La preuve même les japonais se sont fait avoir
J’en reste là…
Pour avoir fait depuis une vingtaine d’années de nombreux audits de bases de données, je n’ai jamais vu de base dans laquelle l’absence de contrainte de clef étrangère FOREIGN KEY, et donc l’absence d’intégrité référentielle ne se traduisait pas en production par des lignes orphelines.
Expérience récente : chez un des grand constructeur de photocopieurs japonais, audit d’une des plus grosse base de données de SAV client réalisée par l’équipe japonaise. Les japonais étant très pointilleux sur la qualité, ils nous avaient assuré que l’application gérait parfaitement l’intégrité des données et qu’en aucun cas ils avaient détecté d’anomalies.
J’ai d’ailleurs été brillamment surpris : seules, deux tables avaient des lignes orphelines. L’une, une seule ligne, l’autre plusieurs, mais moins de 1% du volume total.
Lors de la remise de mon rapport d’audit, j’ai pointé du doigt cette problématique qui engendrait non seulement des problèmes de performances, mais aussi des statistiques fausses et des traitements mineurs erronés.
Mais on m’a demandé de modifier mon rapport fournit en PDF, afin de supprimer ce paragraphe. L’équipe française étant persuadé qu’à la lecture du document les développeurs japonais allaient se faire harakiri…
En fait il est mathématiquement impossible de réaliser l’intégrité référentielle par du code applicatif, tout simplement parce que les bases de données fonctionnement d’un SGBDR est ensembliste (modification d’un ensemble de lignes de manière simultané) alors que le code applicatif est itératif, c’est à dire agissant ligne à ligne.
Notez que Frank Edgar Codd, pointe du doigt dès l’origine, cette problématique dans sa règle n°12 :
«
Non subversion : Il ne doit pas être possible de transgresser les règles d’intégrité et les contraintes
définies par le langage relationnel du SGBDR en utilisant un langage de plus bas
niveau (gérant une seule ligne à la fois).
«
A +
-Se passer des contraintes FK n’a rien de stupide.-
Cher Terminator (j’ai bien vu votre présentation), la seule stupidité que je voit ici est celle de vos habituelles suffisance et entêtement.
Pour rendre service aux lecteurs (qui souvent vous font confiance), je vais me permettre avant de vous répondre, de trancher un bon coup dans l’aura de gourou qui vous entoure.
Vous vivez (bien, je suppose) de la diffusion de vos connaissances (livres, cours, etc.) et la contradiction de vos propos ne s’inscrit pas dans votre business plan.
Néanmoins, vous avez plus souvent que vous ne l’imaginez tort et vous vous cramponnez aux seuls scénarios que vous même aillé envisagés ou rencontrés. Vous avez l’entêtement d’un Terminator et cela handicape très fortement le potentiel dont vous dotent vos connaissances (que j’apprécie, figurez-vous).
Maintenant, en réponse à votre remarque :
1) Ne confondez pas contrainte et donnée.
Je parle bien de supprimer la contrainte, je ne parle aucunement de dé-normaliser les tables.
Donc, les tables et jointures restent les même, seule la contrainte tombe.
2) Les contraintes FK permettent de ne pas avoir à vérifier la jointure.
Voici l’optimisation à laquelle vous songez (et dont vous parlez dans votre présentation) :
Quand des tables sont mises en relations dans une requête et qu’il existe une contrainte FK à cet effet, si aucune données de la table influente ne sont exploitées alors SQL Server ne va pas réellement faire la jointure.
Si SQL Server peut faire fit d’une jointure, le développeur de qualité en fera tout autant.
Car ce dernier aura la même présence d’esprit que SQL Server de ne pas « vérifier ce que la contrainte garantit déjà ».
Je sais tout cela et je traite ce point dans le sujet.
Section « Pourquoi pas », je me cite « Cela n’est pas gênant quand, dans toutes vos requêtes, vous soumettez déjà les lectures des lignes dépendantes à leur relation aux lignes influentes ».
Voilà.
En conclusion : se passer des contraintes FK n’a rien de stupide.
PS: Lorgnez un peu du côté de la communauté anglophone, ils sont bien plus créatifs (et moins bornés) que la communauté francophone dont vous êtes justement l’un des étendards
C’est d’autant plus stupide de se passer de clef étrangères (Foreign Keys) que certains SGBDR comme SQL Server dispose d’une optimisation sémantique qui utilise les contraintes pour simplifier les plans de requêtes…
De plus il faudra se débarrasser des lignes orphelines en faisant des requêtes plus complexes, donc forcément plus couteuses.
Bref, croire que les contraintes c’est couteux et que l’on peut s’en passer est toujours hautement stupide. C’est une vue à court terme, qui à conduit de nombreux benêts à utiliser des SGBDR bas de gamme du genre MySQL et se trouver aujourd’hui dans des impasses techniques et de performances dramatique, car ce que l’on a pas fait dans les fondations, va rejaillir immanquablement en bien pire lors de la construction des étages :!!!
Pour une idée sur l’importance des contraintes pour l’optimisation des requêtes, regardez la démo que j’ai fait dans le cadre des SQL days 2011 chez Microsoft. Contraintes et performances / Journées SQL Server
A +
J’ai fait des mesures avec des jeux de tests mais ceux-ci ne révèlent rien de plus que ce que j’ai écrit : les clause ON DELETE SET NULL et ON DELETE SET DEFAULT ont un coût et peuvent mener à des deadlock (ce que je n’ai pas cherché à provoquer par contre).
Je n’ai (hélas ?) pas conserver ces jeux de tests.
De toute façon, comme pour bien des considérations, il est impossible d’affirmer que l’impact sur les performances sera d’un ou autre ordre de grandeur tellement cela varie d’une utilisation à l’autre.
Et en plus, je ne souhaite pas inciter les néophytes qui à la lecture de certains chiffres pourraient trop rapidement se lancer le défis risqué d’éliminer certaines FK.
Donc, si ce sont des chiffres dont il faut avoir conscience qu’ils ne veulent pas tout dire, autant ne pas les employer et laisser le lecture faire son appréciation personnelle.
Pour l’anecdote je vais quand même vous dire ce que certains tests m’ont permit de voir :
Dans ces tests, la suppression avec FK était en moyenne 10x plus lente que la suppression sans.
Et il est régulièrement plus rapide de faire une suppression dans une table influente et ensuite de vérifier la relation pour la table dépendante (sans FK mais avec un index) que de juste faire une suppression dans une table influente (quand y est liée une FK).
Par conséquent, la suppression dans les deux tables est plus rapide sans FK.
Gardez cela pour vous, je vous ai expliqué pourquoi je ne m’étalerai pas sur des chiffres (transcrits de bonne foi) dans le sujet
Comme toute action liée à l’optimisation, il me parait effectivement vital de mesurer l’impact positif (ou non…) sur les performances d’un tel système avant de prendre une telle décision… ce qui me gêne le plus en définitive, c’est que mesurer le risque à terme sur l’intégrité des données est par contre très hasardeux.
Le risque majeur ici, c’est que si on est sûr de nous pour le faire, c’est probablement qu’on l’est à tort… en tout cas merci pour cet article, ça fait du bien de lire des idées qui font réagir.
Je trouve dommage d’en arriver à une telle conclusion, sans avoir mesurer de manière précise le coût de ces « mises à jour » réalisées par ON DELETE SET NULL ou DEFAULT.
Là on plus dans la supposition que dans la réalité des faits.