Mathematica est un logiciel Ă l’origine prĂ©vu pour le calcul symbolique (spĂ©cifiquement pour un public de mathĂ©maticiens, d’oĂą son nom), mais qui s’est ouvert Ă bien d’autres domaines depuis lors : sur ces trente dernières annĂ©es, son domaine d’action s’est largement Ă©tendu en dehors des mathĂ©matiques pures, notamment au niveau de la visualisation, du traitement du signal et des images, des statistiques et de l’apprentissage automatique. Avec le lancement de Wolfram Alpha, un « moteur de connaissances numĂ©rique », le logiciel a directement eu accès Ă une plĂ©thore de donnĂ©es diverses, tant sur les Ă©lĂ©ments chimiques que la sociologie ou la finance, ce qui dĂ©cuple encore ses capacitĂ©s. Un rĂ©sumĂ© de ces domaines est prĂ©sentĂ© en première page de la documentation. Ces dernières annĂ©es, les amĂ©liorations ont aussi portĂ© sur la manière de dĂ©ployer ses dĂ©veloppements avec Mathematica : le format CDF permet d’exporter des documents (le CDF Player peut exĂ©cuter les commandes incluses), Wolfram Cloud propose d’exĂ©cuter du code Mathematica dans le nuage.
La version 11 de cet environnement complet propose pas moins de 555 nouvelles fonctions (alors que la première version n’en contenait que 551), sans compter les nouvelles fonctionnalitĂ©s ajoutĂ©es aux fonctions prĂ©cĂ©dentes. Cependant, la rĂ©trocompatibilitĂ© est au cĹ“ur des dĂ©veloppements : tout programme Mathematica Ă©crit depuis la version 7 restera entièrement compatible avec les dernières versions (il n’y a plus eu de changement incompatible depuis lors) et bon nombre d’applications restent compatibles depuis la première version du logiciel, en 1988.
Cela est possible grâce au principe de cohĂ©rence dans la conception de l’interface des fonctions, dans le plus pur style fonctionnel : toute fonctionnalitĂ© est prĂ©vue pour rester dans la durĂ©e, ce qui permet de construire de nouvelles fonctionnalitĂ©s par-dessus. Quand les dĂ©veloppeurs n’ont pas achevĂ© une fonctionnalitĂ©, mais qu’elle peut dĂ©jĂ ĂŞtre utile aux diffĂ©rents utilisateurs, elle est proposĂ©e sous une forme expĂ©rimentale : elle est utilisable, mais il n’y a aucune garantie que l’interface restera inchangĂ©e (il faut d’ailleurs inclure spĂ©cifiquement des modules, ils ne sont pas disponibles par dĂ©faut).
Améliorations esthétiques
En ouvrant Mathematica 11 la première fois, on remarque vite les changements apportĂ©s Ă l’interface graphique, mĂŞme s’ils sont relativement mineurs. Les polices utilisĂ©es sont plus nettes et plus denses. L’autocomplĂ©tion a Ă©tĂ© amĂ©liorĂ©e, elle est plus contextuelle et fait des propositions y compris pour les options. De plus, chaque commande est maintenant annotĂ©e dans la langue de l’utilisateur, ce qui en facilite la comprĂ©hension pour ceux qui ne maĂ®trisent pas suffisamment l’anglais. Les messages d’erreur sont aussi plus instructifs et proposent Ă©galement d’afficher la pile d’appel au moment de l’erreur.
Impression 3D
L’une des nouvelles zones de fonctionnalitĂ©s de Mathematica est l’impression 3D. Les versions prĂ©cĂ©dentes pouvaient dĂ©jĂ exporter des gĂ©omĂ©tries en STL, mais la 11 propose toute la chaĂ®ne d’impression, depuis la crĂ©ation d’une gĂ©omĂ©trie 3D Ă son impression (par une machine locale ou par un prestataire externe) — en prenant en compte les limites techniques de l’impression 3D. Il devient ainsi possible d’imprimer tout graphique tridimensionnel, toute structure molĂ©culaire, toute partie de la Terre (par exemple, la gĂ©ographie autour d’une montagne).

Apprentissage automatique
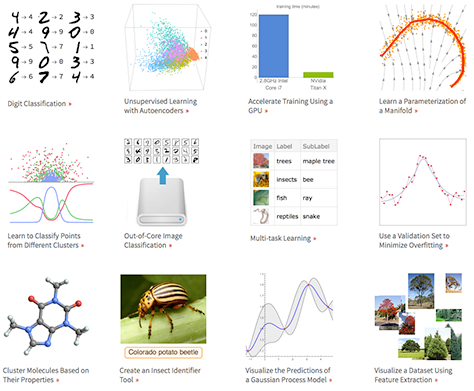
Un des grands termes Ă la mode actuellement est l’apprentissage automatique (en anglais, machine learning), notamment tout ce qui a trait aux rĂ©seaux neuronaux et Ă l’apprentissage profond (Intel et NVIDIA se battent d’ailleurs sur la performance de leurs puces respectives pour l’apprentissage de rĂ©seaux neuronaux profonds). La version 10 de Mathematica avait dĂ©jĂ apportĂ© une interface très simple d’utilisation pour bon nombre de cas, avec les fonctions Classify[] et Predict[] pour la classification et la rĂ©gression (apprentissage supervisĂ©), en donnant accès Ă une foultitude d’algorithmes sous une interface unifiĂ©e (rĂ©gression linĂ©aire, logistique, forĂŞts alĂ©atoires, plus proches voisins, rĂ©seaux neuronaux, etc.).
Cette nouvelle version apporte Ă©galement une interface unifiĂ©e pour l’extraction de caractĂ©ristiques, la rĂ©duction de dimensionnalitĂ©, le groupement d’Ă©lĂ©ments, la dĂ©termination d’une loi de probabilitĂ©, l’apprentissage par renforcement. Une nouveautĂ© est aussi la mise Ă disposition de modèles dĂ©jĂ entraĂ®nĂ©s, par exemple pour la classification d’images selon leur contenu.

Du cĂ´tĂ© des rĂ©seaux neuronaux, Mathematica s’appuie sur ses capacitĂ©s symboliques de calcul pour proposer des rĂ©seaux reprĂ©sentĂ©s de manière symbolique : on peut alors associer n’importe quel genre de couche et visualiser les rĂ©seaux, mais aussi les entraĂ®ner sur des donnĂ©es (aussi sur GPU) et analyser leur performance, puisque ces rĂ©seaux sont stockĂ©s comme des graphes. Les couches de base sont dĂ©jĂ implĂ©mentĂ©es (combinaison linĂ©aire d’entrĂ©es, fonctions d’activation sigmoĂŻdes), tout comme les dĂ©veloppements rĂ©cents de l’apprentissage profond (autoencodeurs, rĂ©seaux convolutionnels). Les rĂ©seaux rĂ©currents sont en cours de dĂ©veloppement, mais pas encore prĂŞts.
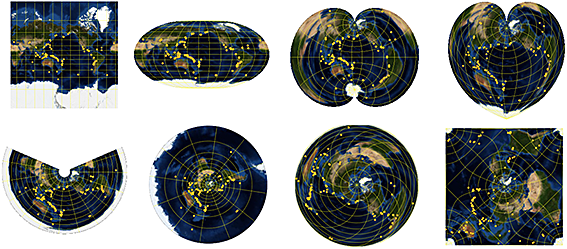
GĂ©ographie
Travailler sur la gĂ©ographie de la Terre et d’autres planètes n’est pas toujours Ă©vident, puisqu’elle n’est pas plate. Mathematica ne fait pas que donner accès aux informations sur bon nombre de planètes, il dispose aussi de fonctions pour effectuer des calculs sur ces gĂ©omĂ©tries particulières : il dispose d’une bonne collection de projections gĂ©ographiques, pour proposer des calculs prĂ©cis de gĂ©odĂ©sie. Ces capacitĂ©s s’Ă©tendent aussi aux cartes, avec l’accès aux dĂ©tails de chaque rue, mais aussi les frontières historiques de chaque pays et des images satellites de basse rĂ©solution.
Calculs numériques
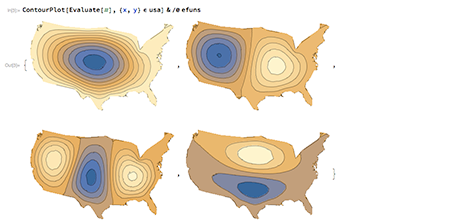
Au niveau numĂ©rique, il devient possible de rĂ©soudre des Ă©quations diffĂ©rentielles (y compris aux dĂ©rivĂ©es partielles) par leurs valeurs propres dans n’importe quel domaine, y compris en spĂ©cifiant des conditions aux limites. Ces solveurs sont totalement gĂ©nĂ©riques : il n’y a pas besoin de connaissances poussĂ©es en algorithmique numĂ©rique, Mathematica dĂ©termine seul une bonne manière de rĂ©soudre le problème donnĂ©. Ces systèmes fonctionnent en s’intĂ©grant avec les fonctionnalitĂ©s gĂ©omĂ©triques prĂ©existantes, ce qui permet notamment d’Ă©tudier la rĂ©ponse d’une peau de tambour qui aurait la forme des États-Unis.
Dans des domaines connexes, le calcul symbolique fait encore des progrès : il devient maintenant possible de rĂ©soudre de manière symbolique un grand nombre d’Ă©quations aux dĂ©rivĂ©es partielles qui apparaissent dans les manuels, mais aussi des Ă©quations mĂ©langeant des dĂ©rivĂ©es et des intĂ©grales. CĂ´tĂ© numĂ©rique, les fonctions d’optimisation ont vu leur performance et leur robustesse amĂ©liorĂ©es, ce qui sert notamment aux fonctionnalitĂ©s d’apprentissage automatique.
Programmation généraliste
MĂŞme si Mathematica n’a pas commencĂ© comme un langage de programmation gĂ©nĂ©raliste, il s’Ă©tend Ă©galement dans cette direction. Ainsi, il peut maintenant travailler sur des sĂ©quences d’octets bruts reçus sur un socket, effectuer des mesures sur un rĂ©seau (Ping pour le moment). La cryptographie fait son apparition, tant symĂ©trique qu’asymĂ©trique.
Source et images : Today We Launch Version 11!.
Voir aussi : toutes les nouveautés depuis Mathematica 10.4, mise en contexte de certaines nouveautés.