En 1964 a Ă©tĂ© construit le premier superordinateur, nommĂ© Control Data 6600, avec une puissance de calcul d’un mĂ©gaflops, c’est-Ă -dire un million d’opĂ©rations en virgule flottante chaque seconde (comme additionner deux nombres Ă virgule). Il a Ă©tĂ© conçu par Seymour Cray, qui a lancĂ© la sociĂ©tĂ© Cray, connue pour son activitĂ© dans les supercalculateurs.
Vingt et un ans plus tard, en 1985, la barre du gigaflops a été franchie par Cray-2. Actuellement, un processeur haut de gamme (comme un Intel i7 de dernière génération) fournit approximativement cent gigaflops.
Une dizaine d’annĂ©es plus tard, en 1997, ASCI Red explose le tĂ©raflops, mille milliards d’opĂ©rations en virgule flottante par seconde ; dans cette sĂ©rie de records, c’est le premier Ă ne pas ĂŞtre associĂ© au nom de Cray. Un processeur graphique moderne haut de gamme (comme la GeForce GTX Titan X) dĂ©passe maintenant quelques tĂ©raflops.
Il y a presque dix ans, Roadrunner atteignant le pĂ©taflops, en combinant une sĂ©rie de processeurs similaires Ă ceux utilisĂ©s dans les PlayStation 3. Aujourd’hui, le plus puissant est Tianhe-2, installĂ© en Chine (alors que les prĂ©cĂ©dents sont amĂ©ricains), avec une cinquantaine de pĂ©taflops. La route semble encore longue jusqu’Ă l’exaflops, c’est-Ă -dire un milliard de milliards d’opĂ©rations en virgule flottante par seconde. Ă€ nouveau, les États-Unis ont lancĂ© un projet pour atteindre cette puissance de calcul Ă l’horizon 2020 — plus particulièrement, le DĂ©partement de l’Énergie, le mĂŞme Ă investir massivement dans un compilateur Fortran moderne libre.
Ces nombres paraissent Ă©normissimes : un milliard de milliards d’opĂ©rations par seconde. Outre les aspects purement informatiques, ce genre de projets a une grande importance pour la recherche scientifique : les laboratoires amĂ©ricains de l’Énergie Ă©tudient notamment l’arme nuclĂ©aire et la destruction en toute sĂ©curitĂ© d’ogives ; en Europe, le Human Brain Project vise Ă simuler toute l’activitĂ© cĂ©rĂ©brale d’un cerveau humain au niveau neuronal, ce qui nĂ©cessiterait une puissance de calcul de cet ordre de grandeur.
Comment y arriver ?
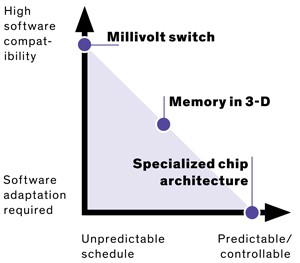
Le DĂ©partement de l’Énergie estime que, actuellement, toutes les technologies nĂ©cessaires pour construire un tel superordinateur sont rĂ©unies. Cependant, il serait extrĂŞmement difficile de l’alimenter : il faudrait un rĂ©acteur nuclĂ©aire complet pour y arriver ! MĂŞme si la construction de rĂ©acteurs fait partie de ses compĂ©tences, l’objectif de l’administration est de proposer une machine qui ne consomme « que » vingt mĂ©gawatts (un rĂ©acteur nuclĂ©aire produit gĂ©nĂ©ralement mille mĂ©gawatts). Erik DeBenedictis voit trois technologies pour rĂ©duire la consommation du facteur cinquante demandĂ© : des transistors opĂ©rant Ă une tension d’un millivolt, la mĂ©moire 3D et les processeurs spĂ©cialisĂ©s.
En thĂ©orie, un transistor peut fonctionner avec des tensions bien plus faibles qu’actuellement, en passant d’un volt Ă quelques millivolts Ă peine, ce qui augmenterait l’efficacitĂ© Ă©nergĂ©tique des processeurs d’un facteur dix Ă cent Ă court terme (jusqu’Ă dix mille Ă plus long terme !). La diminution de tension a jusqu’Ă prĂ©sent suivi la loi de Moore, suivant la taille des transistors ; cependant, elle est bloquĂ©e depuis une dĂ©cennie au niveau du volt… mais personne ne sait comment y arriver. Plusieurs technologies pourraient nĂ©anmoins passer cette barre :
- les transistors FET Ă tunnel ;
- les technologies MEMS, avec des interrupteurs électromécaniques nanométriques ;
- la nanophotonique, qui exploiterait de la lumière pour transmettre l’information ;
- la nanomagnétique, avec des champs magnétiques qui pourraient créer des circuits non volatils.
Les mĂ©moires empilĂ©es (aussi dites « en trois dimensions ») sont d’ores et dĂ©jĂ en cours de dĂ©ploiement, sous des noms comme HBM ou HMC, dans les processeurs graphiques haut de gamme ou des accĂ©lĂ©rateurs spĂ©cifiquement prĂ©vus pour le calcul scientifique. Ils permettent une grande rĂ©duction de la consommation Ă©nergĂ©tique, d’autant plus enviable que l’objectif de vingt mĂ©gawatts rĂ©serve un tiers de la consommation Ă la mĂ©moire. Une autre piste serait d’abandonner autant que possible la mĂ©moire non volatile, pour passer par exemple Ă la mĂ©moire rĂ©sistive, comme la technologie Octane d’Intel.
Le troisième axe de recherche propose d’exploiter des architectures beaucoup plus spĂ©cifiques aux problèmes Ă rĂ©soudre. Elle est dĂ©jĂ exploitĂ©e, puisqu’une bonne partie des superordinateurs les plus puissants utilisent des processeurs graphiques. Cependant, Erik DeBenedictis propose de pousser l’idĂ©e plus loin encore : installer des processeurs extrĂŞmement spĂ©cifiques aux tâches Ă rĂ©aliser, qui seraient activĂ©s seulement quand ils sont nĂ©cessaires. Pour effectuer d’autres types de calculs sur l’ordinateur, il faudrait alors installer d’autres processeurs spĂ©cialisĂ©s, ce qui n’est plus dĂ©raisonnable actuellement, au vu du prix des puces spĂ©cialisĂ©es.
Des compromis à réaliser
Ces trois pistes ont l’air intĂ©ressantes, mais n’ont pas du tout les mĂŞmes propriĂ©tĂ©s quant au modèle de programmation actuel : si la physique derrière les processeurs change complètement, ils restent programmables de la mĂŞme manière ; par contre, pour exploiter efficacement de nouveaux processeurs spĂ©cialisĂ©s, il faudrait changer complètement sa manière de pensĂ©e. La mĂ©moire est dans une situation intermĂ©diaire : empilĂ©e sur le processeur, les dĂ©lais d’accès changent radicalement, l’ancien code n’est donc plus aussi efficace s’il tirait parti de ces spĂ©cificitĂ©s, mais continuera Ă fonctionner ; au contraire, pour la mĂ©moire rĂ©sistive, il n’y aurait plus de distinction entre la mĂ©moire utilisĂ©e pour effectuer les calculs et celle pour le stockage Ă long terme.
Sources : Three paths to exascale supercomputing (paru en ligne sous le titre Power problems threaten to strangle exascale computing), FLOPS.
Merci Ă Claude Leloup pour ses corrections.