zlib est une bibliothèque de compression très largement utilisĂ©e dans bon nombre d’applications : les consoles de jeu les plus rĂ©centes (Playstation 3 et 4, Xbox 360 et One, notamment), mais aussi le noyau Linux, les systèmes de gestion des versions comme SVN ou Git ou le format d’image PNG. Sa première version publique a Ă©tĂ© publiĂ©e en 1995 par Jean-Loup Gailly et Mark Adler en implĂ©mentant la technique DEFLATE. Son succès est notamment dĂ» Ă l’absence de brevets logiciels (ce qui a principalement un intĂ©rĂŞt aux États-Unis) sur ses algorithmes, mais aussi Ă des dĂ©bits en compression et dĂ©compression relativement Ă©levĂ©s pour une utilisation en ressources assez faible et un bon taux de compression.
Fonctionnement de zlib
Au niveau algorithmique, DEFLATE utilise des techniques Ă©prouvĂ©es des annĂ©es 1990, principalement un dictionnaire (selon l’algorithme LZ77) et un codage de Huffman. Le principe d’un dictionnaire est de trouver des sĂ©quences de mots rĂ©pĂ©tĂ©es dans le fichier Ă compresser et de les remplacer par un index dans un dictionnaire. Le codage de Huffman fonctionne avec un arbre pour associer des codes courts Ă des sĂ©quences de bits très frĂ©quentes. Ces deux techniques s’associent pour former la technique de compression standard actuelle.
Concurrents modernes
Cependant, depuis le dĂ©veloppement de ces techniques, la recherche au niveau de la compression sans perte a fait de grands progrès. Par exemple, LZMA (l’algorithme derrière 7-Zip et XZ) exploite des idĂ©es similaires (plus la probabilitĂ© de retrouver des suites de bits dans le fichier Ă compresser, plus la manière compressĂ©e de l’Ă©crire doit ĂŞtre courte), mais avec une dĂ©pendance entre diffĂ©rentes sĂ©quences de bits (chaĂ®ne de Markov), ainsi qu’un codage arithmĂ©tique. Le rĂ©sultat est un taux de compression souvent bien meilleur que DEFLATE, mais le processus de compression est bien plus lent, tout en gardant une dĂ©compression rapide et sans besoins extravagants en mĂ©moire. LZHAM est aussi basĂ© sur les mĂŞmes principes avec des amĂ©liorations plus modernes et vise principalement une bonne vitesse de dĂ©compression (au dĂ©triment de la compression).
Cependant, pour un usage plus courant, les dĂ©bits en compression et dĂ©compression sont aussi importants l’un que l’autre, avec un aussi bon taux de compression que possible. Par exemple, pour des pages Web d’un site dynamique, le serveur doit compresser chaque page indĂ©pendamment, puisque le contenu varie d’un utilisateur Ă l’autre. Plusieurs bibliothèques de compression sont en lice, comme LZ4 (qui se propose comme une bibliothèque très gĂ©nĂ©raliste, comme zlib, mais très rapide en compression et dĂ©compression), Brotli (proposĂ© par Google pour un usage sur le Web) ou encore BitKnit (proposĂ© par RAD pour la compression de paquets rĂ©seau — cette bibliothèque est la seule non libre dans cette courte liste). Ces deux dernières se distinguent par leur âge : elles ont toutes deux Ă©tĂ© annoncĂ©es en janvier 2016, ce qui est très rĂ©cent.
Une première comparaison concerne la quantité de code de chacune de ces bibliothèques : avec les années, zlib a accumulé pas loin de vingt-cinq mille lignes de code (dont trois mille en assembleur), largement dépassé par Brotli (pas loin de cinquante mille lignes, dont une bonne partie de tables précalculées). Les deux derniers, en comparaison, sont très petits : trois mille lignes pour LZ4 ou deux mille sept cents pour BitKnit (en incluant les commentaires, contrairement aux autres !).
Tentative de comparaison
Rich Geldreich, spĂ©cialiste de la compression sans perte et dĂ©veloppeur de LZHAM, propose une mĂ©thodologie pour comparer ces bibliothèques : au lieu d’utiliser un jeu de donnĂ©es standard mais sans grande variĂ©tĂ© (comme un extrait de Wikipedia, c’est-Ă -dire du texte en anglais sous la forme de XML), il propose un corpus de plusieurs milliers de fichiers (ce qui n’a rien de nouveau, Squash procĂ©dant de la mĂŞme manière) et prĂ©sente les rĂ©sultats de manière graphique. Cette visualisation donne un autre aperçu des diffĂ©rentes bibliothèques.
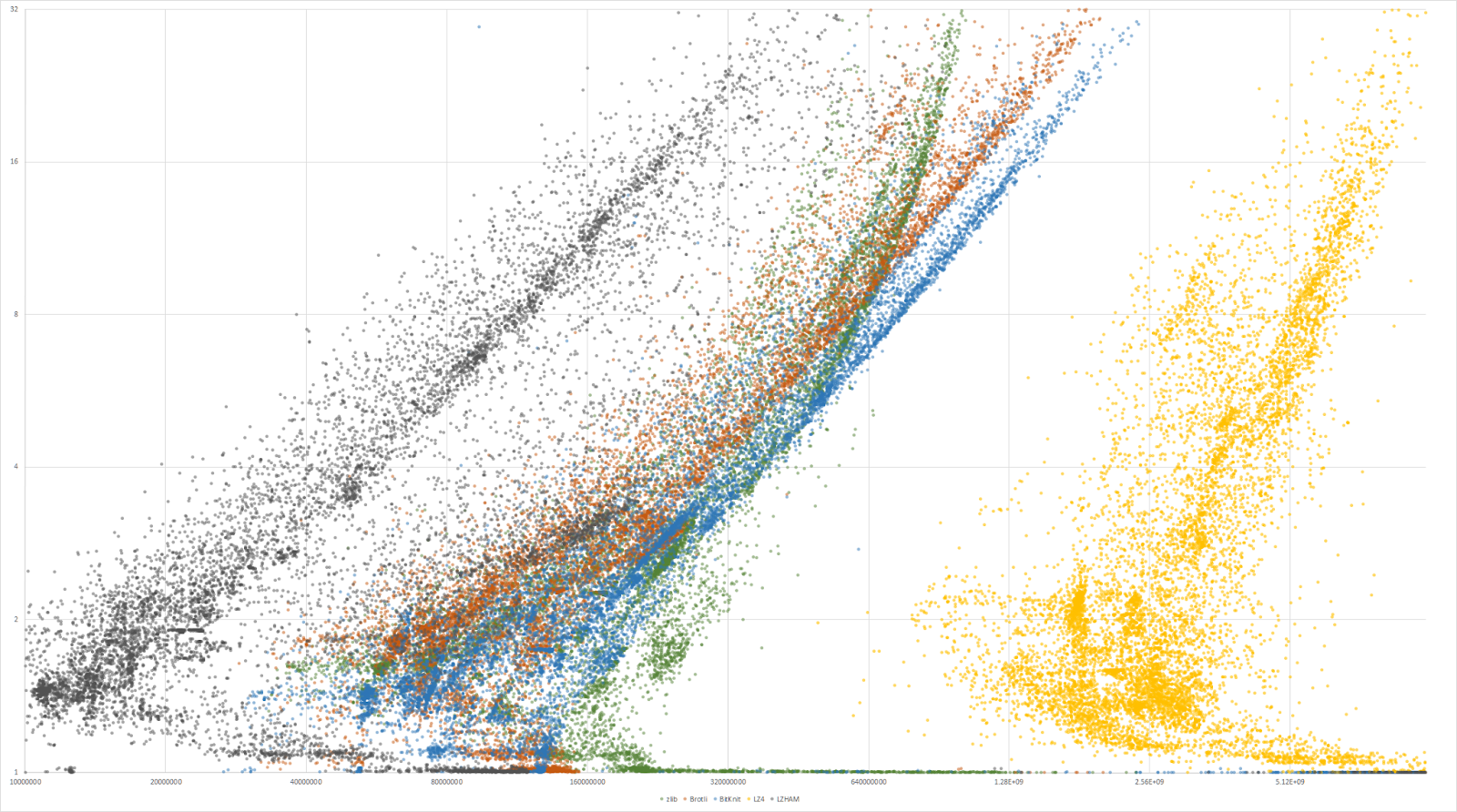
Ce graphique montre, sur l’axe horizontal (logarithmique), les dĂ©bits en dĂ©compression (plus un point est Ă droite, plus la dĂ©compression est rapide) et, sur l’axe vertical (logarithmique aussi), le taux de compression (plus il est Ă©levĂ©, plus le fichier a Ă©tĂ© rĂ©duit en taille). Chaque couleur correspond Ă un algorithme : vert pour zlib, noir pour LZHAM, rouge pour Brotli, bleu pour BitKnit et jaune pour LZ4.
Deux nuages de points sortent du lot : LZ4, tout Ă droite, est extrĂŞmement rapide en dĂ©compression, tout l’opposĂ© de LZHAM, qui propose nĂ©anmoins de bien meilleurs taux de compression. zlib montre un comportement assez Ă©trange : le dĂ©bit de dĂ©compression n’augmente plus Ă partir d’un certain point, contrairement aux autres bibliothèques. L’auteur propose des comparaisons plus spĂ©cifiques des taux de compression de chaque bibliothèque en fonction des fichiers.
Et donc ?
Cette comparaison montre que les diffĂ©rentes bibliothèques ne sont pas toujours meilleures les unes que les autres, tout dĂ©pend du contenu du fichier, de sa taille, des ressemblances par rapport aux estimations des concepteurs (plus particulièrement dans le cas d’algorithmes qui ne s’adaptent pas dynamiquement au contenu et prĂ©fèrent utiliser des tables prĂ©dĂ©finies, ce qui Ă©vite de transmettre une sĂ©rie d’informations).
Notamment, Brotli est prĂ©vu pour le Web : il fonctionne particulièrement bien sur des donnĂ©es textuelles. Tout comme zlib, il utilise des tables prĂ©calculĂ©es, ce qui lui donne un avantage sur des fichiers plus petits. Au contraire, BitKnit fonctionne très bien sur du contenu binaire, bien plus courant pour les donnĂ©es de jeux vidĂ©o. Ces deux bibliothèques ont donc chacune leurs points forts selon les domaines d’application prĂ©vus et y sont meilleures que zlib.
Sources : zlib in serious danger of becoming obsolete.