AMD tente depuis quelques mois de redorer son blason par la communication, avec un retour dans le monde du HPC suivi du projet GPUOpen. Faisant suite ├Ā des ann├®es de recherche et d├®veloppement, le groupe vient d’annoncer sa nouvelle architecture pour les processeurs graphiques (principalement pour la gamme Radeon, puis pour les APU des s├®ries A, C et E), d├®nomm├®e Polaris.
Ce nom de code a ├®t├® choisi en r├®f├®rence aux ├®toiles : l’├®toile polaire (Polaris en latin) est la plus brillante de la constellation de la Petite Ourse. AMD indique que cette architecture proposera un saut historique en performance par watt consomm├®, tout comme les ├®toiles sont des processus extr├¬mement efficaces pour g├®n├®rer de la lumi├©re. De fait, l’objectif affich├® est de multiplier la performance par watt consomm├® par un facteur de deux et demi ŌĆö l├Ā o├╣ NVIDIA propose un saut d’un facteur deux avec son architecture Pascal, sachant qu’ils partent de puces moins gourmandes qu’AMD.

Une affaire de FinFET
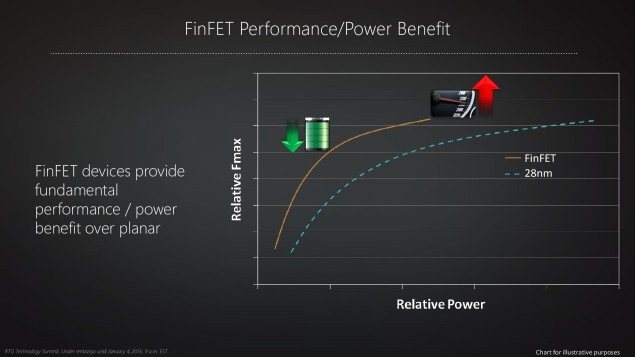
Ce saut est en bonne partie d├╗ au changement de technologie pour la gravure des puces, c’est-├Ā-dire leur r├®alisation effective ├Ā partir de silicium : la r├®solution de la lithographie sur le semiconducteur passe de vingt-huit nanom├©tres ├Ā quatorze et les transistors sont r├®alis├®s en trois dimensions plut├┤t que deux (FinFET). En d’autres termes, les transistors des nouveaux GPU seront beaucoup plus petits et consommeront moins d’├®nergie ŌĆö et pourront fonctionner ├Ā une fr├®quence plus ├®lev├®e. (Dans le m├¬me temps, NVIDIA fait le m├¬me changement de processus de fabrication.)

De plus, pour continuer ├Ā am├®liorer la performance et l’efficacit├® ├®nerg├®tique, AMD a impl├®ment├® une s├®rie de nouvelles fonctionnalit├®s, comme un ordonnanceur de t├óches au niveau du GPU (et non seulement pour le pilote du c├┤t├® du syst├©me d’exploitation), la pr├®lecture des instructions ├Ā effectuer ou encore la compression des donn├®es lues en m├®moire. Cette pr├®lecture est une fonctionnalit├® qui se trouve depuis longtemps dans les processeurs traditionnels (CPU) pour limiter les temps d’attente de la m├®moire, mais relativement complexe ├Ā g├®rer ; elle arrive maintenant dans les processeurs graphiques (GPU), ce qui montre ├Ā quel point ces processeurs deviennent eux aussi extr├¬mement compliqu├®s dans leur conception.
Beaucoup de nouveaut├®sŌĆ” pas encore vraiment divulgu├®es
En r├®alit├®, cette gestion de la m├®moire n’est qu’un des nouveaux ├®l├®ments de cette nouvelle architecture : dans une description fonctionnelle de ces nouveaux GPU, ├®norm├®ment de blocs sont nouveaux ou fortement retravaill├®s, notamment avec un contr├┤leur m├®moire plus costaud. Selon la gamme de prix, la m├®moire embarqu├®e devrait ├¬tre de type GDDR5 (comme la plupart des GPU actuels) ou HBM (avec une bande passante sup├®rieure).
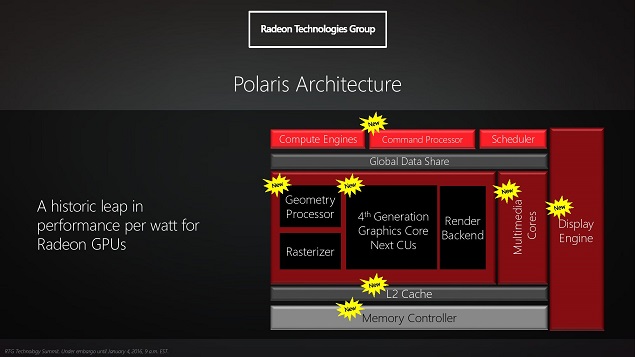
De m├¬me, de nouvelles technologies devraient ├¬tre incluses, comme DisplayPort 1.3 et HDMI 2.0a pour la connectique ou un codec H.265 (aussi connu comme HEVC) pouvant fonctionner ├Ā soixante images par seconde en r├®solution 4K, tant en encodage qu’en lecture. AMD aimerait ├®galement ├®largir le public utilisant des ├®crans ├Ā large gamut, avec une gestion native des couleurs cod├®es sur dix bits (au lieu des huit habituels) ŌĆö y compris pour le codec HEVC.

Cependant, AMD reste relativement silencieux quant aux d├®tails de ces blocs, plus devant ├¬tre r├®v├®l├® ├Ā proximit├® de la sortie effective de ces produits, pr├®vue pour la mi-2016 (les plans de NVIDIA semblent indiquer que la concurrence sera rude ├Ā ce moment, leur architecture Pascal ├®tant ├®galement pr├®vue dans ces eaux-l├Ā).
Sources : AMD Announces Polaris, 2016 Radeon Graphics Architecture To Bring A Historic Leap In Perf/Watt With 14nm / 16nm FinFET Process, AMD Reveals Polaris GPU Architecture: 4th Gen GCN to Arrive In Mid-2016.