
A couple of weeks, I read an article from Brent Ozar about using NVARCHAR as a universal parameter. It was a good reminder and from my experience, I confirm this habit has never been a good idea. Although it depends on the context, chances are you will almost find an exception that proves the rule.
A couple of days ago, I felt into a situation that illustrated perfectly this issue, and, in this blog, I decided to share my experience and demonstrate how the impact may be in a real production scenario.
So, let’s start with the culprit. I voluntary masked some contextual information but the principal is here. The query is pretty simple:
DECLARE @P1 INT
DECLARE @P2 NVARCHAR(4000)
DECLARE @P3 DATETIME
DECLARE @P4 NVARCHAR(4000)
UPDATE TABLE SET DATE = @P0
WHERE ID = @P1
AND IDENTIFIER = @P2
AND P_DATE >= @P3
AND W_O_ID = (
SELECT TOP 1 ID FROM TABLE2
WHERE Identifier = @P4
ORDER BY ID DESC)
And the corresponding execution plan:
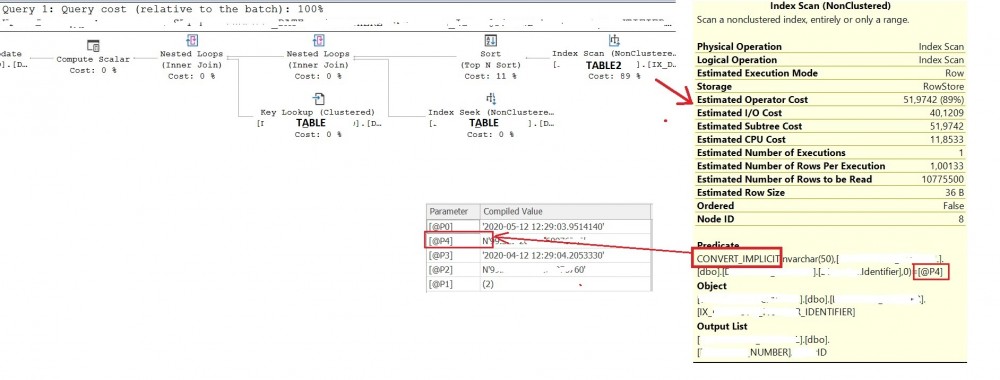
The most interesting part concerns the TABLE2 table. As you may notice the @P4 input parameter type is NVARCHAR and it is evident we get a CONVERT_IMPLICIT in the concerned Predicate section above. The CONVERT_IMPLICIT function is required because of data type precedence. It results to a costly operator that will scan all the data from TABLE2. As you probably know, CONVERT_IMPLICT prevents sargable condition and normally this is something we could expect here referring to the distribution value in the statistic histogram and the underlying index on the Identifier column.

WITH HISTOGRAM;
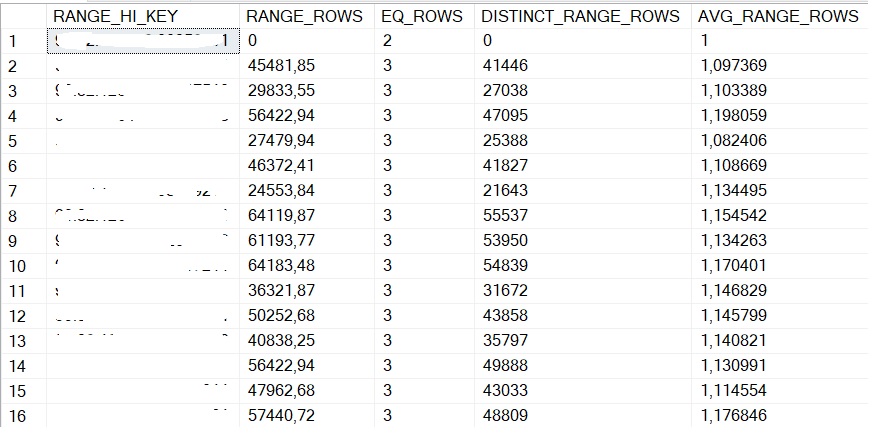
Another important point to keep in mind is that scanning all the data from the TABLE 2 table may be at a certain cost (> 1GB) even if data resides in memory.

The execution plan warning confirms the potential overhead of retrieving few rows in the TABLE2 table:

To set a little bit more the context, the concerned application queries are mainly based on JDBC Prepared statements which imply using NVARCHAR(4000) with string parameters regardless the column type in the database (VARCHAR / NVARCHAR). This is at least what we noticed from during my investigations.
So, what? Well, in our DEV environment the impact was imperceptible, and we had interesting discussions with the DEV team on this topic and we basically need to improve the awareness and the visibility on this field. (Another discussion and probably another blog post) …
But chances are your PROD environment will tell you a different story when it comes a bigger workload and concurrent query executions. In my context, from an infrastructure standpoint, the symptom was an abnormal increase of the CPU consumption a couple of days ago. Usually, the CPU consumption was roughly 20% up to 30% and in fact, the issue was around for a longer period, but we didn’t catch it due to a « normal » CPU footprint on this server.
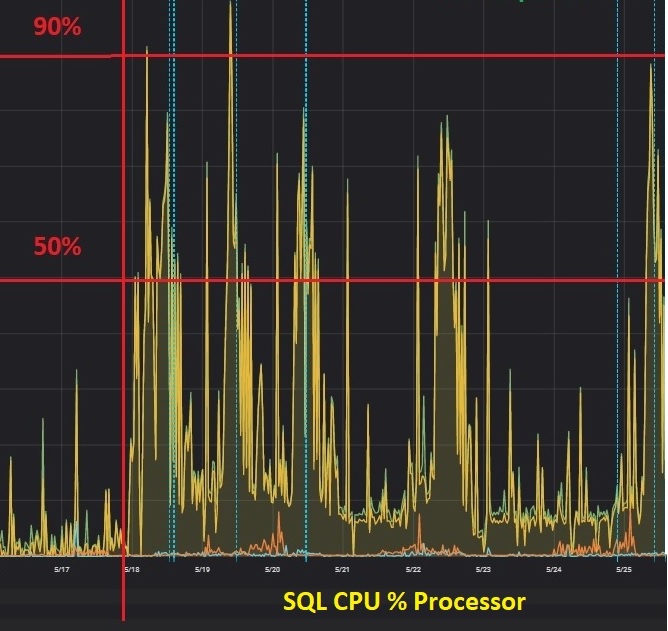
So, what happened here? We’re using SQL Server 2017 with Query Store enabled on the concerned database. This feature came to the rescue and brought attention to the first clue: A query plan regression that led increasing IO consumption in the second case (and implicitly the additional CPU resource consumption as well).
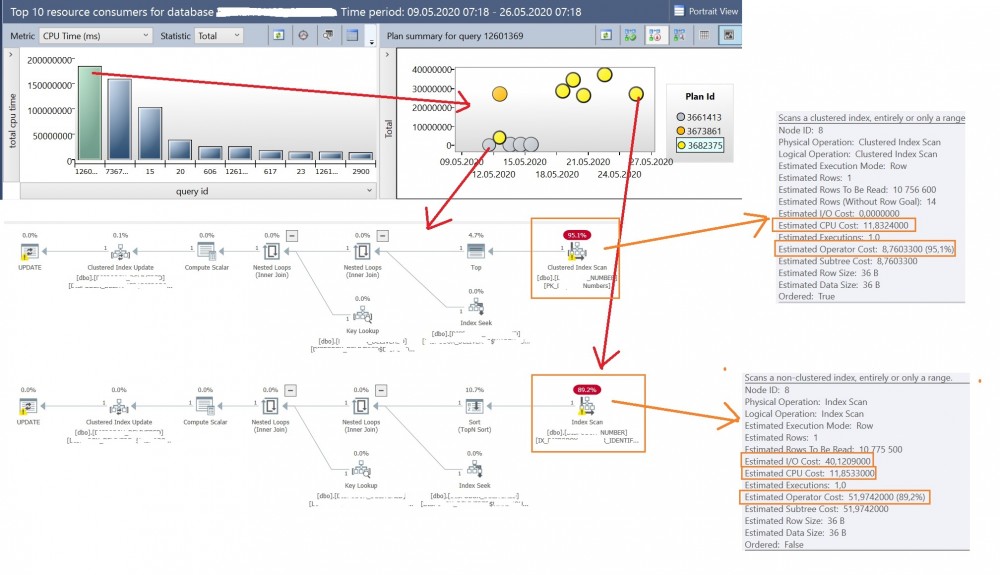
You have probably noticed both the execution plans are using an index scan at the right but the more expensive one (at the bottom) uses a different index strategy. Instead of using the primary key and clustered index (PK_xxx), a non-clustered index on the IX_xxx_Identifier column in the second query execution plan is used with the same CONVERT_IMPLICIT issue.
According to the query store statistics, number of executions per business day is roughly 25000 executions with ~ 8.5H of CPU time consumed during this period (18.05.2020 – 26.05.2020) that was a very different order of magnitude compared to what we may have in the DEV environment ![]()
At this stage, I would say investigating why a plan regression occurred doesn’t really matter because in both cases the most expensive operator concerns an index scan and again, we expect an index seek. Getting rid of the implicit conversion by using VARCHAR type to make the conditional clause sargable was a better option for us. Thus, the execution plan would be:

The first workaround in mind was to force the better plan in the query store (automatic tuning with FORCE_LAST_GOOD_PLAN = ON is disabled) but having discussed this point with the DEV team, we managed to deploy a fix very fast to address this issue and to reduce drastically the CPU consumption on this SQL Server instance as shown below. The picture is self-explanatory:
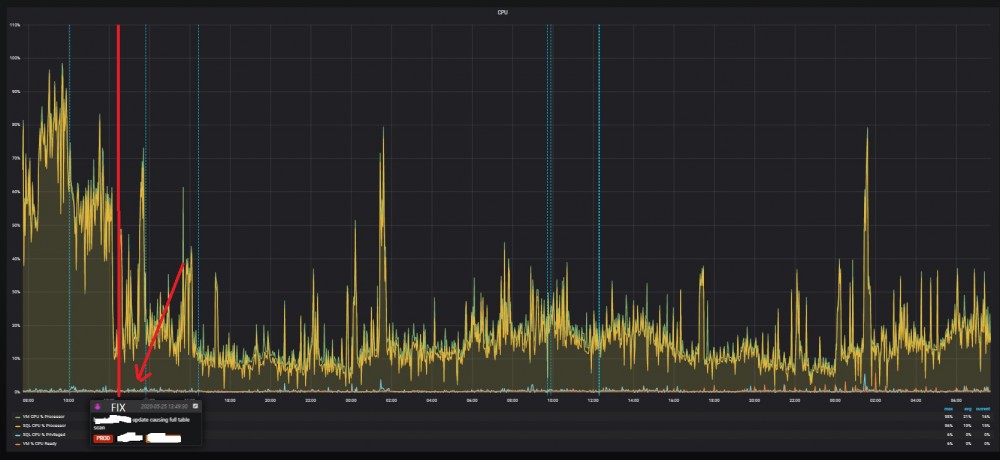
The fix consisted in adding CAST / CONVERT function to the right side of the equality (parameter and not the column) to avoid side effect on the JDBC driver. Therefore, we get another version of the query and a different query hash as well. The query update is pretty similar to the following one:
DECLARE @P1 INT
DECLARE @P2 NVARCHAR(4000)
DECLARE @P3 DATETIME
DECLARE @P4 NVARCHAR(4000)
UPDATE TABLE SET DATE = @P0
WHERE ID = @P1
AND IDENTIFIER = CAST(@P2 AS varchar(50))
AND P_DATE >= @P3
AND W_O_ID = (
SELECT TOP 1 ID FROM TABLE2
WHERE Identifier = CAST(@P4 AS varchar(50))
ORDER BY ID DESC)
Sometime later, we gathered query store statistics of both the former and new query to confirm the performance improvement as shown below:

Finally changing the data type led to enable using an index seek operator to reduce drastically the SQL Server CPU consumption and logical read operations by far.
QED!
Ping : 1variegated