Cet article est la traduction d’un article de Cary Millsap publiĂ© sur son blog. L’article original en anglais est:Throughput versus Response Time. C’est un commentaire sur l’article de Doug Burns Time Matters: Throughput vs. Response Time. Cary Millsap est un spĂ©cialiste de la performance, du tuning Oracle et a beaucoup Ă©crit sur les files d’attentes.
J’ai apprĂ©ciĂ© le post de Doug Burns Performance: Mesurer le temps de rĂ©ponse ou le dĂ©bit sur son blog. Si vous ne l’avez pas encore lu, vous devriez. L’article et les commentaires sont excellents.
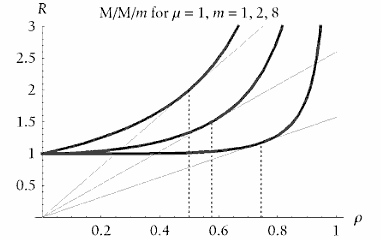
La courbe de rendement (temps de rĂ©ponse en fonction de la charge du système) fait un coude, au point oĂą le temps de rĂ©ponse, presque constant, devient tout d’un coup exponentiel lorsque le système atteint une certaine charge.
Exemple de courbe de rendement tiré de Optimizing Oracle performance
– En abscisse (ρ): la charge (ou utilisation),
– En ordonnĂ©e (R): le temps de rĂ©ponse.
– Les 3 courbes correspondent Ă un degrĂ© de parallĂ©lisme de 1,2 et 8
Le ‘coude’ (‘knee‘), est le point correspondant Ă la charge pour laquelle le rapport temps de rĂ©ponse / utilisation est minimal.
Il peut ĂŞtre dĂ©terminĂ© aussi par la tangente Ă la courbe, passant par le point d’origine des axes.
Ce ‘coude’ se dĂ©cale vers la droite lorsque le degrĂ© de parallĂ©lisme augmente.
Ce que Doug a observĂ©, c’est le fait que ce coude est le point oĂą le rapport temps de rĂ©ponse/dĂ©bit est minimal. C’est ce rapport qui est important ici. Ce n’est pas le point oĂą le temps de rĂ©ponse est le plus rapide. Parce ce que, comme Doug l’a fait remarquer, ce point serait lĂ oĂą il n’y a pas d’autre charge en dehors de la votre sur le système … ce qui est formidable pour vous, mais pas si bon pour les affaires.
Je voudrais insister sur quelques points.
Batch ou transactionnel.
Tout d’abord, les exigences de performance sont complètement diffĂ©rentes pour du batch (traitement par lots, de nuit, ‘offline‘,…) ou pour de l’interactif (IHM, GUI, ‘online‘, transactionnel,…), comme l’on notĂ© plusieurs commentaires sur le post de Doug.
Pour les batch, les gens cherchent normalement à avoir le débit maximum(throughput).
Avec un programmes interactif, les individus se soucient surtout de leur propre temps de rĂ©ponse, et non pas du dĂ©bit global de l’ensemble des utilisateurs. MĂŞme si les managers de ces personnes, eux, vont se soucier du dĂ©bit gĂ©nĂ©ral. Les individus se prĂ©occupent sans doute du dĂ©bit du groupe aussi, mais pas au point de rester travailler plus tard quand leurs tâches individuelles s’exĂ©cutent si lentement qu’ils ne peuvent pas les achever au cours de la journĂ©e de travail.
Il n’y a pas que les exigences de performance qui sont diffĂ©rentes pour un batch, mais l’ordonnancement des batch va ĂŞtre diffĂ©rent aussi. Si vous ĂŞtes chanceux, vous pouvez planifier votre charge batch de manière dĂ©terministe. Par exemple, vous pouvez peut-ĂŞtre employer un Workload Manager qui alimente la charge du système au compte goutte, en maintenant l’utilisation du système Ă 100% tout en faisant en sorte que la file d’attente (runqueue) ne dĂ©passe pas 1. Mais les charges du transactionnel (online) sont presque toujours non-dĂ©terministes , ce qui veut dire qu’on ne peut pas les planifier du tout. C’est pour cette raison que vous devez garder Ă portĂ©e de main une marge de ressource inutilisĂ©e. Parce que sinon la charge du système va dĂ©passer le point oĂą la courbe fait ce coude exponentiel. Et alors, mĂŞme si l’augmentation de charge est microscopique, le temps de rĂ©ponse utilisateur va augmenter exponentiellement, ce qui entraĂ®ne douleurs et de souffrances…
Le profiling.
Le deuxième point que je veux aborder, et qui Ă mon avis n’est souvent pas très bien compris: Il est essentiel, mĂŞme lorsqu’on cherche Ă optimiser le dĂ©bit, de s’interresser aux temps de rĂ©ponses individuels, comme dans le profiling, en isolant une unitĂ© de tâche fonctionnelle particulière. Il y a de bonnes pratiques pour rendre une tâche plus rapide, et il y en a aussi de mauvaises.
- Les bonne pratiques sont celles qui cherchent Ă Ă©liminer de la tâche tout le travail inutile, sans que cela ne cause des effets secondaires nĂ©gatifs sur les autres tâches (sur celles que vous n’ĂŞtes pas en train d’analyser aujourd’hui).
- Les mauvaises pratiques, elles, vont dĂ©grader accidentellement les performances des autres tâches, de celles que vous ĂŞtes en train d’analyser.
Si vous restez dans les bonnes pratiques, vous ne verrez pas l’effet ‘en dents de scie’ auquel on pense souvent lorsqu’on parle d’optimiser une tâche Ă la fois. Vous savez: l’idĂ©e qu’en amĂ©liorant une unitĂ© de tâche A, on va dĂ©grader une autre unitĂ© de tâche B, et que lorsqu’on va faire le tuning de B, on va casser Ă nouveau ce qui a Ă©tĂ© fait sur A. Ces rĂ©sultats en dents de scie vont arriver lorsqu’on essaie de rĂ©soudre des problèmes de performance en modifiant des paramètres systèmes qui ont une portĂ©e globale. Par contre, si l’on essaie d’Ă©liminer le travail inutile, alors le bĂ©nĂ©fice est partagĂ©, parce qu’il va permettre aux tâches concurrentes de s’exĂ©cuter plus vite aussi, puisque la tâche que vous avez optimisĂ© utilise maintenant moins de ressources. Cela va permettre Ă tout le reste d’accĂ©der plus simplement, et Ă un moindre coĂ»t, aux ressources nĂ©cessaires, sans avoir Ă ĂŞtre en file d’attente (queue) pour les obtenir.
C’est lĂ que les choses sĂ©rieuses commencent: lorsqu’on essaie de comprendre comment Ă©liminer ce travail inutile.
Une grande partie des tâches que nous voyons peuvent souvent s’amĂ©liorer en changeant juste quelques lignes de code. Par exemple la requĂŞte qui ne consomme plus que 9098 latches au lieu de 2142103, des choses comme ça (rĂ©fĂ©rence Ă cet article en anglais).
Et beaucoup d’autres tâches s’amĂ©liorent simplement en faisant une collecte de statistiques (analyze ou plutĂ´t dbms_stats) correcte (rĂ©fĂ©rence Ă cet article de Karen Morton en anglais).
D’autres fois cela nĂ©cessite un ajustement de la stratĂ©gie d’indexation, ce qui peut paraĂ®tre complexe lorsque vous avez besoin d’optimiser un tout un ensemble de requĂŞtes SQL (c’est lĂ qu’il y a une possibilitĂ© de dents de scie). Mais mĂŞme cela est plus ou moins un problème rĂ©solu si vous comprenez le travail de Tapio Lahdenmäki
Mais revenons Ă l’idĂ©e de dĂ©part de l’article de Doug: je trouve tout a fait normal de vouloir optimiser Ă la fois le dĂ©bit (throughput) et temps de rĂ©ponse. C’est la maĂ®trise d’ouvrage, le mĂ©tier, doit dĂ©cider du bon compromis. Et je suis persuadĂ© que si vous voulez avoir un quelconque espoir d’optimiser quoi que ce soit (temps de rĂ©ponse ou dĂ©bit), il est essentiel de se concentrer sur cette Ă©limination du travail inutile, individuellement pour chacune des tâches qui tournent en parallèle.
On peut voir cela de la manière suivante. Une tâche ne peut fonctionner Ă sa vitesse optimale que si elle est efficace. Vous ne pouvez pas savoir si une tâche est efficace sans avoir mesurĂ© sa durĂ©e. Et je veux dire avoir mesurĂ© la durĂ©e de cette tâche prĂ©cisĂ©ment, pas seulement une partie de cette tâche, ni l’ensemble de cette tâche avec d’autres autour d’elle. C’est cela le profiling: la mesure d’une tâche prĂ©cise, afin de dĂ©terminer exactement oĂą elle passe son temps, et donc de savoir si cette tâche dĂ©pense efficacement le temps système et les ressources qu’elle utilise.
Vous pouvez amĂ©liorer un système sans profiling, et mĂŞme peut-ĂŞtre le rendre optimal. Mais sans savoir si ses tâches sont efficaces, vous ne saurez jamais si le système est optimal. Et sans faire du profiling, vous ne saurez pas si une tâche donnĂ©e est efficace. Et dans ce cas, vous perdez du temps et d’argent. C’est pourquoi j’insiste sur le fait que le profiling d’une tâche individuelle est absolument indispensable Ă quiconque veut optimiser les performances.
Optimizing Oracle Performance
Par Cary Millsap et Jeff Holt
Plusieurs points évoqués ici sont détaillés dans ce livre:
Courbe de rendement, profiling, thĂ©orie des files d’attentes,…
