octobre
2012
 Un article de ora_home
Un article de ora_home


Par : Zakaria EL HAMDAOUI
Administrateur base de données
Consultant et formateur Oracle
elhamdaoui_zakaria@yahoo.fr
1. Modes de fonctionnement de l’optimiseur
• Optimisation basée sur les règles
Lorsque ce mode de fonctionnement est utilisé, le processus serveur détermine son chemin d’accès aux données en examinant l’interrogation. L’optimiseur classe les chemins d’accès grâce au jeu de règles complet dont il dispose. Le plus souvent, les développeurs Oracle expérimentés maîtrisent parfaitement ces règles et règlent leur code SQL en conséquence. L’optimiseur basé sur les règles est orienté syntaxe : il utilise la syntaxe des instructions ainsi que les informations du dictionnaire de données sur les structures de données pour déterminer son plan d’exécution. Ce mode de fonctionnement de l’optimiseur est pris en charge pour des raisons de compatibilité avec les versions antérieures du serveur Oracle.
• Optimisation basée sur le coût
Dans ce mode de fonctionnement, l’optimiseur examine chaque instruction et identifie tous les chemins d’accès possibles aux données. Il évalue ensuite le coût en ressources de chaque chemin d’accès et choisit celui qui consomme le moins de ressources. Le nombre de lectures logiques est l’élément déterminant dans l’évaluation du coût. L’optimiseur basé sur le coût est orienté statistiques : il détermine le plan d’exécution approprié à l’aide des statistiques générées pour les objets impliqués dans les instructions SQL. Il est utilisé si des statistiques ont été générées pour un objet contenu dans l’instruction SQL. Ce mode de fonctionnement est recommandé pour les nouvelles applications, surtout si elles utilisent la fonctionnalité Parallel Query, les index bitmap ou les index de jointure bitmap.
2. Définir le mode de fonctionnement de l’optimiseur
Vous pouvez définir le mode de fonctionnement de l’optimiseur au niveau :
• de l’instance, à l’aide du paramètre OPTIMIZER_MODE, optimizer_mode =
{choose|rule|first_rows|first_rows_n|all_rows}
• de la session, à l’aide de la commande ALTER SESSION,
alter session set optimizer_mode = {choose|rule|first_rows|first_rows_n|all_rows}
• de l’instruction, grâce aux conseils (Hints). Utilisez des conseils
Le DBA est chargé de la définition du paramètre OPTIMIZER_MODE au niveau de l’instance, car cette opération nécessite le redémarrage de celle-ci. En règle générale, les développeurs d’applications peuvent définir le paramètre OPTIMIZER_MODE au niveau de la session et utiliser des conseils dans les instructions SQL.
Paramètre OPTIMIZER_MODE
La valeur par défaut de ce paramètre est CHOOSE. Cela signifie que l’optimiseur utilise le mode de fonctionnement basé sur le coût (ALL_ROWS) si des statistiques sont disponibles pour au moins l’une des tables concernées. Dans le cas contraire, il utilise l’optimisation basée sur les règles.
Remarque : Si l’une des tables concernées présente un degré d’exécution en parallèle supérieur à 1 ou un conseil parallèle, l’optimisation basée sur le coût est utilisée par défaut pour l’instruction.
Les autres valeurs possibles sont les suivantes : RULE, FIRST_ROWS, FIRST_ROWS_n et ALL_ROWS. La première impose l’optimisation basée sur les règles, qu’il existe ou non des statistiques. Les deux dernières représentent des méthodes différentes d’utilisation de l’optimisation basée sur le coût. FIRST_ROWS minimise le temps de réponse immédiat (éventuellement au détriment du temps de réponse global) et FIRST_ROWS_n minimise le temps de réponse immédiat pour les n premières lignes (éventuellement au détriment du temps de réponse global). La valeur de n peut être 1, 10, 100 ou 1000. ALL_ROWS minimise le temps de réponse global (débit).
• Option OPTIMIZER_MODE au niveau de la session
Les développeurs peuvent définir cette option à l’aide de la commande ALTER SESSION.
Remarque : Pour des raisons de compatibilité descendante, l’option OPTIMIZER_GOAL de la commande ALTER SESSION est toujours prise en charge comme alternative à l’option OPTIMIZER_MODE.
• Conseils de l’optimiseur
Vous pouvez utiliser des conseils de la manière suivante :
Les conseils qui ont une influence sur le mode de fonctionnement de l’optimiseur sont, entre autres, PARALLEL, RULE, FIRST_ROWS, FIRST_ROWS_n et ALL_ROWS.
Règles de priorité
Les conseils remplacent toujours les paramètres au niveau de la session et ces derniers remplacent toujours les paramètres au niveau de l’instance.
3. Stabilité du plan de l’optimiseur
Pour chaque instruction, l’optimiseur prépare une arborescence d’opérations appelée plan d’exécution, qui définit l’ordre et les méthodes des opérations que doit effectuer le serveur pour exécuter l’instruction.
Les informations dont dispose l’optimiseur peuvent être incomplètes. Par conséquent, il se peut qu’il ne choisisse pas le meilleur plan d’exécution. Dans ce cas, vous pouvez influencer la sélection du plan de l’optimiseur en réécrivant l’instruction SQL et en utilisant des conseils ou d’autres méthodes de réglage (tuning). Une fois cette opération terminée, vous pouvez vérifier si le plan ainsi réglé est généré à chaque fois qu’une même instruction est recompilée, même si certains facteurs affectant l’optimisation ont changé.
Oracle9i offre aux utilisateurs un moyen de stabiliser les plans d’exécution d’une version Oracle à une autre, lors de modifications de la base de données ou d’apparition d’autres facteurs entraînant normalement une modification du plan d’exécution. Vous pouvez créer un plan d’exécution prédéfini contenant un ensemble de conseils qui seront utilisés par l’optimiseur pour la création d’un plan d’exécution.
OPTIMIZER_FEATURES_ENABLE
Ce paramètre permet à une version du serveur Oracle d’utiliser les caractéristiques d’optimiseur basé sur le coût définies dans une précédente version. Il est préférable de conserver sa valeur par défaut, qui correspond à la version actuelle. Toutefois, le DBA peut conserver les précédentes caractéristiques d’optimiseur basé sur le coût au moment de la mise à niveau. Avant d’effectuer une telle opération, voir Oracle9i Performance Guide and Reference.
4. Equivalence des instructions SQL
Lorsque vous décidez d’appliquer un plan d’exécution prédéfini à une interrogation, la stabilité du plan repose sur une correspondance textuelle parfaite des interrogations. Les critères de correspondance sont les mêmes que ceux utilisés pour déterminer si un plan d’exécution de la zone de mémoire partagée peut être réutilisé.
Les plans d’exécution prédéfinis reposent partiellement sur les conseils utilisés par l’optimiseur pour générer des plans d’exécution stables. Par conséquent, le niveau d’équivalence des plans dépend des capacités des conseils utilisés par les plans. Les étapes d’un plan d’exécution prédéfini incluent les méthodes d’accès aux lignes, l’ordre et les méthodes de jointure, les accès distribués et la fusion vue/sous-interrogation. L’accès distribué n’inclut pas le plan d’exécution sur le noeud distant.
• Stabilité du plan
Ces plans restent cohérents et ne sont pas affectés par les différents types de modifications apportées aux instances et aux bases de données. Par conséquent, si vous développez des applications en vue d’une distribution de masse, vous pouvez utiliser des plans d’exécution prédéfinis pour garantir l’accès de tous vos clients aux mêmes plans d’exécution. Par exemple, si un schéma est modifié par l’ajout d’un index, le plan d’exécution prédéfini peut empêcher l’utilisation du nouvel index.
5. Créer des plans d’exécution prédéfinis
Le serveur peut créer automatiquement des plans d’exécution prédéfinis, mais vous pouvez également le faire pour des instructions SQL spécifiques. Les plans d’exécution prédéfinis utilisent l’optimiseur basé sur le coût, car ils reposent sur des conseils.
• Catégories
Les plans d’exécution prédéfinis peuvent être regroupés en catégories. Une même instruction SQL peut être associée à un plan d’exécution prédéfini dans plusieurs catégories. Par exemple, vous pouvez définir une catégorie OLTP et une catégorie DSS. Si le nom de la catégorie n’est pas précisé, les plans d’exécution prédéfinis sont placés dans la catégorie DEFAULT.
• Paramètre CREATE_STORED_OUTLINES
Lorsque vous affectez la valeur TRUE ou un nom de catégorie au paramètre CREATE_STORED_OUTLINES, Oracle crée automatiquement des plans d’exécution prédéfinis pour toutes les instructions SQL exécutées. Lorsque la valeur est TRUE, la catégorie utilisée est DEFAULT. Vous pouvez désactiver le processus en affectant la valeur FALSE au paramètre. Lorsque ce paramètre est utilisé, les noms de plan sont également générés automatiquement.
• Commande CREATE OUTLINE
Vous pouvez également créer des plans d’exécution prédéfinis pour une instruction spécifique à l’aide de la commande CREATE OUTLINE. L’un des avantages est que vous pouvez attribuer un nom au plan d’exécution prédéfini.
2 set CREATE_STORED_OUTLINES = train;
SQL> select … from … ;
SQL> select … from … ;
2 FOR CATEGORY train ON
3 select co.crs_id, ...
4 from courses co,
5 classes cl
6 where co.crs_id = cl.crs_id;
6. Utiliser les plans d’exécution prédéfinis
Si le paramètre USE_STORED_OUTLINES a la valeur TRUE, les plans d’exécution utilisés sont ceux de la catégorie DEFAULT. Si un nom de catégorie est affecté au paramètre USE_STORED_OUTLINES, les plans d’exécution utilisés sont ceux de cette catégorie. Si cette catégorie ne contient pas de plan d’exécution correspondant, celui contenu dans la catégorie DEFAULT, le cas échéant, est utilisé.
Le texte de l’instruction doit être identique à celui de l’instruction figurant dans le plan d’exécution prédéfini. Une comparaison est effectuée à l’aide de la méthode de comparaison de curseurs dans la zone de mémoire partagée. Les conseils inclus dans le plan d’exécution prédéfini doivent donc être utilisés dans le texte de l’instruction, afin que la correspondance soit établie. Les valeurs des variables attachées (bind variables) ne doivent pas obligatoirement être identiques.
Pour définir le plan d’exécution d’une instruction SQL, Oracle9i utilise la logique suivante :
• L’instruction est comparée aux instructions qui se trouvent dans la zone de mémoire partagée afin de vérifier la concordance du texte et la catégorie du plan d’exécution prédéfini.
• En l’absence d’instruction concordante, le serveur interroge le dictionnaire de données, afin de rechercher un plan d’exécution prédéfini correspondant.
• S’il trouve un plan d’exécution prédéfini concordant, Oracle9i l’intègre à l’instruction et crée le plan d’exécution.
• S’il ne trouve aucun plan d’exécution prédéfini, l’instruction est exécutée à l’aide des méthodes normales (sans plan d’exécution prédéfini).
Si un plan d’exécution prédéfini prévoit l’utilisation d’un objet qui ne peut être utilisé (par exemple, s’il fait référence à un index qui n’existe plus), l’instruction ne tient pas compte du conseil. Pour vérifier si un plan d’exécution prédéfini est utilisé, l’outil Explain Plan d’une instruction doit être comparé lors d’exécutions avec et sans USE_STORED_OUTLINES.
7. Utiliser des plans d’exécution privés
Le paramètre USE_PRIVATE_OUTLINES vous permet de contrôler l’utilisation de plans d’exécution privés. Un plan d’exécution privé n’est visible que dans la session active et ses données résident dans le schéma d’analyse en cours. Les modifications effectuées dans un plan d’exécution de ce type ne sont visibles par aucune autre session sur le système. En outre, un plan d’exécution privé ne peut être utilisé que dans la session en cours pour compiler une instruction et avec l’aide du paramètre USE_PRIVATE_OUTLINES. Vos modifications ne peuvent être vues par les autres utilisateurs que si vous les enregistrez explicitement dans la zone publique. Une copie du plan d’exécution est enregistrée dans le schéma de l’utilisateur au début de la session de modification du plan d’exécution prédéfini. Toutes les modifications suivantes sont effectuées sur cette copie jusqu’à ce que l’utilisateur soit satisfait du résultat et décide de le publier. Tant qu’elles ne sont pas explicitement enregistrées, les modifications effectuées par l’utilisateur n’affectent pas les autres utilisateurs, qui continuent d’utiliser la version publique du plan d’exécution. Lorsqu’un plan d’exécution privé est créé, une erreur est renvoyée si les tables du plan d’exécution requises, destinées à contenir les données du plan n’existent pas dans le schéma local. Ces tables peuvent être créées à l’aide de la procédure DBMS_OUTLN_EDIT.CREATE_EDIT_TABLES.
• Conditions préalables pour utiliser les plans d’exécution privés
Lorsque le paramètre USE_PRIVATE_OUTLINES est activé et qu’une instruction SQL figurant dans un plan d’exécution est exécutée, l’optimiseur extrait le plan d’exécution de la zone privée de la session. Si vous utilisez le paramètre USE_STORED_OUTLINES, le plan est extrait de la zone publique. Si la zone privée de la session ne contient pas de plan d’exécution, l’optimiseur s’en dispensera pour compiler l’instruction.
Gérer les plans d’exécution prédéfinis
Utilisez les procédures du package OUTLN_PKG pour gérer les plans d’exécution prédéfinis ainsi que leurs catégories. Ces procédures sont les suivantes :
• Drop_unused : supprime les plans d’exécution prédéfinis qui n’ont pas été utilisés depuis leur création.
• Drop_by_cat : supprime les plans d’exécution prédéfinis associés au nom de catégorie indiqué.
• Update_by_cat : réaffecte les plans d’exécution prédéfinis d’une catégorie à une autre.
Les plans d’exécution prédéfinis peuvent également être gérés à l’aide des commandes ALTER/DROP OUTLINE.
Vous pouvez exporter et importer des plans en exportant le schéma OUTLN, dans lequel sont stockés tous les plans d’exécution prédéfinis. Vous pouvez interroger les plans d’exécution prédéfinis à partir des tables du schéma :
• OL$ : nom du plan d’exécution prédéfini, catégorie, horodatage de création du plan et texte de l’instruction
• OL$HINTS : conseils relatifs aux plans d’exécution prédéfinis figurant dans OL$
Les vues du dictionnaire de données équivalentes sont DBA_OUTLINES et DBA_OUTLINE_HINTS.
Remarque : OUTLN étant automatiquement créé avec la base de données, son mot de passe doit être modifié.
8. Utiliser des conseils dans une instruction SQL
Vous possédez peut-être des informations relatives à vos données que l’optimiseur ne connaît pas. Par exemple, vous savez peut-être qu’un certain index est plus sélectif pour certaines interrogations. Compte tenu de cette information, vous êtes mieux placé que l’optimiseur pour choisir un plan d’exécution efficace. Dans ce cas, utilisez des conseils pour contraindre l’optimiseur à utiliser le meilleur plan d’exécution.
• Exemple
Dans l’exemple ci-dessous, la colonne cust_gender de la table customers est indexée. L’instruction est exécutée plus rapidement à l’aide de l’index gen_idx, car le nombre de clients masculins est très faible. Un conseil permet de contraindre l’optimiseur à utiliser l’index.
2 cust_last_name, cust_street_address,
3 cust_postal_code
4 FROM sh.customers
5 WHERE UPPER (cust_gender) = ‘M';
De nombreux outils de diagnostic permettent d’évaluer les performances des instructions SQL et des modules PL/SQL. Chacun d’entre eux fournit aux développeurs ou aux administrateurs de base de données un niveau variable d’informations.
• STATSPACK : cet utilitaire collecte des informations concernant les statistiques de base de données et les instructions SQL.
• EXPLAIN PLAN : cet outil est exécuté au cours d’une session, pour le diagnostic d’une instruction SQL.
• SQL Trace : cet utilitaire fournit des informations détaillées sur l’exécution des instructions SQL.
• TKPROF : cet utilitaire du système d’exploitation convertit la sortie d’une session SQL TRACE dans un format lisible.
• AUTOTRACE : il s’agit d’une fonction SQL*Plus. AUTOTRACE génère un plan d’exécution pour une instruction SQL et fournit des statistiques relatives au traitement de cette instruction.
• Oracle SQL Analyze : cet outil fait partie d’Oracle Enterprise Manager Tuning Pack. Il offre une puissante interface utilisateur pour le réglage des instructions SQL.
10. Etats SQL dans STATSPACK
STATSPACK fournit quatre vues différentes, basées sur des instructions SQL stockées dans la zone de mémoire partagée du cliché (snapshot) de début ou de fin. Ces instructions SQL sont rapportées dans quatre sections différentes de l’état :
• SQL ordered by gets
• SQL ordered by reads
• SQL ordered by executions
• SQL ordered by parse calls
Ces vues peuvent être examinées pour voir quelles instructions SQL ont l’impact le plus fort sur les performances de la base de données. Il est préférable de régler ces instructions, car elles sont susceptibles d’améliorer considérablement les performances.
11. EXPLAIN PLAN
Vous pouvez utiliser l’instruction EXPLAIN PLAN de SQL*Plus sans la fonction de trace. Vous devez créer une table nommée plan_table à l’aide du script utlxplan.sql fourni. Les colonnes les plus utiles sont operation, options et object_name.
Pour utiliser l’outil Explain Plan pour une interrogation, utilisez la syntaxe suivante :
FOR SELECT ….
Exemple :
2 select last_name from hr.employees;
Interrogez ensuite la table plan_table pour vérifier le plan d’exécution. Cette table vous indique comment l’instruction serait exécutée à cet instant. Notez que si vous effectuez des modifications (création d’un index par exemple) avant d’exécuter l’instruction, l’exécution risque d’être différente. De plus, si vous n’utilisez pas de paramètre STATEMENT_ID dans l’instruction EXPLAIN PLAN, vous pouvez vider la table PLAN_TABLE avant de générer un autre plan d’exécution. Le paramètre STATEMENT_ID permet d’appliquer un marqueur à une instruction particulière dans la table PLAN_TABLE, en particulier s’il risque d’exister plusieurs versions de la même instruction.
• Interroger la table PLAN_TABLE
Vous pouvez interroger la table directement ou exécuter le script utlxpls.sql ou utlxplp.sql (selon que les statistiques Parallel Query sont requises ou non). Ces scripts indiquent les colonnes les plus fréquemment sélectionnées de la table plan_table.
12. Utiliser SQL Trace et TKPROF
Une procédure spécifique doit être suivie pour évaluer correctement les performances des instructions SQL à l’aide de SQL Trace et de TKPROF :
• La première étape consiste à définir les paramètres d’initialisation de façon appropriée. Cette définition peut s’effectuer au niveau de l’instance, mais il est possible également de définir certains paramètres au niveau de la session.
• Vous devez appeler SQL Trace soit au niveau de l’instance, soit au niveau de la session. En règle générale, il est conseillé de l’appeler au niveau de la session.
• Exécutez l’application ou l’instruction SQL à diagnostiquer.
• Arrêtez SQL Trace pour pouvoir fermer correctement le fichier trace au niveau du système d’exploitation.
• Utilisez TKPROF pour rendre lisible le fichier trace généré au cours de la session de trace. Si le fichier de sortie n’est pas lisible, il est très difficile d’interpréter les résultats.
• Pour diagnostiquer les performances de l’instruction SQL, utilisez les résultats de TKPROF.
• Bref :
Pour utiliser SQL trace et TKPROF :
• Définissez les paramètres d’initialisation.
• Alter session set SQL_Trace = true
• Démarrez l’application.
• Alter session set SQL_Trace = false
• Rendez le fichier trace lisible à l’aide de TKPROF.
• Interprétez les résultats.
• Paramètres d’initialisation
Deux paramètres du fichier init.ora gèrent la taille et la destination du fichier de sortie généré par l’utilitaire SQL Trace :
max_dump_file_size = n
Ce paramètre est exprimé en octets s’il porte la mention Ko ou Mo, ou, à défaut, en nombre de blocs du système d’exploitation. La valeur par défaut est de 10000 blocs de système d’exploitation.
Lorsqu’un fichier trace dépasse la taille définie par la valeur de ce paramètre, le message suivant s’affiche à la fin du fichier : *** Trace file full ***
Le paramètre suivant détermine la destination du fichier trace :
user_dump_dest = directory
Vous devez définir un troisième paramètre pour obtenir les statistiques temporelles :
timed_statistics = TRUE
La résolution des statistiques temporelles s’effectue au centième de seconde.
Le paramètre TIMED_STATISTICS peut également être défini de manière dynamique au niveau de la session, à l’aide de la commande ALTER SESSION.
Activer et désactiver SQL Trace
SQL Trace peut être activé ou désactivé à l’aide de différentes méthodes, au niveau de l’instance ou de la session.
Au niveau de l’instance :
La définition du paramètre SQL_TRACE au niveau de l’instance constitue l’une des méthodes d’activation de la fonction de trace. Toutefois, l’instance doit être arrêtée, puis redémarrée une fois que la fonction de trace n’est plus utilisée. En outre, le taux de performance doit être élevé, car toutes les sessions de l’instance font l’objet d’un suivi d’exécution.
Au niveau de la session :
L’utilisation de la fonction de trace au niveau de la session requiert un taux de performance moindre, car le suivi peut porter sur des sessions spécifiques. Vous pouvez activer ou désactiver SQL Trace :
• à l’aide de la commande ALTER SESSION, qui permet d’exécuter la fonction de trace pendant toute la durée de la session ou jusqu’à ce que la valeur FALSE soit définie,
• en utilisant la procédure DBMS_SESSION.SET_SQL_TRACE pour la session,
• en utilisant la procédure DBMS_SYSTEM.SET_SQL_TRACE_IN_SESSION pour activer la fonction de trace dans une session différente de la session actuelle.
Exemple :
SQL> execute DBMS_SESSION.SET_SQL_TRACE {true|false});
SQL> execute DBMS_SYSTEM.SET_SQL_TRACE_IN_SESSION
2 (session_id, serial_id, {true|false});
13. Rendre le fichier trace lisible à l’aide de TKPROF
Utilisez TKPROF pour rendre le fichier trace lisible :
tkprof tracefile outputfile [sort=option] [print=n] [explain=username/password] [insert=filename] [sys=NO] [record=filename] [table=schema.tablename]
Exemple :
Le fichier trace est créé dans le répertoire indiqué à l’aide du paramètre USER_DUMP_DEST et la sortie est placée dans le répertoire indiqué par le nom du fichier de sortie.
SQL Trace permet également de collecter des statistiques sur les instructions SQL récursives. Vous ne pouvez pas modifier directement la quantité d’instructions SQL récursives exécutées par le serveur ; par conséquent, ces statistiques vous sont d’une grande utilité. Utilisez l’option SYS=NO de TKPROF pour supprimer la sortie de ces statistiques.
Lorsque vous définissez le paramètre EXPLAIN, l’utilitaire TKPROF se connecte à la base de données à l’aide du nom utilisateur et du mot de passe fournis. Il étudie ensuite le chemin d’accès de chaque instruction SQL concernée par la fonction de trace et inclut ces informations dans la sortie. Dans la mesure où TKPROF se connecte à la base de données, il utilise les informations disponibles lors de son exécution et non au moment où les statistiques de trace ont été générées. Cette distinction peut s’avérer importante si, par exemple, un index a été créé ou supprimé après l’exécution de la fonction de trace sur une instruction.
TKPROF signale également les échecs dans le cache « library ». Ces échecs indiquent le nombre de fois où l’instruction n’a pas été trouvée dans le cache « library ».
• Options de l’utilitaire TKPROF
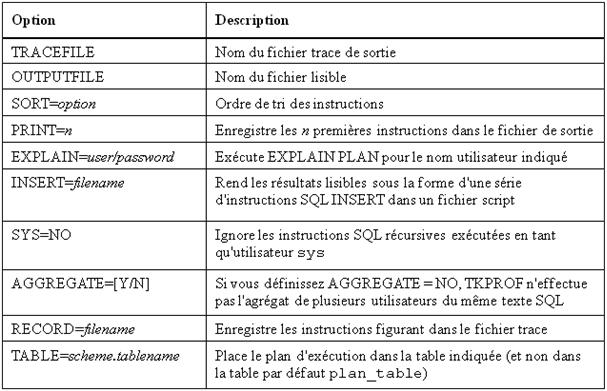
Pour obtenir la liste de toutes les options et sorties disponibles, entrez tkprof à l’invite du système d’exploitation.
Remarque : Les options de tri sont les suivantes : 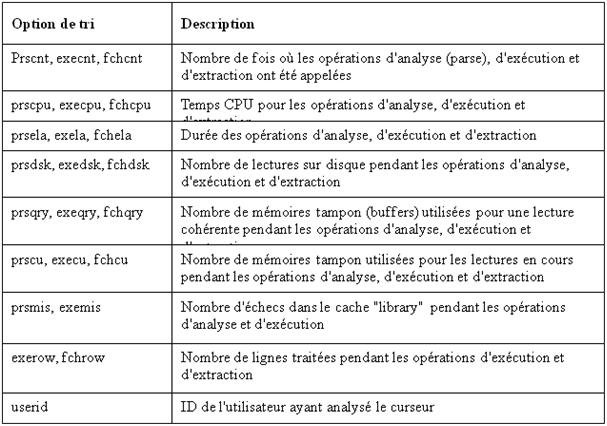
14. Statistiques de TKPROF
TKPROF collecte les statistiques suivantes :
• Count : nombre d’analyses ou d’exécutions de l’instruction et nombre d’appels « fetch » émis pour cette instruction
• CPU : durée de traitement pour chaque phase, en secondes. Si l’instruction figurait dans la zone de mémoire partagée ou si le temps nécessaire à l’analyse était inférieur à 1/100e de seconde, cette valeur est égale à 0.
• Elapsed : temps écoulé exprimé en secondes (en règle générale, cette information n’est pas très utile, car d’autres processus ont une incidence sur le temps écoulé).
• Disk : Nombre de blocs de données physiques lus dans les fichiers de base de données (en général, ce nombre est peu élevé si les données se trouvaient en mémoire tampon).
• Query : Mémoires tampon logiques extraites pour une lecture cohérente (généralement pour les instructions SELECT)
• Current : mémoires tampon logiques extraites en mode courant (généralement pour les instructions LMD)
• Rows : lignes traitées par l’instruction externe (pour les instructions SELECT, le nombre de lignes est affiché pour la phase de « fetch » ; pour les instructions LMD, il est affiché pour la phase d’exécution).
La somme des statistiques Query et Current représente le nombre total de mémoires tampon logiques utilisées.
15. SQL*Plus AUTOTRACE
Vous pouvez utiliser SQL*Plus AUTOTRACE à la place de SQL Trace. L’utilisation d’AUTOTRACE présente l’avantage suivant : vous n’êtes pas obligé de rendre lisible le fichier trace et le plan d’exécution de l’instruction SQL est automatiquement affiché.
Toutefois, AUTOTRACE analyse et exécute l’instruction, tandis que l’outil Explain Plan ne fait que l’analyser.
Pour utiliser AUTOTRACE, procédez comme suit :
1. Créez la table Plan_table à l’aide du script utlxplan.sql.
2. Créez le rôle Plustrace en exécutant le script plustrce.sql. Cela permet d’accorder au rôle des privilèges SELECT sur les vues V$ et d’accorder le rôle Plustrace au rôle DBA. Octroyez le rôle Plustrace aux utilisateurs qui ne possèdent pas le rôle DBA.
3. Choisissez le niveau souhaité pour AUTOTRACE :
– OFF : AUTOTRACE est désactivée (option par défaut).
– ON : inclut le chemin d’exécution de l’optimiseur et les statistiques d’exécution des instructions SQL.
– ON EXPLAIN : affiche uniquement le chemin d’exécution de l’optimiseur.
– ON STATISTICS : affiche uniquement les statistiques d’exécution des instructions SQL.
– TRACEONLY : identique à ON, mais supprime les résultats de l’interrogation de l’utilisateur.
Exemple :
SQL> grant plustrace to scott;
Puis :
16. Nombre de blocs et de blocs vides
Un repère high-water mark est contenu dans le bloc d’en-tête de segment de chaque table. Ce repère indique le dernier bloc utilisé pour cette table. Lorsque le serveur Oracle effectue des balayages complets de table, il lit tous les blocs jusqu’au repère high-water mark. Notez que ce repère n’est pas réinitialisé lorsque des lignes sont supprimées de la table.
La procédure DBMS_SPACE.UNUSED_SPACE peut être utilisée pour rechercher le repère high-water mark et le nombre de blocs situés au-dessus de ce repère, si l’analyse d’une table est impossible ou n’est pas souhaitée.
Exemple :
2 'TABLE', :total_blocks, :total_bytes,:unused_blocks,-
3 :unused_bytes, :lastextf, :last_extb, :lastusedblock);
2 avg_space,avg_row_len, sample_size
3 from dba_tables
4 where table_name = ‘ORDERS' and owner = ‘SH’;
NUM_ROW | SBLOCKS | EMPTY_BLOCKS | AVG_SPACE | AVG_ROW_LEN | SAMPLE_SIZE
------- ------- ------------ --------- ----------- -----------
15132 434 5 225 48 1064
17. Statistiques relatives aux index
Le facteur de regroupement dans l’index constitue un type de statistiques d’index important pour l’optimiseur basé sur le coût, puisqu’il permet d’évaluer les coûts de balayage d’index. Il donne une indication du nombre d’accès aux blocs de données (logiques) nécessaire pour extraire toutes les lignes de la table via l’index. Si les entrées d’index suivent l’ordre des lignes de la table, cette valeur est proche du nombre de blocs de données (un seul accès par bloc) ; en revanche, si les entrées d’index pointent de façon aléatoire sur différents blocs de données, le facteur de regroupement peut être proche du nombre de lignes.
Exemple :
2 :total_blocks, :total_bytes,:unused_blocks, -
3 :unused_bytes, :lastextf, :last_extb, :lastusedblock);
2 clustering_factor
3 from dba_indexes
4 where index_name = ‘SALES_PK' and owner = ‘SH’;
BLEVEL | LEAF_BLOCKS |DISTINCT_KEYS | CLUSTERING_FACTOR
-------- ----------- ------------- -----------------
2 682 56252 21349
18. Modèle de coût d’un optimiseur
Un optimiseur d’interrogation a pour mission de générer le meilleur plan d’exécution pour une interrogation donnée. Ce processus inclut la sélection de chemins d’accès à des tables uniques, les méthodes de jointure et l’ordre des jointures si plusieurs tables sont concernées par l’interrogation.
Vous avez le choix entre l’optimiseur basé sur les règles et l’optimiseur basé sur le coût. Ce dernier utilise un modèle de coût pour sélectionner les chemins d’accès ainsi que l’ordre et les méthodes de jointures, tandis que l’optimiseur basé sur les règles utilise un ensemble de règles simples.
L’optimiseur basé sur le coût compare plusieurs alternatives et sélectionne celle dont le coût est le plus faible. Outre le modèle de coût, il utilise un modèle de taille afin de dériver des statistiques sur des tables intermédiaires ; par exemple, la cardinalité du résultat d’une opération de jointure.
Le modèle de coût utilise des statistiques relatives aux objets manipulés par l’interrogation. Ces statistiques sont générées à l’aide du package DBMS_STATS et stockées dans le dictionnaire de données.
La qualité du plan d’exécution généré par l’optimiseur dépend de la précision du modèle de coût. Le modèle proposé par Oracle8i présente certaines limites : il n’est pas totalement précis ni complet. Par exemple, il considère que les colonnes sont indépendantes lors du calcul de la sélectivité de plusieurs prédicats sur différentes colonnes et il ne prend en compte que les activités d’E/S.
19. Amélioration du modèle de coût d’un optimiseur
Le modèle de coût a été amélioré pour pouvoir effectuer les tâches suivantes :
• Permettre aux utilisateurs ou aux développeurs de convertir le coût en informations plus significatives. Trois nouvelles colonnes ont été ajoutées à la table PLAN_TABLE :
– CPU_COST : cette colonne contient le coût CPU estimé pour l’opération à l’aide de l’approche basée sur le coût de l’optimiseur. Pour les instructions qui utilisent l’approche basée sur les règles, la valeur de cette colonne est NULL. La valeur de la colonne CPU_COST est proportionnelle au nombre de cycles requis pour l’opération.
– IO_COST : cette colonne contient le coût d’E/S etimé pour l’opération à l’aide de l’approche basée sur le coût de l’optimiseur. Pour les instructions qui utilisent une approche basée sur les règles, la valeur de cette colonne est NULL. La valeur de la colonne IO_COST est proportionnelle au nombre de blocs de données lus par l’opération.
– TEMP_SPACE : cette colonne indique l’espace temporaire, en octets, utilisé par l’opération ; cet espace est estimé à l’aide de l’approche basée sur le coût de l’optimiseur. Pour les instructions qui utilisent l’approche basée sur les règles ou pour les opérations qui n’utilisent pas d’espace temporaire, la valeur de cette colonne est NULL.
• Inclure l’utilisation de la CPU. Son estimation concerne les fonctions et les opérateurs SQL.
• Prendre en compte l’effet de la mise en mémoire cache sur les performances des jointures en boucle imbriquées (nested-loops joins).
• Prendre en compte la pré-extraction des index, qui consiste à extraire plusieurs blocs feuille en une seule opération d’E/S.
20. Copier des statistiques d’une base de données vers une autre
Pour que les opérations de réglage soient plus simples, copiez les statistiques d’une base de données de production Oracle9i vers une base de données test, à l’aide des procédures de package DBMS_STATS. Par exemple, pour copier les statistiques d’un schéma, procédez comme suit : 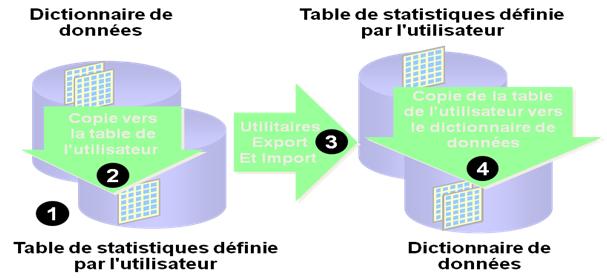
1. Utilisez la procédure DBMS_STATS.CREATE_STAT_TABLE de la base de données de production pour créer une table de statistiques définie par l’utilisateur.
2. Utilisez la procédure DBMS_STATS.EXPORT_SCHEMA_STATS de la base de données de production pour copier les statistiques du dictionnaire de données vers la table de statistiques définie par l’utilisateur à l’étape 1.
3. Servez-vous des utilitaires Export et Import pour transférer les statistiques vers une table de statistiques définie par l’utilisateur dans la base de données test.
4. Utilisez la procédure DBMS_STATS.IMPORT_SCHEMA_STATS pour importer les statistiques dans le dictionnaire de données de la base de données test.
Le package DBMS_STATS peut également être utilisé pour effectuer une sauvegarde des statistiques avant l’analyse d’objets. La sauvegarde peut être utilisée pour
• restaurer d’anciennes statistiques,
• étudier les modifications des caractéristiques des données dans le temps.
Catégories
| L | Ma | Me | J | V | S | D |
|---|---|---|---|---|---|---|
| « oct | ||||||
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 | 31 | ||