Ce blog n’est plus mis Ă jour depuis septembre et ne le sera vraisemblablement plus jamais. Je continue cependant mes activitĂ©s sur un autre blog WordPress, nettement plus Ă jour au niveau du logiciel.
Fin de ce blog
RĂ©pondre
Developpez.com
Accueil
Ce blog n’est plus mis Ă jour depuis septembre et ne le sera vraisemblablement plus jamais. Je continue cependant mes activitĂ©s sur un autre blog WordPress, nettement plus Ă jour au niveau du logiciel.
L’Unreal Engine nouveau est arrivĂ©, trois mois après le prĂ©cĂ©dent, comme d’habitude. LĂ oĂą la version prĂ©cĂ©dente se concentrait sur la rĂ©alitĂ© virtuelle, la version 4.13 s’Ă©parpille plus, mĂŞme si l’Ă©diteur en rĂ©alitĂ© virtuelle est toujours l’objet d’une grande attention. Parmi les domaines d’amĂ©liorations, on compte cette fois le rendu et l’Ă©diteur de cinĂ©matiques, mĂŞme s’il est impossible de citer toutes les nouveautĂ©s en peu de mots.

L’Ă©diteur non linĂ©aire de cinĂ©matiques apparu dans la 4.12 reste le théâtre d’opĂ©rations d’envergure, avec la possibilitĂ© d’enregistrer en direct une partie dans le jeu dĂ©veloppĂ©. Cette capture n’est pas une vidĂ©o : au contraire, toutes les animations, tous les effets, tous les sons sont mĂ©morisĂ©s sĂ©parĂ©ment et peuvent ĂŞtre modifiĂ©s dans l’Ă©diteur ! Au moment de cette capture, il est aussi possible de limiter l’enregistrement Ă une sĂ©rie de composants et de propriĂ©tĂ©s.
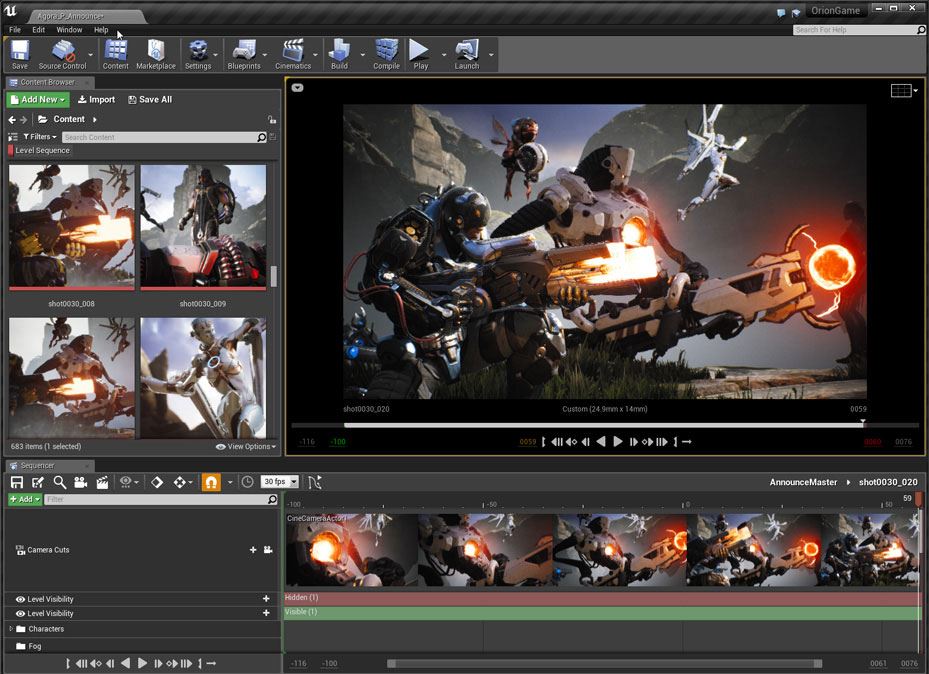
Du cĂ´tĂ© du rendu 3D, les lampes ont vu leur code optimisĂ© : si une lumière ne se dĂ©place pas dans la scène, une bonne partie des calculs dĂ©jĂ effectuĂ©s peuvent ĂŞtre rĂ©utilisĂ©s sans problème pour la prochaine image Ă afficher. Le problème de performance vient surtout du calcul des ombres que crĂ©e la lumière (plus prĂ©cisĂ©ment, de la carte des profondeurs). Cette optimisation est appliquĂ©e automatiquement et ses rĂ©sultats sont intĂ©ressants : pour afficher l’image ci-dessous, avec trente-trois points de lumière, il faut compter 14,89 ms pour l’affichage des ombres ; grâce aux caches implĂ©mentĂ©s, la mĂŞme partie prend 0,9 ms d’affichage, ce qui permet d’ajouter d’autres effets (il faut cependant compter deux millisecondes pour l’affichage de la lumière, une contribution qui n’est pas touchĂ©e par cette optimisation).

Unreal Engine permet de gĂ©nĂ©rer des matĂ©riaux de manière alĂ©atoire grâce Ă des fonctions de bruit. La famille d’algorithmes disponibles s’est agrandie pour recevoir le bruit de VoronoĂŻ, très souvent utilisĂ© pour la gĂ©nĂ©ration procĂ©durale. Il s’applique notamment très bien Ă la gĂ©nĂ©ration de marbre, le rendu Ă©tant très rĂ©aliste après un peu de configuration.


Il devient possible de superposer des couches de matériaux sur une topologie statique, ce qui peut avoir un effet de lissage entre les différents calques, sans utiliser de projection.

L’interaction avec des composants d’interface graphique intĂ©grĂ©s dans le monde peut se faire avec n’importe quel pointeur laser (pas simplement directement avec la souris). L’action ainsi gĂ©nĂ©rĂ©e simule celle que pourrait avoir un composant matĂ©riel : un clic gauche ou droit… ou toute autre interaction. Cette amĂ©lioration vient en support Ă celles de l’Ă©diteur en rĂ©alitĂ© virtuelle (voir plus bas).
 Les applications mobiles pourront utiliser des effets de type posttraitement, par exemple comme si l’image venait d’une vieille tĂ©lĂ©vision. Ces effets ne peuvent pas encore exploiter toutes les informations disponibles pour le rendu (la profondeur de chaque pixel n’est pas encore accessible), mais cela devrait venir avec une version ultĂ©rieure. Ces effets ne sont pas disponibles sur les versions les plus ancestrales d’Android.
Les applications mobiles pourront utiliser des effets de type posttraitement, par exemple comme si l’image venait d’une vieille tĂ©lĂ©vision. Ces effets ne peuvent pas encore exploiter toutes les informations disponibles pour le rendu (la profondeur de chaque pixel n’est pas encore accessible), mais cela devrait venir avec une version ultĂ©rieure. Ces effets ne sont pas disponibles sur les versions les plus ancestrales d’Android.

Les opĂ©rations de pavage des paysages sont maintenant bien plus rapides qu’avant, l’accĂ©lĂ©ration matĂ©rielle Ă©tant mieux utilisĂ©e : cette technique de rendu n’est utilisĂ©e que pour les plus hauts niveaux de dĂ©tail, elle ne l’est plus du tout pour les plus faibles (comme des zones lointaines).

Le nouvel Ă©diteur en rĂ©alitĂ© virtuelle, apparu pour la 4.12, est toujours l’objet d’une grande attention. Il devient possible de peindre sur des textures existantes, par exemple.
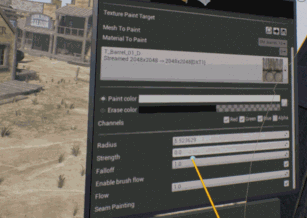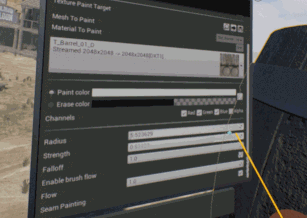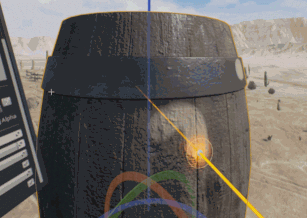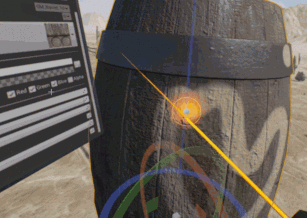
Il permet aussi de peindre rapidement une sĂ©rie d’arbres, en sĂ©lectionnant simplement le type de feuillage Ă crĂ©er.
Bien Ă©videmment, cette nouvelle version vient avec bien d’autres nouvelles fonctionnalitĂ©s et optimisations, dĂ©crites dans les notes de version.
Source et images : UNREAL ENGINE 4.13 RELEASED!.
Au niveau algorithmique, la compression de donnĂ©es sans perte (Ă la ZIP, RAR, TAR.GZ, 7Z) n’a plus beaucoup Ă©voluĂ© ces dernières annĂ©es : il s’agit toujours d’un assemblage de dictionnaires, de code de Huffman, de codage arithmĂ©tique, de modèle statistique. Il n’empĂŞche : ces techniques, bien maĂ®trisĂ©es, peuvent toujours s’amĂ©liorer petit Ă petit et donner des outils de compression redoutablement efficaces, comme Google Brotli, arrivĂ© sur le marchĂ© dĂ©but 2016.
Bien maĂ®trisĂ©es, ces techniques peuvent… faire d’Ă©normes progrès ! C’est ainsi que RAD Games a annoncĂ© de nouveaux outils de compression (propriĂ©taires et payants) qui fonctionnent nettement mieux que la concurrence (principalement libre), en fonction du critère de comparaison. Au niveau de l’implĂ©mentation, rien de vraiment neuf, si ce n’est un soin tout particulier apportĂ© par de fins connaisseurs du domaine de la compression, avec et sans pertes.
La sociĂ©tĂ© peut maintenant se targuer de proposer un outil de compression dont la principale caractĂ©ristique est une dĂ©compression extrĂŞmement rapide (de trois Ă cinq fois plus que zlib) avec des taux de compression du mĂŞme ordre que LZMA (en Ă©tant dix Ă trente fois plus rapide que ce dernier), nommĂ© Kraken. Il donne aussi du fil Ă retordre Ă LZ4 : ce dernier reste le plus rapide sur tous les types de documents, mais Kraken s’en rapproche fortement tout en gardant une compression nettement meilleure que LZ4.
Deux dĂ©rivĂ©s (disponibles depuis cet Ă©tĂ©) de cet outil sont plus spĂ©cialisĂ©s, en compressant moins mais en dĂ©compressant (beaucoup) plus vite : Mermaid offre une compression moyenne (du mĂŞme ordre que ZIP), tout en Ă©tant extrĂŞmement rapide en dĂ©compression (de sept Ă douze fois plus que zlib, c’est-Ă -dire plus de deux fois plus rapide que Kraken) ; Selkie, au contraire, abandonne encore un peu de compression (entre ZIP et LZ4), pour dĂ©passer LZ4 d’un facteur de presque deux (la dĂ©compression est très proche d’une copie en mĂ©moire, ce qui est un tour de force technique pour une compression non triviale).
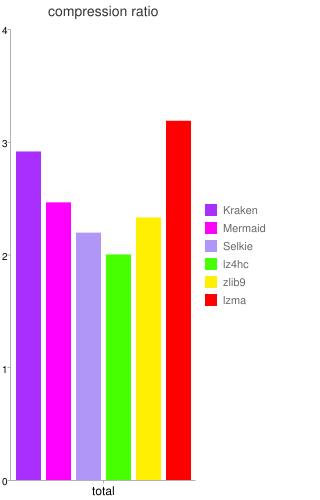
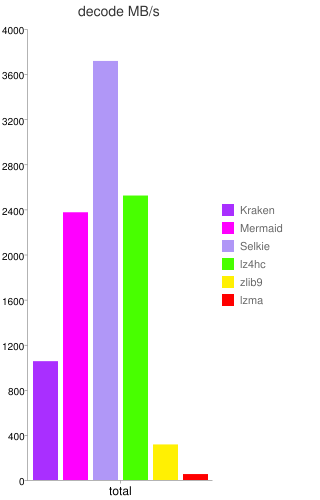
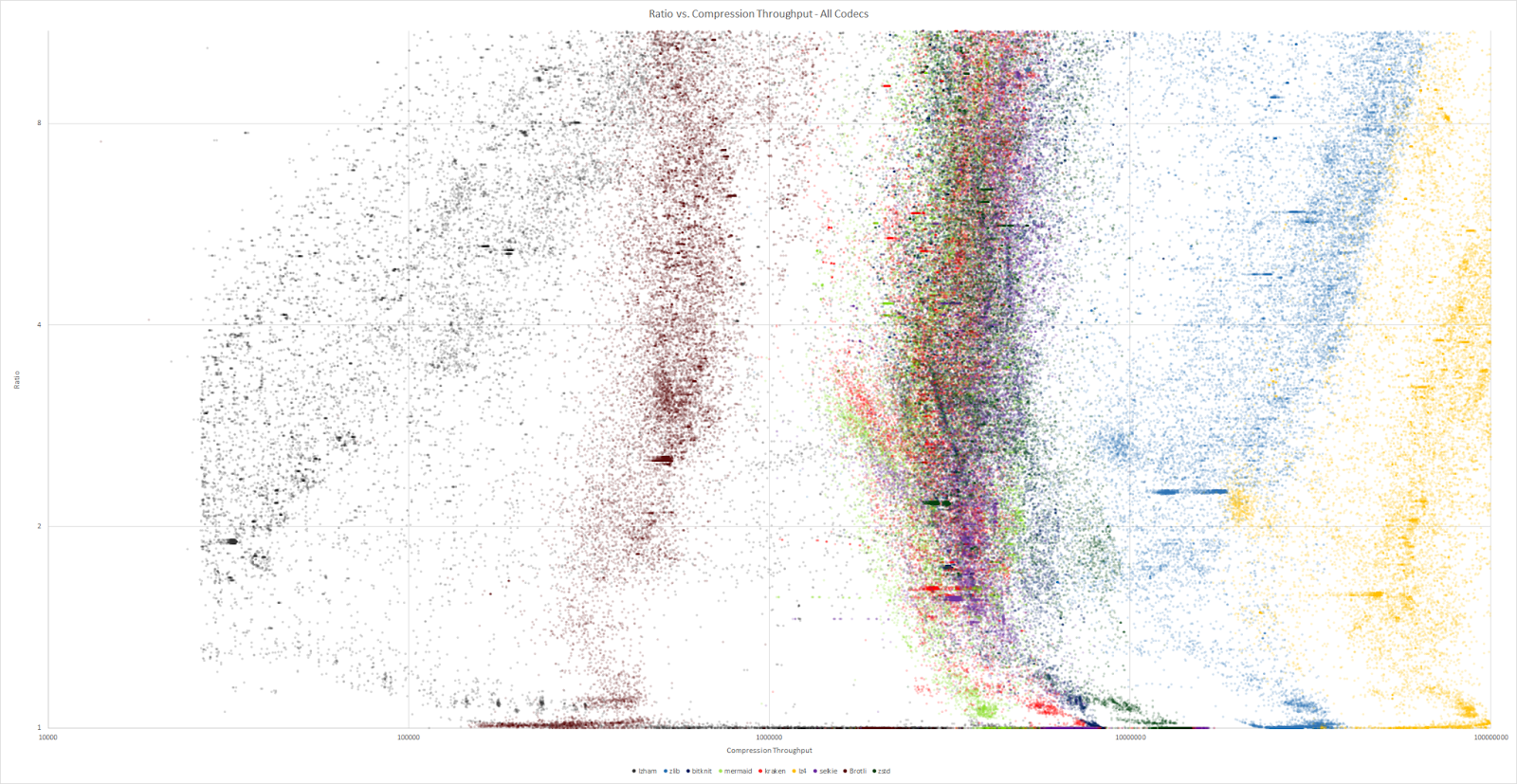
Les chiffres du terrain
Les chiffres donnés sont les officiels, reste encore à les confirmer par des extérieurs. Les comparaisons parfaitement équitables sont difficiles à obtenir, puisque les outils de compression ne sont pas si faciles à obtenir.
En comparant le ratio de compression avec les dĂ©bits, ces trois outils sont collĂ©s du cĂ´tĂ© des hauts dĂ©bits (mĂŞme si Kraken n’y est que peu prĂ©sent). Zlib occupe une place intermĂ©diaire.
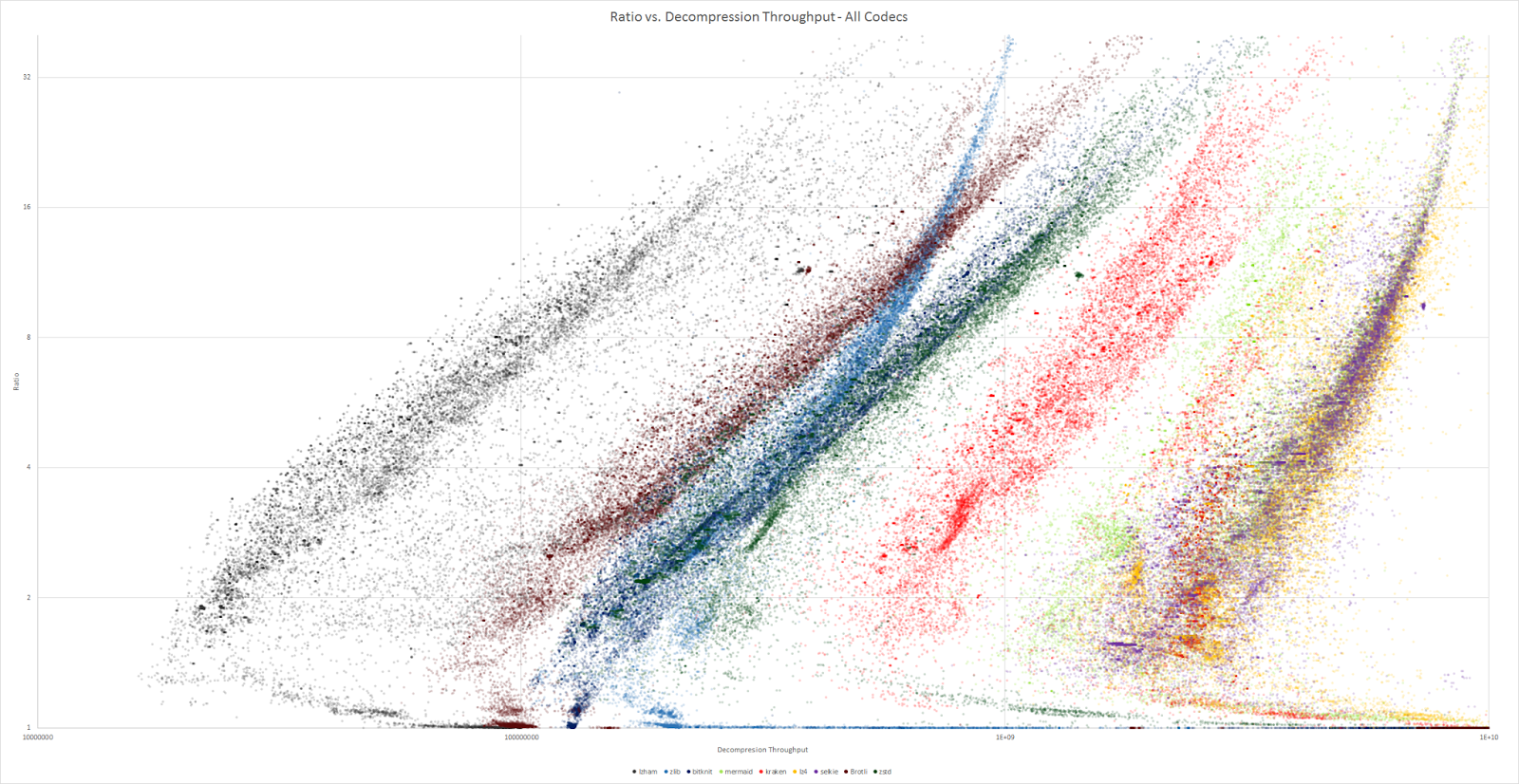
Ces algorithmes sont moins optimisĂ©s en temps pour la compression, il n’empĂŞche qu’ils prĂ©sentent de bons rĂ©sultats. Ils sont nettement plus Ă©loignĂ©s de leurs meilleurs concurrents (comme LZ4… ou zlib).
Du côté algorithmique ?
Ces outils Ă©tant propriĂ©taires, difficile d’aller lire leur code source pour comprendre les amĂ©liorations proposĂ©es. Cependant, certains s’avancent et proposent des pistes qui auraient permis d’atteindre ces nouveaux sommets. Le dĂ©codage très rapide pourrait venir d’une utilisation très judicieuse de la hiĂ©rarchie mĂ©moire des processeurs actuels : autant de donnĂ©es que possible sont stockĂ©es dans les caches du processeur afin de limiter les accès Ă la mĂ©moire vive (qui sont extrĂŞmement lents).
Une tout autre piste suit la thĂ©orie des langages formels, en tentant de construire une grammaire dont le seul mot acceptĂ© est le fichier Ă compresser : les promesses de l’algorithme GLZ sont d’atteindre des taux de compression dignes des algorithmes de prĂ©diction par reconnaissance partielle (la probabilitĂ© de rencontrer un symbole — par exemple, un octet — dĂ©pend d’un certain nombre de symboles dĂ©jĂ lus) tout en gardant la rapiditĂ© des algorithmes de la famille LZ (qui fonctionnent avec des dictionnaires). Les grammaires ainsi gĂ©nĂ©rĂ©es ont pour particularitĂ© d’avoir une entropie faible, c’est-Ă -dire qu’elles se compressent très bien par d’autres algorithmes.
Toutefois, il semblerait que ces pistes n’aient pas Ă©tĂ© suivies pour le dĂ©veloppement de ces algorithmes. Peut-ĂŞtre nourriront-elles la prochaine gĂ©nĂ©ration d’outils de compression ? Cependant, les compromis subsisteront probablement : la rĂ©volution d’un algorithme qui compresse très vite et très bien et qui dĂ©compresse au moins aussi vite n’est pas encore en vue.
Sources : site officiel d’Oodle, nouveautĂ©s d’Oodle 2.3.0 (dont images), Kraken compressor , Grammatical Ziv-Lempel Compression: Achieving PPM-Class Text Compression Ratios With LZ-Class Decompression Speed, RAD’s ground breaking lossless compression product benchmarked (dont images).
Voir aussi : le blog de Charles Bloom, développeur de Kraken, Mermaid et Selkie.
Dans l’industrie des semiconducteurs, la loi de Moore suppose que la quantitĂ© de transistors sur une puce double tous les deux ans (la taille de ces puces Ă©tant limitĂ©e par les processus de production). Jusqu’Ă prĂ©sent, bien qu’entièrement empirique, elle a Ă©tĂ© respectĂ©e, mĂŞme si de plus en plus de gens la dĂ©clarent morte : il faut maintenant plus de deux ans pour doubler la densitĂ© de transistors. Par exemple, Intel a annoncĂ© avoir changĂ© son cycle d’ingĂ©nierie des processeurs : le rythme est toujours d’une nouvelle gamme de processeurs par an, une pour l’amĂ©lioration du processus physique (Core 5e gĂ©nĂ©ration, dite Broadwell, sortie en 2014-2015), une pour l’amĂ©lioration de la microarchitecture (Core 6e gĂ©nĂ©ration, dite Skylake, sortie en 2015-2016), puis une d’optimisation (Core 7e gĂ©nĂ©ration, dite Kaby Lake, qui devrait commencer Ă arriver dans les rayons fin de cette annĂ©e 2016).
Cependant, mĂŞme les industriels ne sont pas toujours entièrement d’accord avec l’affirmation que la loi de Moore est morte : elle pourrait continuer Ă s’appliquer dans la prochaine dĂ©cennie grâce Ă une nouvelle gĂ©nĂ©ration de transistors 3D. Chez Intel et les autres fondeurs qui exploitent des processus 14-16 nm, les transistors actuellement gravĂ©s sur les processeurs sont dĂ©jĂ en 3D, des FinFET. Plusieurs de ces transistors doivent ĂŞtre associĂ©s pour effectuer une opĂ©ration sur un ou plusieurs bits, c’est-Ă -dire former une porte logique (par exemple, le complĂ©ment d’un bit, le ET logique de deux bits, etc.) ; les fonctions intĂ©ressantes des processeurs sont obtenues en combinant ces portes logiques.
Adieu CMOS ?
Les idĂ©es en cours de dĂ©veloppement dans l’industrie partent plutĂ´t sur un changement de paradigme plus profond que simplement des transistors 3D amĂ©liorĂ©s. Pour former des portes logiques (par exemple, un NOT), ces transistors sont associĂ©s en paires : un seul des deux transistors de la paire laisse passer du courant en sortie, l’autre Ă©tant bloquĂ© (ce qui permet de choisir la valeur binaire en sortie, selon la tension reliĂ©e Ă chacun des deux transistors). Ces paires sont donc symĂ©triques (chacun des deux transistors effectue la mĂŞme opĂ©ration), mais complĂ©mentaires (chacun est reliĂ© Ă une tension diffĂ©rente). Ce principe est Ă la base des technologies CMOS (complementary metal-oxyde semiconductor), prĂ©dominantes sur le marchĂ© des semiconducteurs depuis les annĂ©es 1960.
Cette technologie CMOS a bon nombre d’avantages, comme une consommation d’Ă©nergie rĂ©duite en fonctionnement statique (le transistor consomme une certaine quantitĂ© d’Ă©nergie pour commuter, mais presque rien sinon) ou une grande immunitĂ© au bruit. Par contre, il est très difficile d’assembler les transistors en trois dimensions. Pour augmenter la densitĂ© de transistors sur une mĂŞme puce, la seule solution, dans le paradigme CMOS, est de rĂ©duire la taille de chaque transistor : c’est ce qui est fait depuis des annĂ©es dans l’industrie, en amĂ©liorant les processus de lithographie. En passant dans la troisième dimension, il devient possible d’augmenter la densitĂ© de transistors sur une mĂŞme puce sans forcĂ©ment changer ces transistors. Il n’empĂŞche que les processus de lithographie doivent s’adapter Ă cette nouvelle manière de penser.
De nouvelles portes logiques
Ce type de construction devient un choix de plus en plus clair : quand la taille de la plus petite altĂ©ration du silicium tend vers 10 nm, les courants de fuite Ă travers les transistors deviennent problĂ©matiques. Ă€ l’horizon 2020-2025, la situation aura empirĂ©, puisque la lithographie aura atteint des prĂ©cisions de gravure de quelques nanomètres, c’est-Ă -dire Ă peine quelques dizaines d’atomes (un atome de silicium a un diamètre de 0,22 nm). Ă€ cela s’ajouteront d’autres problèmes d’ordre quantique (l’effet tunnel permettra Ă des Ă©lectrons de franchir un transistor).
Dans cette ère nanoscopique, l’Ă©lectronique CMOS serait remplacĂ©e par des transistors Ă spin ou des transistors Ă effet tunnel (TFET), afin de rĂ©duire la consommation Ă©nergĂ©tique (le facteur limitant des processeurs actuels). Ces TFET peuvent fonctionner Ă des tensions bien plus faibles que les transistors actuels tout en ayant un courant de fuite très faible ; de mĂŞme, les transistors Ă spin consomment peu d’Ă©nergie (ils stockent l’information dans le spin d’Ă©lectrons) et seraient très adaptĂ©s au stockage non volatil.
Avantages de la construction 3D
Actuellement, cette technique de construction en 3D est nommĂ©e 3D power scaling par les industriels. Une version proche est dĂ©jĂ sur le marchĂ© : plusieurs couches de silicium sont empilĂ©es et connectĂ©es verticalement par des TSV, mais chaque couche garde sa logique CMOS. Ces TSV sont Ă l’origine de la mĂ©moire HBM ou HMC, oĂą les principales difficultĂ©s d’assemblage viennent de l’alignement parfait requis entre les diffĂ©rentes couches. 3DPS Ă©viterait ce problème, puisque les transistors seraient construits aussi Ă la verticale dans un seul processus intĂ©grĂ©.
La mĂ©moire NAND (utilisĂ©e pour les cartes mĂ©moires et les SSD) utilise dĂ©jĂ des procĂ©dĂ©s de type 3DPS, avec trente-deux Ă soixante-quatre couches (notamment chez Samsung). Les industriels estiment que l’avenir des semiconducteurs en gĂ©nĂ©ral est dans ces puces multicouches, y compris pour les processeurs, voire pour l’Ă©lectronique de puissance. Le plus gros problème est la dissipation de l’Ă©nergie consommĂ©e : la chaleur serait alors bien plus concentrĂ©e, la recherche de transistors bien moins Ă©nergivores est un prĂ©requis indispensable Ă un dĂ©ploiement Ă plus grande Ă©chelle des processus 3D ; peut-ĂŞtre faudrait-il alors penser Ă refroidir les puces de l’intĂ©rieur.
Cette nouvelle manière de penser l’organisation des puces aurait d’autres avantages, notamment celui de pouvoir intĂ©grer bien d’autres composants directement sur la mĂŞme puce que le processeur : les registres pourraient ĂŞtre situĂ©s sous les cĹ“urs de calcul, la mĂ©moire Ă quelques niveaux de la partie calcul du processeur, d’autres circuits pourraient aussi ĂŞtre intĂ©grĂ©s. Ainsi, les distances entre toutes ces parties seraient fortement rĂ©duites, ce qui limiterait de facto les dĂ©lais de propagation et pourrait augmenter de manière phĂ©nomĂ©nale la puissance de calcul disponible. Aussi, les canaux de transmission auraient une section utile bien plus importante qu’actuellement, ce qui limiterait l’impact du bruit.
La recherche est toujours en cours au niveau des transistors adaptĂ©s Ă ces nouvelles directions, mais les industriels ont bon espoir et estiment qu’ils devraient arriver en production dans la prochaine dĂ©cennie. Bien qu’ils Ă©vitent toute annonce au niveau des gains en performance ou des coĂ»ts, ils estiment que, grâce Ă ces technologies, la loi de Moore pourrait mĂŞme ĂŞtre dĂ©passĂ©e.
Source : Next-Generation 3D Transistors Could Rejuvenate Moore’s Law.
Voir aussi : rapport ITRS 2015 (chapitre 9).
Mathematica est un logiciel Ă l’origine prĂ©vu pour le calcul symbolique (spĂ©cifiquement pour un public de mathĂ©maticiens, d’oĂą son nom), mais qui s’est ouvert Ă bien d’autres domaines depuis lors : sur ces trente dernières annĂ©es, son domaine d’action s’est largement Ă©tendu en dehors des mathĂ©matiques pures, notamment au niveau de la visualisation, du traitement du signal et des images, des statistiques et de l’apprentissage automatique. Avec le lancement de Wolfram Alpha, un « moteur de connaissances numĂ©rique », le logiciel a directement eu accès Ă une plĂ©thore de donnĂ©es diverses, tant sur les Ă©lĂ©ments chimiques que la sociologie ou la finance, ce qui dĂ©cuple encore ses capacitĂ©s. Un rĂ©sumĂ© de ces domaines est prĂ©sentĂ© en première page de la documentation. Ces dernières annĂ©es, les amĂ©liorations ont aussi portĂ© sur la manière de dĂ©ployer ses dĂ©veloppements avec Mathematica : le format CDF permet d’exporter des documents (le CDF Player peut exĂ©cuter les commandes incluses), Wolfram Cloud propose d’exĂ©cuter du code Mathematica dans le nuage.
La version 11 de cet environnement complet propose pas moins de 555 nouvelles fonctions (alors que la première version n’en contenait que 551), sans compter les nouvelles fonctionnalitĂ©s ajoutĂ©es aux fonctions prĂ©cĂ©dentes. Cependant, la rĂ©trocompatibilitĂ© est au cĹ“ur des dĂ©veloppements : tout programme Mathematica Ă©crit depuis la version 7 restera entièrement compatible avec les dernières versions (il n’y a plus eu de changement incompatible depuis lors) et bon nombre d’applications restent compatibles depuis la première version du logiciel, en 1988.
Cela est possible grâce au principe de cohĂ©rence dans la conception de l’interface des fonctions, dans le plus pur style fonctionnel : toute fonctionnalitĂ© est prĂ©vue pour rester dans la durĂ©e, ce qui permet de construire de nouvelles fonctionnalitĂ©s par-dessus. Quand les dĂ©veloppeurs n’ont pas achevĂ© une fonctionnalitĂ©, mais qu’elle peut dĂ©jĂ ĂŞtre utile aux diffĂ©rents utilisateurs, elle est proposĂ©e sous une forme expĂ©rimentale : elle est utilisable, mais il n’y a aucune garantie que l’interface restera inchangĂ©e (il faut d’ailleurs inclure spĂ©cifiquement des modules, ils ne sont pas disponibles par dĂ©faut).
Améliorations esthétiques
En ouvrant Mathematica 11 la première fois, on remarque vite les changements apportĂ©s Ă l’interface graphique, mĂŞme s’ils sont relativement mineurs. Les polices utilisĂ©es sont plus nettes et plus denses. L’autocomplĂ©tion a Ă©tĂ© amĂ©liorĂ©e, elle est plus contextuelle et fait des propositions y compris pour les options. De plus, chaque commande est maintenant annotĂ©e dans la langue de l’utilisateur, ce qui en facilite la comprĂ©hension pour ceux qui ne maĂ®trisent pas suffisamment l’anglais. Les messages d’erreur sont aussi plus instructifs et proposent Ă©galement d’afficher la pile d’appel au moment de l’erreur.
Impression 3D
L’une des nouvelles zones de fonctionnalitĂ©s de Mathematica est l’impression 3D. Les versions prĂ©cĂ©dentes pouvaient dĂ©jĂ exporter des gĂ©omĂ©tries en STL, mais la 11 propose toute la chaĂ®ne d’impression, depuis la crĂ©ation d’une gĂ©omĂ©trie 3D Ă son impression (par une machine locale ou par un prestataire externe) — en prenant en compte les limites techniques de l’impression 3D. Il devient ainsi possible d’imprimer tout graphique tridimensionnel, toute structure molĂ©culaire, toute partie de la Terre (par exemple, la gĂ©ographie autour d’une montagne).

Apprentissage automatique
Un des grands termes Ă la mode actuellement est l’apprentissage automatique (en anglais, machine learning), notamment tout ce qui a trait aux rĂ©seaux neuronaux et Ă l’apprentissage profond (Intel et NVIDIA se battent d’ailleurs sur la performance de leurs puces respectives pour l’apprentissage de rĂ©seaux neuronaux profonds). La version 10 de Mathematica avait dĂ©jĂ apportĂ© une interface très simple d’utilisation pour bon nombre de cas, avec les fonctions Classify[] et Predict[] pour la classification et la rĂ©gression (apprentissage supervisĂ©), en donnant accès Ă une foultitude d’algorithmes sous une interface unifiĂ©e (rĂ©gression linĂ©aire, logistique, forĂŞts alĂ©atoires, plus proches voisins, rĂ©seaux neuronaux, etc.).
Cette nouvelle version apporte Ă©galement une interface unifiĂ©e pour l’extraction de caractĂ©ristiques, la rĂ©duction de dimensionnalitĂ©, le groupement d’Ă©lĂ©ments, la dĂ©termination d’une loi de probabilitĂ©, l’apprentissage par renforcement. Une nouveautĂ© est aussi la mise Ă disposition de modèles dĂ©jĂ entraĂ®nĂ©s, par exemple pour la classification d’images selon leur contenu.

Du cĂ´tĂ© des rĂ©seaux neuronaux, Mathematica s’appuie sur ses capacitĂ©s symboliques de calcul pour proposer des rĂ©seaux reprĂ©sentĂ©s de manière symbolique : on peut alors associer n’importe quel genre de couche et visualiser les rĂ©seaux, mais aussi les entraĂ®ner sur des donnĂ©es (aussi sur GPU) et analyser leur performance, puisque ces rĂ©seaux sont stockĂ©s comme des graphes. Les couches de base sont dĂ©jĂ implĂ©mentĂ©es (combinaison linĂ©aire d’entrĂ©es, fonctions d’activation sigmoĂŻdes), tout comme les dĂ©veloppements rĂ©cents de l’apprentissage profond (autoencodeurs, rĂ©seaux convolutionnels). Les rĂ©seaux rĂ©currents sont en cours de dĂ©veloppement, mais pas encore prĂŞts.
GĂ©ographie
Travailler sur la gĂ©ographie de la Terre et d’autres planètes n’est pas toujours Ă©vident, puisqu’elle n’est pas plate. Mathematica ne fait pas que donner accès aux informations sur bon nombre de planètes, il dispose aussi de fonctions pour effectuer des calculs sur ces gĂ©omĂ©tries particulières : il dispose d’une bonne collection de projections gĂ©ographiques, pour proposer des calculs prĂ©cis de gĂ©odĂ©sie. Ces capacitĂ©s s’Ă©tendent aussi aux cartes, avec l’accès aux dĂ©tails de chaque rue, mais aussi les frontières historiques de chaque pays et des images satellites de basse rĂ©solution.
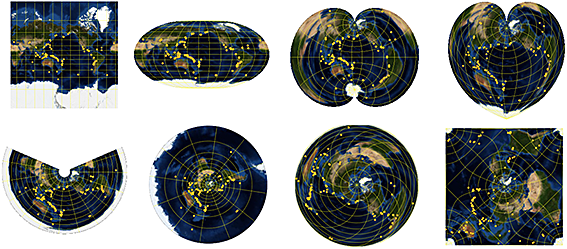
Calculs numériques
Au niveau numĂ©rique, il devient possible de rĂ©soudre des Ă©quations diffĂ©rentielles (y compris aux dĂ©rivĂ©es partielles) par leurs valeurs propres dans n’importe quel domaine, y compris en spĂ©cifiant des conditions aux limites. Ces solveurs sont totalement gĂ©nĂ©riques : il n’y a pas besoin de connaissances poussĂ©es en algorithmique numĂ©rique, Mathematica dĂ©termine seul une bonne manière de rĂ©soudre le problème donnĂ©. Ces systèmes fonctionnent en s’intĂ©grant avec les fonctionnalitĂ©s gĂ©omĂ©triques prĂ©existantes, ce qui permet notamment d’Ă©tudier la rĂ©ponse d’une peau de tambour qui aurait la forme des États-Unis.
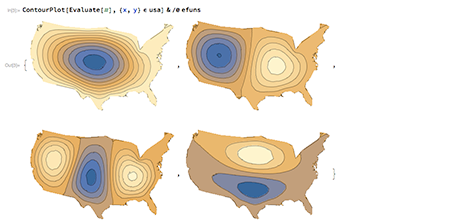
Dans des domaines connexes, le calcul symbolique fait encore des progrès : il devient maintenant possible de rĂ©soudre de manière symbolique un grand nombre d’Ă©quations aux dĂ©rivĂ©es partielles qui apparaissent dans les manuels, mais aussi des Ă©quations mĂ©langeant des dĂ©rivĂ©es et des intĂ©grales. CĂ´tĂ© numĂ©rique, les fonctions d’optimisation ont vu leur performance et leur robustesse amĂ©liorĂ©es, ce qui sert notamment aux fonctionnalitĂ©s d’apprentissage automatique.
Programmation généraliste
MĂŞme si Mathematica n’a pas commencĂ© comme un langage de programmation gĂ©nĂ©raliste, il s’Ă©tend Ă©galement dans cette direction. Ainsi, il peut maintenant travailler sur des sĂ©quences d’octets bruts reçus sur un socket, effectuer des mesures sur un rĂ©seau (Ping pour le moment). La cryptographie fait son apparition, tant symĂ©trique qu’asymĂ©trique.
Source et images : Today We Launch Version 11!.
Voir aussi : toutes les nouveautés depuis Mathematica 10.4, mise en contexte de certaines nouveautés.
Qt Creator 4.1 vient de sortir. Cette version mineure apporte pas mal d’amĂ©liorations incrĂ©mentales Ă l’EDI, sans le rĂ©volutionner. Notamment, deux nouveaux thèmes ont Ă©tĂ© ajoutĂ©s (l’un foncĂ©, l’autre clair), ainsi que deux nouveaux jeux de couleurs pour la coloration syntaxique (basĂ©s sur la palette Solarized).
Au niveau fonctionnel, les Ă©diteurs de texte gèrent nettement mieux l’insertion et le saut de caractères : en tapant un guillemet, une parenthèse, un crochet ou une accolade ouvrant, le caractère fermant est automatiquement insĂ©rĂ© juste après ; si l’utilisateur supprime le premier caractère, celui que Qt Creator a ajoutĂ© est supprimĂ© ; si on tape le caractère fermant quand le curseur est Ă son niveau, cette frappe remplace le caractère insĂ©rĂ©. Cependant, ces comportements (attendus par bon nombre d’utilisateurs habituĂ©s Ă d’autres outils) peuvent ĂŞtre configurĂ©s.
Le modèle de code Clang et l’analyseur statique associĂ© utilisent maintenant une version bien plus rĂ©cente de la bibliothèque-compilateur, la 3.8.1, qui rĂ©sout bon nombre de dĂ©fauts. Les problèmes entre Clang et Visual C++, dĂ©tectĂ©s lors de la publication de la RC 1, ont Ă©tĂ© rĂ©solus.
Une autre nouveautĂ©, probablement moins attendue, est une extension pour le langage Nim : elle contient la coloration syntaxique, l’indentation, les styles de code. Il est aussi possible de compiler, de lancer et de dĂ©boguer des applications Nim.
Voir aussi : la liste des changements complète.
Télécharger Qt Creator 4.1.0.
Source : Qt Creator 4.1.0 released.
Merci Ă Claude Leloup pour ses corrections.
KDE est, historiquement, le premier utilisateur dans le monde du libre de Qt. Cet environnement de bureau pour Linux (et autres) s’est construit exclusivement sur la bibliothèque pour son interface graphique. Au fil des annĂ©es, pour Ă©viter la duplication de code entre les diverses applications, certains composants ont Ă©tĂ© rassemblĂ©s dans des bibliothèques d’extension de Qt, d’abord nommĂ©es kdelibs (prĂ©vues exclusivement pour KDE), puis rĂ©cemment transformĂ©es en KDE Frameworks dès KDE 5 : les dĂ©veloppeurs ont voulu faciliter la rĂ©utilisation de composants dĂ©veloppĂ©s pour KDE dans des applications Qt tout Ă fait dĂ©couplĂ©es de KDE.
Qt Quick prend de plus en plus d’ampleur cĂ´tĂ© KDE, notamment pour le dĂ©veloppement des plasmoĂŻdes (de petites applications, affichĂ©es au niveau du bureau de KDE), mais Ă©galement pour les applications Plasma Mobile (KDE sur tĂ©lĂ©phone portable). Pour faciliter ces dĂ©veloppements, il a donc Ă©tĂ© dĂ©cidĂ© de crĂ©er une bibliothèque qui rassemble bon nombre de composants utiles, des briques plus grandes que celles fournies de base par Qt Quick dans le module Qt Quick Components. Il s’agit de Kirigami, qui suit de près la philosophie dĂ©finie par le projet : une application utilisant Kirigami aura accès Ă bon nombre de composants graphiques formant un tout cohĂ©rent et intuitif pour l’utilisateur.
Parmi les concepts les plus importants de Kirigami, on peut compter :
Cette description fait d’office penser que Kirigami est optimisĂ© pour l’utilisation sur des tĂ©lĂ©phones portables. De fait, l’un des principes directeurs Ă©tait que toute application devait ĂŞtre facile Ă utiliser avec une seule main. Cependant, la bibliothèque est aussi prĂ©vue pour rĂ©aliser des interfaces convergentes, qui s’adaptent Ă la taille de l’Ă©cran (et pas seulement avec une mise Ă l’Ă©chelle) : la mĂŞme application s’adaptera Ă la taille disponible sur ordinateur et aux stimuli disponibles.
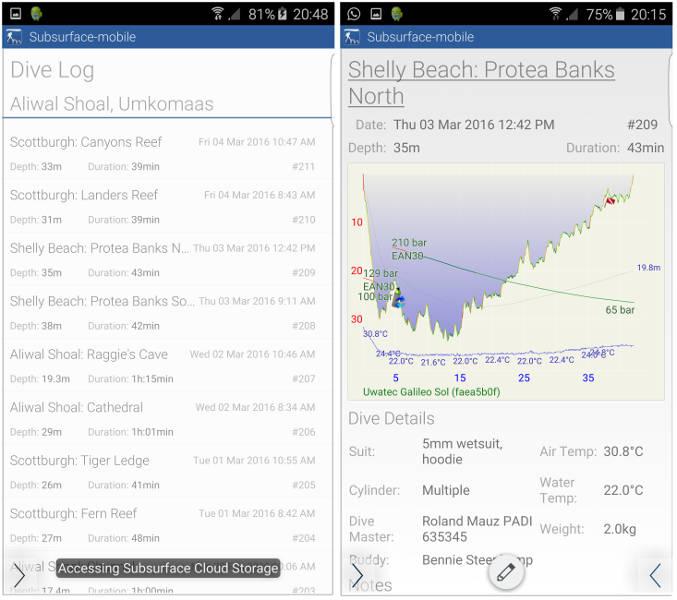
La première application Ă l’utiliser est la version mobile de Subsurface, passĂ© Ă Qt il y a deux ans. Une application Android est disponible, la version iOS est en cours de dĂ©veloppement et partage presque l’entièretĂ© du code de la version Android (ce qui est un avantage revendiquĂ© par Qt Quick en gĂ©nĂ©ral).
CĂ´tĂ© technique, Kirigami est compatible avec Android, Linux (tant X11 que Wayland) sur plateformes de bureau, Windows, ainsi que Plasma Mobile. La version iOS est actuellement expĂ©rimentale, tandis que que celle pour Ubuntu Touch est en travaux. Kirigami n’est pas encore intĂ©grĂ©e Ă KDE Framework 5, mais cela ne devrait pas tarder, en tant que module de premier niveau (c’est-Ă -dire que la seule dĂ©pendance est Qt).
Source : KDE’s Kirigami UI Framework Gets its First Public Release.
Qt 5.7 est arrivĂ© avec quelques nouveaux modules relativement expĂ©rimentaux, notamment Qt Gamepad. Comme son nom l’indique, ce module se destine principalement aux jeux et permet d’utiliser des manettes de jeu directement depuis Qt, c’est-Ă -dire des mĂ©canismes d’entrĂ©e avec des boutons, des contrĂ´les directionnels (comme un manche Ă balai) et parfois des touches. Ce module fournit tant une interface C++ que QML (ce qui est monnaie courante dans les nouveaux dĂ©veloppements, comme Qt 3D). Son API n’est pas encore finalisĂ©e (le module reste expĂ©rimental) et pourrait Ă©voluer dans les versions de Qt Ă venir. Au niveau de la compatibilitĂ©, l’implĂ©mentation utilise les API systèmes de Linux, Windows, macOS, iOS et Android, mais aussi la SDL.

Le module se dĂ©compose principalement en trois classes, cĂ´tĂ© C++. Le singleton QGamepadManager liste les manettes connectĂ©es et reconnues (accessibles individuellement par QGamepad) et offre un accès de haut niveau aux Ă©vĂ©nements gĂ©nĂ©rĂ©s par toutes les manettes. QGamepadKeyNavigation se spĂ©cialise dans les signaux d’appui sur les touches. Les composants QML (disponibles dans le module QtGamepad 1.0) portent des noms identiques.
La documentation est assez Ă©parse pour le moment (une seule classe C++, rien cĂ´tĂ© Qt Quick), ICS propose donc un exemple d’utilisation, exploitant QGamepadManager (au lieu de QGamepad, comme dans les exemples fournis avec Qt 5.7). Celui-ci montre comment lister les manettes disponibles, puis connecte des signaux Ă chaque Ă©vĂ©nement possible pour en afficher les dĂ©tails.
Source, image et code source : What’s New in Qt 5.7.0: Qt Gamepad.
Merci Ă Claude Leloup pour ses corrections.
Ă€ la sortie de Qt 5.0 et de Qt Quick 2, en 2012, l’un des grands changements du cĂ´tĂ© du rendu Ă©tait l’utilisation exclusive d’OpenGL 2.0 : OpenGL Ă©tait vu, Ă l’Ă©poque, comme l’API de choix pour le rendu matĂ©riel, peu importe la plateforme (Windows, Linux, macOS, mais aussi sur mobile et dans l’embarquĂ©, avec sa dĂ©clinaison OpenGL ES). Cependant, depuis lors, le paysage s’est fortement complexifiĂ©.
La solution actuelle ne fonctionne plus
D’un cĂ´tĂ©, les API de dernières gĂ©nĂ©ration ont des concepts radicalement diffĂ©rents (et l’OpenGL nouveau a mĂŞme changĂ© de nom : Vulkan). De plus, cĂ´tĂ© embarquĂ©, les processeurs sans GPU OpenGL sont lĂ©gion, ce qui interdit le dĂ©ploiement d’applications Qt Quick (Ă moins d’utiliser une extension autrefois payante, Qt Quick 2D Renderer, compatible avec Qt 5.4 et plus rĂ©cents). Sur Windows en particulier, l’Ă©tat des pilotes OpenGL n’Ă©tait pas toujours excellent (surtout sur les machines oĂą les pilotes graphiques ne sont pas Ă jour), ce qui impactait directement les applications Qt Quick : dès Qt 5.4, il Ă©tait possible de choisir, Ă l’exĂ©cution, d’utiliser ANGLE (une implĂ©mentation d’OpenGL par-dessus DirectX) ou llvmpipe (une implĂ©mentation purement logicielle d’OpenGL).
Ces solutions ne sont en rĂ©alitĂ© que des emplâtres sur une jambe de bois : un rendu purement logiciel n’est pas envisageable dans bon nombre de situations oĂą la puissance de calcul n’est pas suffisante ; Qt Quick ne peut pas exploiter des API natives, mieux gĂ©rĂ©es sur chaque plateforme… surtout que le nombre d’API disponibles a fortement augmentĂ©. En effet, le choix ne se porte plus entre Direct3D et OpenGL, notamment puisque les API modernes, de plus bas niveau, sont au nombre de trois : celle d’Apple (Metal), celle de Microsoft (Direct3D 12) et la seule norme multiplateforme (Vulkan). De plus, pour l’ingĂ©nierie logicielle, Qt Quick 2D Renderer ne s’intègre pas bien au reste de Qt Quick (il s’agit d’un module sĂ©parĂ©).
Une nouvelle génération plus modulaire
Un des objectifs de Qt 5.8 est de refactoriser le code de rendu cĂ´tĂ© Qt Quick, c’est-Ă -dire de le dĂ©coupler d’OpenGL… de le modulariser (c’Ă©tait le mot clĂ© lors du dĂ©veloppement de Qt 5). Ainsi, il devient possible d’utiliser de nouvelles API pour le rendu des scènes Qt Quick, en implĂ©mentant une extension qui effectuera la traduction entre le graphe de scène et l’API de rendu. Tout comme il Ă©tait possible, sous Windows, de passer d’OpenGL Ă ANGLE Ă l’exĂ©cution, il sera possible de changer d’API Ă l’exĂ©cution. Grâce Ă l’utilisation d’une reprĂ©sentation assez abstraite de la scène Ă afficher, chaque extension n’a pas beaucoup de contraintes Ă respecter dans son implĂ©mentation, ce qui permettra de l’utiliser Ă son plein potentiel.
Cette Ă©tape ne fait pas que dĂ©placer des monceaux de code d’un bout Ă l’autre : des parties de l’implĂ©mentation du graphe de scène Ă©taient extrĂŞmement liĂ©es Ă OpenGL. Cela a forcĂ© les dĂ©veloppeurs Ă marquer certaines parties de l’interface publique de Qt comme dĂ©sapprouvĂ©es dès Qt 5.8, de nouvelles API sans ces gĂŞnantes dĂ©pendances envers OpenGL sont en cours de dĂ©veloppement pour les remplacer. Sont notamment concernĂ©s les systèmes des matĂ©riaux et des particules… mais aussi bon nombre de fichiers d’en-tĂŞte dans l’implĂ©mentation de Qt Quick : le code C++ incluait ceux d’OpenGL, mĂŞme si le module Qt Quick 2D Renderer s’occupait de l’affichage (la solution Ă©tait de dĂ©finir des fichiers d’en-tĂŞte minimaux pour que le code compile — ce qui faisait planter l’application Ă toute tentative d’appel Ă OpenGL, forcĂ©ment impossible).
Direct3D 12 sera le premier concernĂ© par cette refactorisation en profondeur : une extension expĂ©rimentale sera livrĂ©e avec Qt 5.8 (Ă cĂ´tĂ© de celle pour OpenGL, qui garantit la compatibilitĂ© avec le code existant), utilisable tant pour les applications traditionnelles (Win32) qu’universelles (UWP). MĂŞme si deux gros dĂ©veloppeurs derrière Qt (la Qt Company et KDAB) sont membres du consortium Khronos « pour promouvoir Vulkan », il n’y aura pas d’extension pour le moment.
Un moteur de rendu logiciel aux vitamines
Par la mĂŞme occasion, le moteur de rendu logiciel (ex-Qt Quick 2D Renderer) est retravaillĂ©, notamment au niveau de la performance. Le point principal qui arrivera avec Qt 5.8 est la possibilitĂ© de mettre Ă jour partiellement chaque image affichĂ©e, selon les parties qui ont rĂ©ellement changĂ© dans la scène. Ainsi, une animation qui Ă©tait autrefois très coĂ»teuse en CPU (une partie pour l’animation elle-mĂŞme, une plus grosse encore pour redessiner entièrement l’Ă©cran Ă chaque image) deviendra accessible.
L’intĂ©gration avec des interfaces Ă base de widgets avec QQuickWidget sera aussi possible : des applications comme Qt Creator (qui utilisent la classe QQuickWidget) ne pouvaient donc pas utiliser ce moteur de rendu logiciel. Maintenant que le rendu est implĂ©mentĂ© au plus près de Qt Quick, le transfert des images entre Qt Quick et les widgets devient possible.
Source : The Qt Quick Graphics Stack in Qt 5.8.
Merci Ă Claude Leloup pour ses corrections.
Le projet continue Ă revivre, entièrement dans la communautĂ© (sans soutien de la part des dĂ©veloppeurs principaux de Qt) : Qt WebKit nouvelle gĂ©nĂ©ration voit une troisième prĂ©version technique (TP3) arriver. L’une des grandes nouveautĂ©s de cette version est la compatibilitĂ© avec les extensions NPAPI et Qt (uniquement pour Windows et X11, pas de macOS pour le moment).
Une partie du travail a consistĂ© Ă s’approcher du niveau de fonctionnalitĂ© de Qt WebKit : les balises <object> et <embed> peuvent gĂ©rer du contenu avec des images, l’Ă©lĂ©ment <progress> fonctionne comme attendu, les liens <a> peuvent utiliser l’attribut download. L’API Web SQL Database Ă©tait malencontreusement dĂ©sactivĂ©, ce qui est corrigĂ©.
Aussi, les dĂ©veloppeurs ont ajoutĂ© d’autres fonctionnalitĂ©s par rapport au module Qt WebKit prĂ©cĂ©dent : les Ă©vĂ©nements DOM de niveau 4, la propriĂ©tĂ© CSS -webkit-initial-letter (qui nĂ©cessite Qt 5.8, les raccourcis pour les polices système.
De manière plus générale, la plupart des modifications proposées sur Gerrit depuis Qt 5.2 ont été intégrées : bon nombre de défauts avaient été corrigés par la communauté, sans être intégrés dans le code de Qt WebKit. Il devient aussi possible de compiler Qt WebKit NG sous forme statique, avec les bibliothèques statiques de Qt.
© 2000-2020 - www.developpez.com
Partenaire : Hébergement Web