NVIDIA en parle depuis un certain temps et dégaine, peu après AMD, sa nouvelle générations de processeurs graphiques, dénommée Pascal, un nom qui fait référence à Blaise Pascal, mathématicien et physicien français du XVIIe siècle. Les chiffres bruts donnent déjà le tournis : un tel GPU est composé de dix-huit milliards de transistors (huit milliards pour la génération précédente, Maxwell).
Sur la technique, ce GPU (nommĂ© GP100) est le premier gravĂ© en 16 nm, avec la technologie FinFET+ de TSMC, les prĂ©cĂ©dents l’Ă©taient en 28 nm. Pour un processus aussi rĂ©cent, la puce est Ă©norme : 610 mm², Ă comparer au 600 mm² de Maxwell sur un processus bien maĂ®trisĂ©. Cette surface est utilisĂ©e pour les 3840 cĹ“urs de calcul (3072 pour Maxwell), ayant accès Ă un total de 14 Mo de mĂ©moire cache (6 Mo pour Maxwell). Les cĹ“urs ont aussi augmentĂ© en frĂ©quence : 1,5 GHz au lieu de 1,1 pour Maxwell. Au niveau de la mĂ©moire principale, la technologie HBM2 est utilisĂ©e au lieu de la mĂ©moire traditionnelle GDDR5. Une puce Pascal dispose de seize gigaoctets de mĂ©moire (contre douze, il n’y a pas si longtemps, chez Maxwell, maintenant vingt-quatre).
NVIDIA peut donc en profiter pour intĂ©grer bon nombre de nouvelles fonctionnalitĂ©s, tournĂ©es vers le segment HPC, comme sa connectique NVLink. L’une des fonctionnalitĂ©s très utiles pour monter en performance concerne les nombres Ă virgule flottante : contrairement Ă Maxwell, les unitĂ©s de calcul de Pascal traitent nativement des nombres sur soixante-quatre bits et seize bits ; ainsi, une telle puce peut monter jusque vingt et un mille milliards d’opĂ©rations par seconde (21 TFlops) en seize bits, cinq mille milliards en soixante-quatre bits (avec un facteur d’Ă peu près quatre entre les deux : les unitĂ©s sur soixante-quatre bits sont grosso modo composĂ©es de quatre unitĂ©s sur seize bits).
Toujours dans le HPC, la mĂ©moire unifiĂ©e, entre la mĂ©moire principale de l’ordinateur et celle du processeur graphique, a aussi vu quelques amĂ©liorations. Elles se comptent au nombre de deux. Tout d’abord, l’espace d’adressage a Ă©tĂ© considĂ©rablement Ă©largi, ce qui permet d’adresser toute la mĂ©moire centrale et celle du GPU (et non seulement un espace Ă©quivalent Ă la mĂ©moire du GPU). Ensuite, les GPU Pascal gèrent les dĂ©fauts de page : si un noyau de calcul tente d’accĂ©der Ă une page mĂ©moire qui n’est pas encore chargĂ©e sur le GPU, elle le sera Ă ce moment-lĂ , elle ne doit plus ĂŞtre copiĂ©e dès le lancement des calculs sur le GPU.

L’apprentissage profond, le cheval de bataille de NVIDIA
Toutes ces avancĂ©es sont jusque maintenant principalement prĂ©vues pour le marchĂ© du HPC, plus particulièrement de l’apprentissage de rĂ©seaux neuronaux profonds, Ă l’origine de miracles rĂ©cents dans le domaine de l’intelligence artificielle.
NVIDIA avance un facteur d’accĂ©lĂ©ration de douze dans un cas d’apprentissage d’un rĂ©seau neuronal avec sa nouvelle architecture par rapport Ă ses meilleurs rĂ©sultats l’annĂ©e dernière. Ce facteur est Ă©norme en seulement une annĂ©e, mais il faut remarquer que la comparaison proposĂ©e n’est pas toujours Ă©quitable : les nouveaux tests utilisent deux fois plus de GPU que l’annĂ©e dernière, de nouvelles fonctionnalitĂ©s ont fait leur apparition sur les GPU spĂ©cifiquement pour accĂ©lĂ©rer ce genre de calculs (les nombres Ă virgule flottante sur seize bits). Il n’empĂŞche, le rĂ©sultat reste impressionnant.
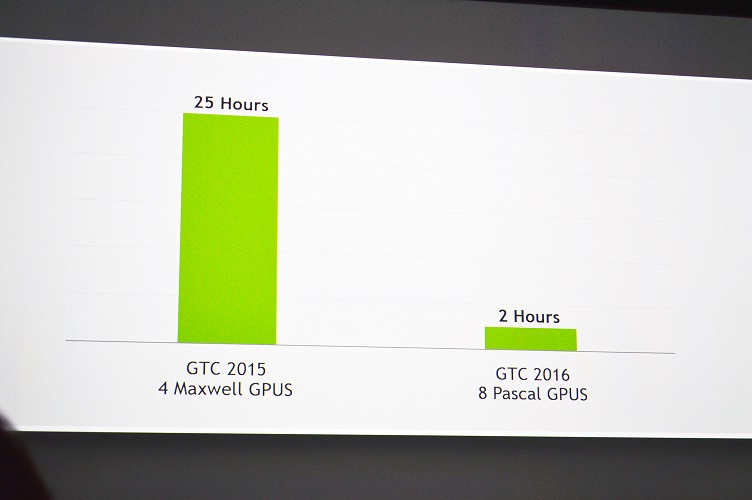
Ces avancées réunissent cinq « miracles », selon la terminologie de Jen-Hsun Huang :
- la nouvelle architecture Pascal ;
- la technologie de gravure de puces de TSMC ;
- la nouvelle génération de puces mémoire empilées (HBM2) ;
- la technologie d’interconnexion entre GPU NVLink ;
- des améliorations algorithmiques pour tirer parti des progrès précédents.

NVIDIA DGX-1, un supercalculateur dans une boîte
Les tests de performance ont Ă©tĂ© effectuĂ©s sur une machine assemblĂ©e par NVIDIA, dĂ©nommĂ©e DGX-1, un monstre de puissance. Elle couple deux processeurs Intel Xeon E5-2698 v3 et huit processeurs NVIDIA Pascal avec 512 Go de mĂ©moire vive et 1,92 To de stockage en SSD. Globalement, la machine peut fournir 170 TFlops pour la modique somme de 129 000 $. NVIDIA la rĂ©sume comme deux cent cinquante serveurs rassemblĂ©s dans un boĂ®tier. Elle est d’ores et dĂ©jĂ en vente, mais les livraisons devraient dĂ©buter en juin. Des bibliothèques existantes ont Ă©tĂ© adaptĂ©es pour cette machine pour en tirer le meilleur parti, comme TensorFlow de Google.

CUDA 8 et autres avancées logicielles
Pascal vient avec des amĂ©liorations matĂ©rielles accessibles par CUDA 8, la nouvelle version de l’API de calcul sur GPU de NVIDIA. Par exemple, les opĂ©rations atomiques en mĂ©moire, utiles pour les opĂ©rations en parallèle sur une mĂŞme case mĂ©moire sans risque de corruption, gèrent plus d’opĂ©rations sur les entiers (en parallèle avec une implĂ©mentation matĂ©rielle plus complète). Les dĂ©veloppeurs peuvent exploiter une structure d’interconnexion NVLink explicitement depuis CUDA.
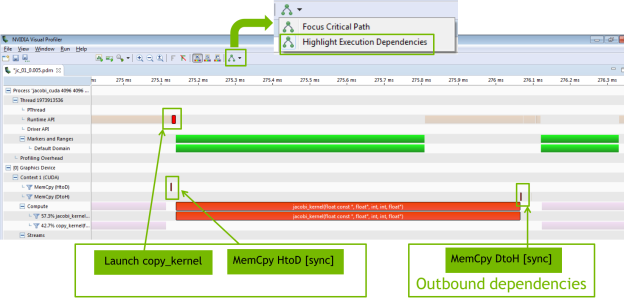
Le profilage d’applications est encore amĂ©liorĂ©, notamment au niveau de la rĂ©partition de la charge entre le CPU et le GPU, pour dĂ©terminer les parties oĂą l’optimisation serait la plus bĂ©nĂ©fique globalement. Pour ce faire, le profileur visuel montre maintenant les dĂ©pendances entre les noyaux de calcul du GPU et les appels Ă l’API CUDA, afin de faciliter la recherche d’un chemin critique d’exĂ©cution.
De nouvelles bibliothèques font Ă©galement leur apparition au sein de l’Ă©cosystème, comme nvGRAPH pour l’analyse de graphes : la planification du chemin d’un robot dans un graphe Ă©norme (comme une voiture dans le rĂ©seau routier), l’analyse de grands jeux de donnĂ©es (rĂ©seaux sociaux, gĂ©nomique, etc.). NVIDIA IndeX, une bibliothèque de visualisation de très grands jeux de donnĂ©es (rĂ©partis sur plusieurs GPU), est maintenant disponible comme extension Ă ParaView. cuDNN arrive en version 5, avec d’importantes amĂ©liorations de performance.
Sources : Pascal Architecture (images d’illustration), Nvidia Pascal Architecture & GP100 Specs Detailed – Faster CUDA Cores, Higher Thread Throughput, Smarter Scheduler & More, NVIDIA DGX-1 Pascal Based Supercomputer Announced – Features 8 Tesla P100 GPUs With 170 TFLOPs Compute, NVIDIA GTC 2016 Keynote Live Blog (transparents NVIDIA), Inside Pascal: NVIDIA’s Newest Computing Platform, CUDA 8 Features Revealed.