L’apprentissage profond et les rĂ©seaux neuronaux sont Ă la mode pour le moment dans le domaine de l’apprentissage automatique : Google, NVIDIA et plus rĂ©cemment Microsoft proposent des bibliothèques, plus ou moins ouvertes, pour faciliter leur utilisation.
De fait, l’apprentissage profond accumule les succès ces derniers temps, y compris pour battre des humains au jeu de go — mĂŞme si le meilleur joueur au monde, selon les classements actuels, Lee Sedol, estime encore pouvoir battre ce système d’intelligence artificielle. L’intĂ©rĂŞt du jeu de go est sa complexitĂ©, malgrĂ© des règles relativement simple : il existe approximativement parties de go, contre « Ă peine »
parties de jeu d’Ă©checs (un nombre bien plus abordable actuellement).
Apprentissage d’un rĂ©seau
Cependant, de manière thĂ©orique, rien ne pouvait justifier les succès des rĂ©seaux neuronaux, qui sont l’outil principal derrière l’apprentissage profond. Depuis la première vague d’intĂ©rĂŞt de la part du monde acadĂ©mique, dans les annĂ©es 1990, leur Ă©tude avait montrĂ© la prĂ©sence de nombreux minima locaux de l’erreur totale. L’apprentissage d’un rĂ©seau neuronal se fait en dĂ©finissant la pondĂ©ration des entrĂ©es de chaque neurone : changer un peu ces poids peut avoir un grand impact sur la prĂ©diction du rĂ©seau.
Pour choisir cette pondĂ©ration, tous les algorithmes testent le rĂ©seau sur des donnĂ©es pour lesquelles le rĂ©sultat est connu : par exemple, un son et les mots auxquels il correspond ; la diffĂ©rence correspond Ă l’erreur commise par le rĂ©seau. La prĂ©sence de ces minima locaux signifie que, une fois l’exĂ©cution de l’algorithme terminĂ©e, la pondĂ©ration n’est pas forcĂ©ment idĂ©ale : en changeant quelques valeurs, il peut ĂŞtre possible de diminuer drastiquement l’erreur totale. L’objectif des algorithmes d’apprentissage est d’atteindre le minimum global d’erreur.
Premières analyses et verre de spin
Jusqu’Ă prĂ©sent, l’analyse thĂ©orique des rĂ©seaux neuronaux s’Ă©tait portĂ©e sur des rĂ©seaux de quelques neurones : ces minima locaux sont alors prĂ©sents en grand nombre et sont assez Ă©loignĂ©s les uns des autres. Cette caractĂ©ristique menace alors la performance des rĂ©seaux, puisque le minimum local après apprentissage peut ĂŞtre très Ă©loignĂ© du minimum global.
Ce comportement correspond, en physique, Ă celui des verres de spin, « des alliages mĂ©talliques comportant un petit nombre d’impuretĂ©s magnĂ©tiques disposĂ©es au hasard dans l’alliage » : l’Ă©nergie du matĂ©riau dĂ©pend fortement de la configuration des impuretĂ©s, qui prĂ©sente un grand nombre de minima locaux Ă©loignĂ©s du minimum globale. Ce verre de spin est alors coincĂ© dans une configuration dite mĂ©tastable : en rĂ©organisant très lĂ©gèrement les impuretĂ©s, l’Ă©nergie globale pourrait baisser assez fortement.
Nouvelles analyses
Le seul rĂ©sultat thĂ©orique dont on disposait jusque l’annĂ©e dernière Ă©tait que certains rĂ©seaux neuronaux correspondent exactement aux verres de spin. Cependant, le rĂ©sultat obtenu par l’Ă©quipe de Yann LeCun (directeur du laboratoire d’intelligence artificielle de Facebook) montre, au contraire, que, pour un très grand nombre de neurones, la fonction d’erreur a plutĂ´t la forme d’un entonnoir : les minima locaux sont très rapprochĂ©s du minimum global. Plus le rĂ©seau est grand, plus ces points sont rassemblĂ©s autour du minimum global. Or, justement, l’apprentissage profond propose d’utiliser un très grand nombre de ces neurones, plusieurs millions : le rĂ©sultat d’un apprentissage n’est donc jamais loin du minimum global.
Plus prĂ©cisĂ©ment, les algorithmes d’apprentissage convergent vers des points critiques. Les chercheurs ont montrĂ© que la majoritĂ© de ces points critiques sont en rĂ©alitĂ© des points de selle et non des minima : ils correspondent Ă une zone plate, avec des directions montantes et descendantes. Il est donc relativement facile de s’en Ă©chapper, en suivant la direction descendante (en termes d’erreur). Globalement, les vrais minima (qui correspondent Ă des cuvettes : seulement des directions qui augmentent l’erreur) sont assez rares — et proches de la meilleure valeur possible.
Physiquement, les rĂ©seaux neuronaux correspondent donc plus Ă des « entonnoirs de spin », avec des formes plus sympathiques : l’Ă©nergie de la configuration varie de manière abrupte, sans vĂ©ritablement offrir de minimum local. Ces matĂ©riaux trouvent bien plus facilement leur configuration native (avec une Ă©nergie minimale).
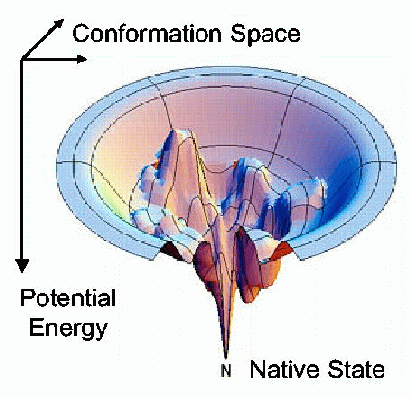
Ces rĂ©sultats confirment donc que des techniques comme la descente de gradient stochastique (SGD) peuvent fonctionner : la fonction d’erreur d’un rĂ©seau neuronal est Ă peu près convexe. Cependant, les rĂ©seaux modernes sont souvent plus complexes que ceux Ă©tudiĂ©s, afin d’Ă©viter le surapprentissage (correspondre trop bien aux donnĂ©es pour l’apprentissage, mais avoir du mal Ă reconnaĂ®tre des donnĂ©es qui n’en font pas partie).
NĂ©anmoins, la chimie thĂ©orique et la physique de la matière condensĂ©e proposent d’ores et dĂ©jĂ un panel d’outils mathĂ©matiques pour comprendre la structure de ces entonnoirs de spin et des variations plus complexes, notamment dans le cas du pliage de protĂ©ines (elles prennent une forme qui minimise cette Ă©nergie). Cette Ă©tude propose ainsi de nouveaux mĂ©canismes d’Ă©tude des rĂ©seaux neuronaux, mais peut-ĂŞtre aussi de nouveaux algorithmes d’apprentissage ou techniques pour Ă©viter le surapprentissage.
Sources : C’est la fin d’une croyance sur les rĂ©seaux de neurones, Why does Deep Learning work? (image).
Plus de détails : The Loss Surfaces of Multilayer Networks, Why does Deep Learning work?, The Renormalization Group.