Il y a peu, Google a mis Ă disposition des dĂ©veloppeurs TensorFlow, sa solution d’apprentissage profond, une technique d’apprentissage automatique qui exploite principalement des rĂ©seaux neuronaux de très grande taille : l’idĂ©e est de laisser l’ordinateur trouver lui-mĂŞme, dans sa phase d’apprentissage, des abstractions de haut niveau par rapport aux donnĂ©es disponibles. Par exemple, pour reconnaĂ®tre des chiffres dans des images, ces techniques dĂ©termineront une manière d’analyser l’image, d’en rĂ©cupĂ©rer les Ă©lĂ©ments intĂ©ressants, en plus de la manière de traiter ces caractĂ©ristiques et d’en infĂ©rer le chiffre qui correspond Ă l’image.
Microsoft vient tout juste d’annoncer sa solution concurrente, nommĂ©e CNTK (computational network toolkit), elle aussi disponible gratuitement sous une licence libre de type MIT sur GitHub. Cette annonce poursuit la sĂ©rie d’ouvertures de code annoncĂ©es par Microsoft dernièrement, comme ChakraCore, son moteur JavaScript.
Ces dĂ©veloppements ont eu lieu dans le cadre de la recherche sur la reconnaissance vocale : les Ă©quipes de Microsoft estimaient que les solutions actuelles avaient tendance Ă les ralentir dans leurs avancĂ©es. Quelques chercheurs se sont lancĂ©s dans l’aventure d’Ă©crire eux-mĂŞmes un code de rĂ©seaux neuronaux très efficace, accĂ©lĂ©rĂ© par GPU… et leurs efforts ont portĂ© leurs fruits, puisque, selon leurs tests, CNTK est plus efficace que Theano, TensorFlow, Torch7 ou Caffe, les solutions les plus avancĂ©es dans le domaine du logiciel libre.
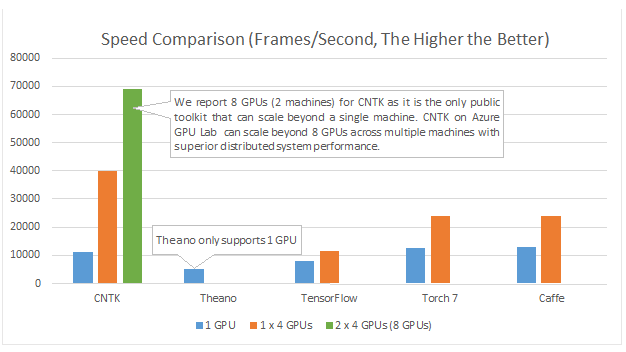
Microsoft n’est pas la seule sociĂ©tĂ© Ă beaucoup parier sur les GPU : NVIDIA Ă©galement croit fort aux GPU pour accĂ©lĂ©rer l’apprentissage profond. Pour la sortie de la dernière version de CUDA, la solution de NVIDIA pour le calcul sur GPU, leur bibliothèque cuDNN proposait un gain d’un facteur deux pour l’apprentissage d’un rĂ©seau.
L’avantage des GPU dans le domaine est multiple. Tout d’abord, leur architecture s’adapte bien au type de calculs Ă effectuer. Ensuite, ils proposent une grande puissance de calcul pour un prix raisonnable : pour obtenir la mĂŞme rapiditĂ© avec des processeurs traditionnels (CPU), il faudrait dĂ©bourser des milliers d’euros, par rapport Ă une carte graphique Ă plusieurs centaines d’euros Ă ajouter dans une machine existante. Ainsi, les moyens Ă investir pour commencer Ă utiliser les techniques d’apprentissage profonds sont relativement limitĂ©s. Cependant, la mise Ă l’Ă©chelle est plus difficile : l’apprentissage sur plusieurs GPU en parallèle est relativement difficile, toutes les bibliothèques ne le permettent pas. Pour rĂ©aliser de vĂ©ritables progrès algorithmiques, il faut sortir le carnet de chèques, avec des grappes de machines, nettement moins abordables.
Source : Microsoft releases CNTK, its open source deep learning toolkit, on GitHub.