La simulation de fluides (plus connue sous le sigle anglophone CFD, computational fluid dynamics) apparaĂ®t dans un grand nombre d’applications d’ingĂ©nierie : il s’agit de dĂ©terminer, par ordinateur, par exemple, l’Ă©coulement de l’air autour d’avions ou de voitures de formule 1. Ainsi, les concepteurs peuvent adapter leurs pièces, notamment pour en amĂ©liorer l’aĂ©rodynamisme. Les calculs requis sont extrĂŞmement poussĂ©s (Ă©quations aux dĂ©rivĂ©es partielles non linĂ©aires) et requièrent une grande puissance de calcul.
Un grand nombre de logiciels existe dĂ©jĂ pour rĂ©soudre ces problèmes, comme OpenFOAM dans le monde du logiciel libre. Cependant, ils n’exploitent pas tous les accĂ©lĂ©rateurs disponibles pour ces calculs (OpenFOAM nĂ©cessite des extensions pour ce faire), comme les processeurs graphiques (GPU), Ă la mode dans le monde du calcul scientifique (HPSC) : l’intĂ©rĂŞt est de bĂ©nĂ©ficier d’un très grand nombre de cĹ“urs. En effet, un processeur traditionnel a au plus une vingtaine de cĹ“urs par processeur : par exemple, dix-huit chez Intel). Un GPU en compte dĂ©sormais plusieurs milliers (tant chez NVIDIA que AMD), bien qu’avec une architecture radicalement diffĂ©rente.

PyFR est un logiciel de CFD assez rĂ©cent (sa version 1.0.0 est sortie la semaine dernière), basĂ© sur un concept diffĂ©rent des solveurs actuels, la reconstruction de flux (FR), pour atteindre une prĂ©cision bien plus Ă©levĂ©e que les solveurs existants, mĂŞme sur des gĂ©omĂ©tries très complexes, tout en Ă©tant mieux adaptĂ©s Ă des GPU. (Techniquement, pour la discrĂ©tisation spatiale, il s’agit d’un schĂ©ma d’intĂ©gration Ă ordre Ă©levĂ© sur une grille non structurĂ©e, qui mĂŞle la prĂ©cision de mĂ©thodes d’ordre Ă©levĂ© des mĂ©thodes Ă diffĂ©rences finies et l’adaptabilitĂ© gĂ©omĂ©trique des volumes et Ă©lĂ©ments finis.)
Les solveurs actuels partent d’hypothèses des annĂ©es 1980, quand les opĂ©rations de calcul sur des nombres rĂ©els Ă©taient très coĂ»teuses, mais la mĂ©moire très rapide par rapport au processeur, deux points complètement dĂ©passĂ©s par les architectures actuelles, afin de simuler des Ă©coulements stationnaires. Ainsi, pour s’adapter Ă des simulations non stationnaires, il faut rĂ©inventer une sĂ©rie de composants
En pratique, ce nouveau logiciel peut donner des rĂ©sultats dix fois plus prĂ©cis dix fois plus rapidement que les techniques prĂ©cĂ©dentes, tout en Ă©tant capable d’exploiter la puissance d’une sĂ©rie de GPU. Il s’adapte Ă©galement Ă une sĂ©rie de plateformes : des grappes de CPU, formant les superordinateurs les plus courants ; des GPU, peu importe leur fabricant (tant AMD que NVIDIA). La distribution du calcul sur plusieurs nĹ“uds s’effectue par MPI.
CĂ´tĂ© technologique, la parallĂ©lisation sur un nĹ“ud de calcul est possible tant par OpenMP (plusieurs fils d’exĂ©cution sur le mĂŞme processeur) que CUDA ou OpenCL (GPU). Le logiciel lui-mĂŞme est principalement codĂ© en Python — ce qui ne l’empĂŞche pas d’exceller au niveau des temps de calcul, grâce Ă la facilitĂ© d’appel de code natif, principalement en C et Fortran. L’interprĂ©teur ajoute un surcoĂ»t en temps d’exĂ©cution infĂ©rieur au pour cent : cette perte de performance est nĂ©gligeable quand le code de calcul ne compte que cinq mille lignes de code !
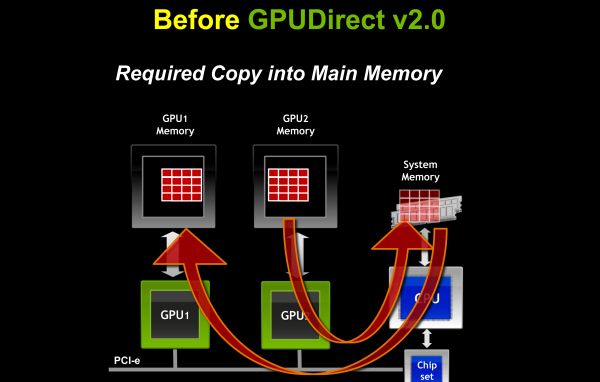
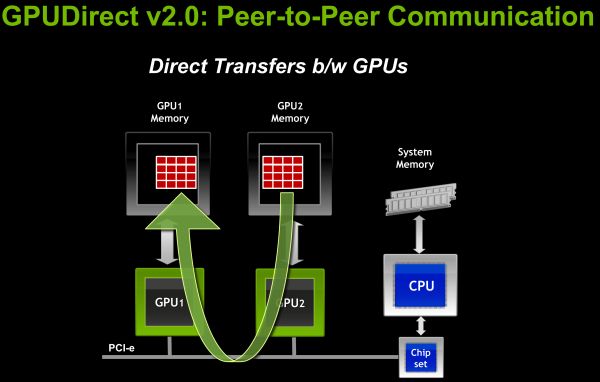
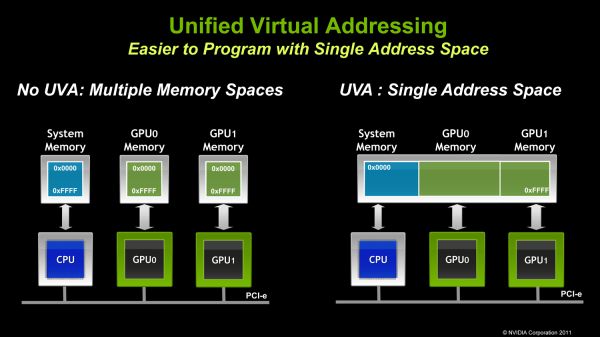
Tout le cĂ´tĂ© numĂ©rique est extrait dans une sĂ©rie de primitives bien comprises et optimisĂ©es. La communication s’effectue par une version de MPI adaptĂ©e Ă du calcul sur GPU, notamment en utilisant la technologie NVIDIA GPUDirect, qui permet la copie de donnĂ©es directement dans la mĂ©moire du GPU, sans passer par la mĂ©moire centrale (RAM). Les surcoĂ»ts dus Ă Python sont effacĂ©s en très grande partie grâce Ă la nature asynchrone de CUDA : le code Python n’est pas obligĂ© d’attendre la fin des calculs sur le GPU avant de passer Ă autre chose.
Sources : On a Wing and PyFR: How GPU Technology Is Transforming Flow Simulation, PyFR: An open source framework for solving advection–diffusion type problems on streaming architectures using the flux reconstruction approach, PyFR: Technical Challenges of Bringing Next Generation Computational Fluid Dynamics to GPU Platforms – See more at: http://on-demand-gtc.gputechconf.com/gtcnew/on-demand-gtc.php?searchByKeyword=pyfr&searchItems=&sessionTopic=&sessionEvent=&sessionYear=&sessionFormat=&submit=&select=#sthash.CNa7viRf.dpuf (dont l’image).
Voir aussi : le site officiel de PyFR.