
Il existe diffĂ©rentes manières d’effectuer des prĂ©visions / estimations dans le futur.
Certains logiciels facilitent ce type de calcul, notamment ceux spécialisés en datamining ou/et en calculs statistiques comme SAS,
Par contre d’autres comme Business Objects ne le permettent pas.
Mais on peut s’en passer dans des cas assez simples.
Je propose ici d’utiliser certaines fonctions d’Oracle qui rĂ©pondent Ă ce besoin, et de voir comment les implĂ©menter sous BO.
Problématique :
On a un indicateur annuel, on connait un certain historique et on aimerait estimer les valeurs de cet indicateur dans le futur.
Exemple :
select * from test_regr
2007 2
2008 4
2009 6
2010 8
Ici on ajoute 2 Ă Y chaque annĂ©e, donc on peut prĂ©voir qu’en 2011 on aurait Y=10, en 2012 Y=12 etc …
Evidemment ici on a une suite logique, c’est un exemple parfait.
Dans la vraie vie ce n’est pas si facile, par exemple on aurait :
2007 1.8
2008 4.2
2009 5.7
2010 8.8
On n’a pas ici la mĂªme diffĂ©rence entre 2 annĂ©es successives, On ne peut dĂ©duire la valeur de 2011 ou 2012 simplement.
Oracle propose des fonctions permettant de calculer une droite de rĂ©gression. En rĂ©sumĂ© il s’agit d’Ă©tablir une droite qui reprĂ©senterait la courbe d’Ă©volution de l’indicateur.
SĂ©quence Nostalgie des cours de stats : La mĂ©thode s’appuie sur le calcul des moindres carrĂ©s, je ne vais pas rentrer dans les dĂ©tails, d’autres le faisant mieux que moi comme sur wikipedia.
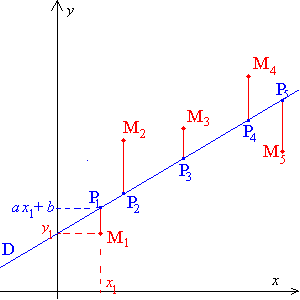
L’Ă©quation de cette droite est du type y= p x + y0, p Ă©tant la pente et y0 l’ordonnĂ©e Ă l’origine.
Sous Oracle la fonction REGR_SLOPE donne la pente, et REGR_INTERCEPT y0.
Une fois qu’on les a dĂ©terminĂ©s on peut estimer une valeur dans le futur en remplaçant x dans l’Ă©quation.
— ce qui donne avec l’exemple
with v as
( select 2010 annee, 8 y from dual
union select 2009, 6 from dual
union select 2008, 4 from dual
union select 2007, 2 from dual )
SELECT regr_slope( y, annee ) p, regr_intercept( y, annee ) y0 from v;
-- p=2 et y0=-4012
estimation pour 2011 :
= 2 * 2011 + -4012
= 10
ou en sql :
with v as
( select 2010 annee, 8 y from dual
union select 2009, 6 from dual
union select 2008, 4 from dual
union select 2007, 2 from dual )
SELECT regr_slope( y, annee )*2011 + regr_intercept( y, annee ) from v;
et le tout en one-shot :
with a as
( select to_char(sysdate,'YYYY') annee from dual union
select to_char(add_months(sysdate,-12),'YYYY') annee from dual union
select to_char(add_months(sysdate,-24),'YYYY') annee from dual union
select to_char(add_months(sysdate,-36),'YYYY') annee from dual union
select to_char(add_months(sysdate,+12),'YYYY') annee from dual union
select to_char(add_months(sysdate,+24),'YYYY') annee from dual union
select to_char(add_months(sysdate,+36),'YYYY') annee from dual
), v as
( select 2010 annee, 8 y from dual
union select 2009, 6 from dual
union select 2008, 4 from dual
union select 2007, 2 from dual )
select
a.annee,
v.y volume,
s.p * a.annee + s.y0 estim
from
v,
( select regr_slope( y, annee ) p, regr_intercept( y, annee ) y0 from v ) s,
a
where v.annee(+)=a.annee
order by a.annee;
Remarques :
- intuitivement on a une progression linéaire,
ce qui veut dire que si on sortait le graphe on pourrait tracer une ligne droite pour reprĂ©senter l’Ă©volution de l’indicateur.
Sinon les estimations ne donnent pas les bons rĂ©sultats - les fonctions regr sont des fonctions analytiques, on peut les utiliser comme telles avec la clause over( … )
cela rĂ©duit le nombre de passages sur la table d’historique et peut jouer sur les performances
SOUS Business Objects :
On trouve bien les fonctions REGR_% dans l’Ă©diteur des objets BO du designer
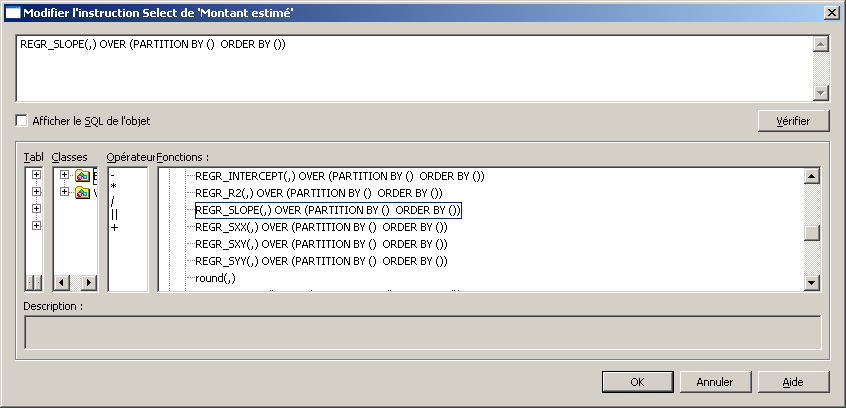
Mais les contraintes rĂ©duisent le champ d’action :
- on peut avoir des sum() en paramètre ( ex : regr_slope( sum( montant ), annee) ), mais la gestion est assez complexe, on mĂ©lange 2 fonctions d’agrĂ©gation et souvent cela pose problème car il manque une colonne dans le GROUP BY du select gĂ©nĂ©rĂ© par BO.
On oublie donc cela, et on a dĂ©jĂ des tables agrĂ©gĂ©es dans l’univers. - quand on rajoute des dimensions ( dans l’Ă©diteur SQL du rapport ) il faudrait les mettre dans la clause over(partition by (dimensions)) de la formule de l’objet dans Designer.
Il faut donc Ăªtre synchro entre l’Ă©diteur de rapport et l’univers. - il faut avoir des tables agrĂ©gĂ©es au grain de la dimension en x. Cela signifie qu’on doit avoir une seule valeur dans la table pour un x donnĂ©.
Par exemple si on a 10 opĂ©rations pour une annĂ©e, on n’aura pas d’erreur mais les fonctions se feront sur une sorte de moyenne des indicateurs ( au lieu de la somme ).
2010 2
2010 4
2010 6
2009 4
--> au lieu de sommer pour 2010 et d'avoir 12, les fonctions regr_%() vont traiter les 4 binĂ´mes et donc renvoyer une ligne plate ( y=4 )
Cela implique :
- il faut des tables agrĂ©gĂ©es au grain de la dimension en x. On peut s’en arranger avec des vues ou des tables dĂ©rivĂ©es qui font les sommes.
- il faut exactement les mĂªmes dimensions dans le fournisseur de donnĂ©es que celles utilisĂ©es pour les objets de rĂ©gression.
- si on utilise d’autres objets la requĂªte tombera en erreur
Cela peut donc multiplier le nombre de tables et d’objets dans l’univers.
Il est donc important de bien connaĂ®tre les besoins au dĂ©part, de se limiter Ă ce pĂ©rimètre et d’expliquer les contraintes aux utilisateurs finaux.
En conclusion l’implĂ©mentation des fonctions Oracle de rĂ©gression dans BO pour Ă©tablir un modèle prĂ©visionnel est assez limitĂ©e.
Il faut dĂ©finir l’Ă©tat final et Ă partir de lĂ dĂ©finir les objets de l’univers en utilisant les fonctions regr_slope() et regr_intercept().
L’univers utilisĂ© est un univers technique, on ne pourra crĂ©er facilement d’autres Ă©tats prĂ©visionnels Ă partir de celui-ci. Il faudra gĂ©nĂ©ralement Ă chaque fois crĂ©er de nouveaux objets.
Merci Bruno !
Je viens de dĂ©couvrir cet article … j’aime beaucoup, moi qui suis adepte de BO et Oracle je me suis rĂ©galĂ© !