
Comme vous le savez sans doute Windows Server 2012 est sorti et bien entendu en tant qu’administrateur de bases de données on peut se demander quelles sont les fonctionnalités de cette nouvelle mouture qui pourront bénéficier de près ou de loin à SQL Server. Dans ce premier volet j’ai décidé de commencer par la haute disponibilité. Une des fonctionnalités que j’ai trouvé relativement intéressante dans ce domaine est l’utilisation du quorum dynamique en environnement cluster et par la même occasion de Always-On de SQL Server 2012.
Tout d’abord on peut se poser une question légitime : qu’est-ce qu’un quorum dynamique ? Pour ceux qui font un peu de cluster, nous connaissons les différents types de quorum (nœuds majoritaires, nœuds et disque majoritaire, nœuds et partage de fichiers majoritaires, disque uniquement) qu’il est possible d’utiliser mais, quelque soit le type de quorum qui sera choisi, celui restera inchangé à moins d’une intervention manuelle et ceci quelque soit le nombre de nœuds restant en ligne. Rappelons qu’un cluster Windows (en fonctionnement normal) peut rester en ligne si et seulement si le quorum peut se faire.
Prenons un exemple avec un cluster à 3 nœuds et un quorum de type “nœuds majoritaires”. Que se passe-t-il si un nœud du cluster tombe et ensuite un deuxième ? Bien entendu la réponse est évidente ici : le cluster Windows ne peut plus rester en ligne car le vote majoritaire ne peut plus se faire (1 nœud restant < 3 / 2). Pour que ce dernier puisse rester en ligne avec un seul nœud, il aurait fallu changer le poids de vote des nœuds participant en quorum. Cette option est apparue avec Windows Server 2008 R2 et permet de changer la propriété NodeWeight de chaque nœud du cluster à 0 pour l’exclure du vote du quorum. Cette option permet entre autre de régler des problèmes de “split brain” que l’on peut retrouver dans bon nombre d’architectures cluster avec des nœuds distants sur différents sites. Elle est également d’une grande utilité dès que l’on parle de fonctionnalité comme Always-On avec SQL Server 2012, où il n’est pas rare d’avoir des nœuds distants pour les situations de disaster recovery. Je ferai un billet sur le sujet une prochaine fois mais revenons à notre scénario : pour que notre cluster redémarre, il faut utiliser l’option /ForceQuorum ou –FixQuorum, dans le cas où l’on préfère utiliser respectivement ces options avec la commande cluster.exe ou power Shell et Start-ClusterNode. Dans les 2 cas, on force le cluster à redémarrer sans le quorum et on fixe le poids de vote du nœud restant en ligne à 1.
C’est là qu’intervient notre quorum dynamique. En effet, dès lors qu’un nœud tombe ou revient en ligne, le calcul du quorum est à chaque fois revu par le cluster lui-même en changeant le poids de vote des nœuds, ce qui lui permet de s’adapter à la nouvelle situation . Ainsi, si on reprend notre précédent scénario dans sa situation initiale (type de quorum à nœuds majoritaires avec l’ensemble des nœuds qui participent au quorum) et si 2 nœuds tombent consécutivement, alors le calcul du quorum sera revu à chaque fois et on pourra se retrouver avec un seul nœud en ligne, et ce sans que le cluster lui-même ne tombe. Vous imaginez donc l’avantage que l’on pourrait en tirer avec un cluster SQL ou une architecture Always-On ![]() . Cependant, pour que ce calcul dynamique puisse s’effectuer, il faudra que les nœuds tombent séquentiellement. Par conséquent, si 2 nœuds tombent au même moment, le quorum dynamique ne pourra être utilisé.
. Cependant, pour que ce calcul dynamique puisse s’effectuer, il faudra que les nœuds tombent séquentiellement. Par conséquent, si 2 nœuds tombent au même moment, le quorum dynamique ne pourra être utilisé.
Voici à quoi ressemble maintenant la configuration du quorum sur Windows Server 2012. Nous avons maintenant en mode GUI la possibilité de configurer des paramètre autrefois accessibles qu’en mode commande.
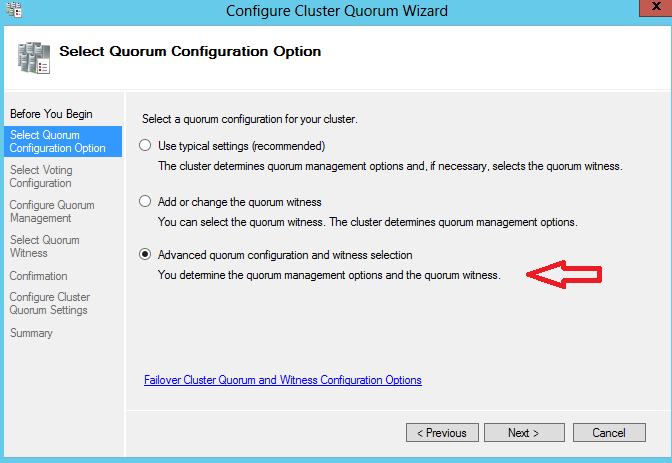
Il est possible de déterminer quels nœuds seront ou non impliquées dans le vote du quorum. Dans notre scénario tous les nœuds seront impliqués.
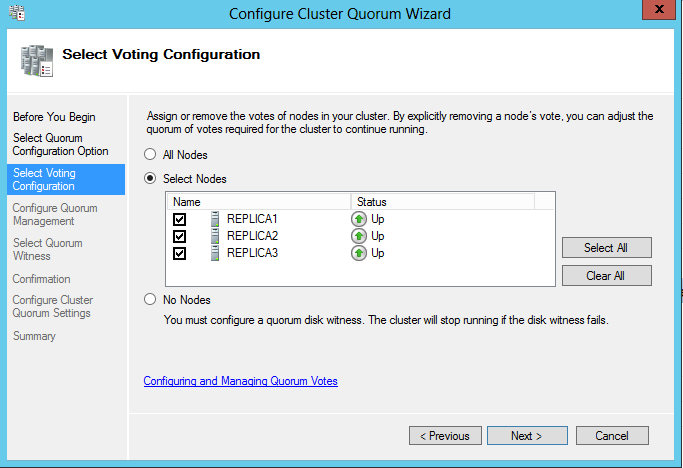
C’est ici que l’on voit autoriser ou non au cluster de gérer dynamiquement le nombre de votes lorsqu’un nœud tombe ou redevient opérationnel. A noter que par défaut cette option est activée. Il faut également préciser que si un nœud a été explicitement exclu lors de la précédente phase le cluster ne pourra pas prendre le ou les nœuds concernés dans le calcul dynamique du quorum.
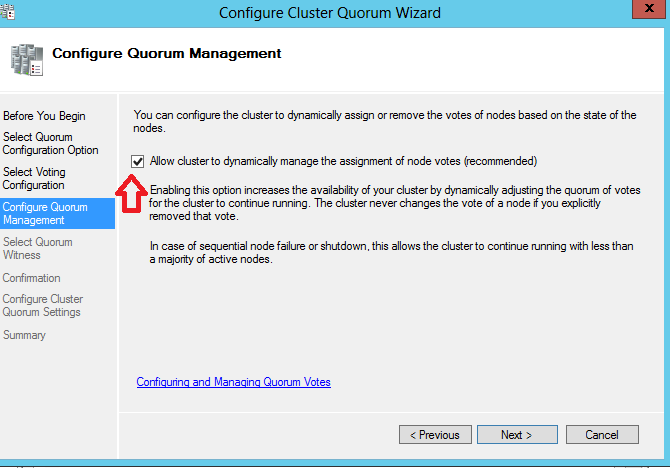
Enfin la dernière phase de configuration du quorum concerne la prise en compte ou non d’un témoin supplémentaire (disque ou dossier partagé) pour le vote du quorum. En fonction de la topologie cluster l’assistant nous recommande ou non d’ajouter un témoin additionnel. Dans notre cas comme nous sommes dans une topologie à 3 nœuds le type de quorum Nœuds majoritaires sans témoin additionnel convient très bien.

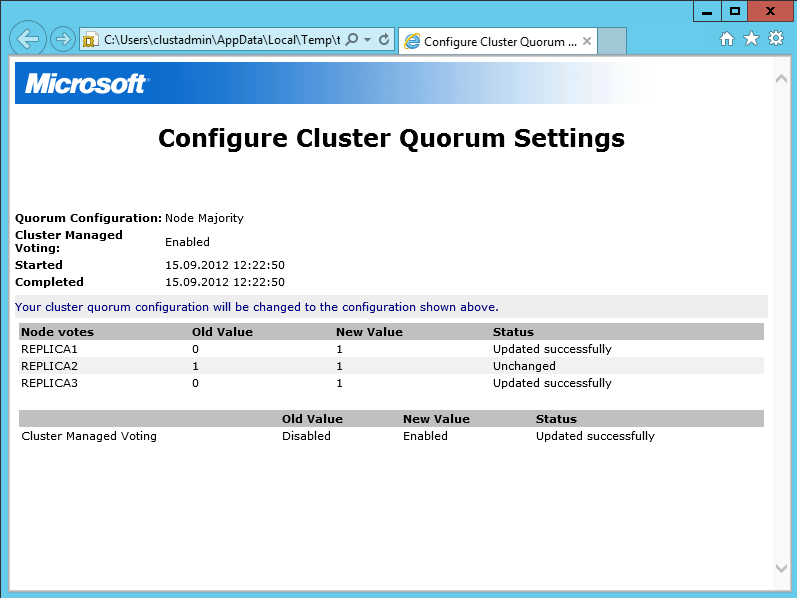
Voici l’état de mes 3 nœuds et quorum dans la situation initiale à l’aide de la commande Power Shell suivante :
[sourcecode language='powershell' padlinenumbers='true'] get-clusternode -cluster winclust | ft name, dynamicweight, nodeweight, id, state -autosize [/sourcecode]
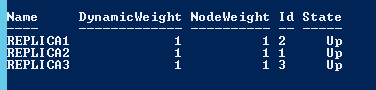
On peut remarquer l’apparition du paramètre DynamicWeight ici. C’est ce paramètre qui sera utilisé et modifier par le cluster pour modifier le nombre de votes autorisés pour le quorum. Le paramètre NodeWeight quant à lui restera échangé et concerne la partie configurable par l’utilisateur dans les différentes fenêtres montrées plus haut. A présent faisons tombez un nœud du cluster : REPLICA3 et regardons à nouveau l’état des nœuds et du nombre de votes :
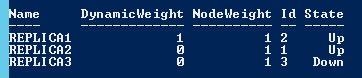
On constate ici que le nombre de votes a été changé dynamiquement par le cluster suite à l’arrêt du nœud REPLICA3. On est passé d’un nombre de votes à 3 initialement à 1. Pourquoi 1 et pas 2 ici ? Tout simplement parce que si le cluster avait laissé 2 (un pour le nœud REPLICA1 et un pour le nœud REPLICA2) et que si un autre nœud tombe le nombre de vote devant toujours être majoritaire alors le cluster lui même ne pourrait pas rester en ligne (1 < 2). C’est la raison pour laquelle le cluster n’a laissé qu’un seule vote possible en cas de problème sur un des 2 nœuds restants. Faisons le test et faisons tomber le nœud REPLICA1 :
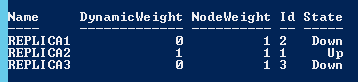
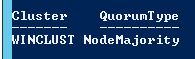
On constate tout d’abord que notre cluster est toujours en ligne et ensuite que le calcul du quorum a été à nouveau modifié . C’est le nœud restant en ligne qui a maintenant la possibilité de voter (normal me direz-vous si on veut avoir un cluster toujours en ligne) . On peut voir également que le type de quorum utilisé est Nœuds majoritaires dans notre cas.
[sourcecode language='powershell' ] get-cluster -name wincluster | get-clusterquorum | ft Cluster, QuorumType -autosize [/sourcecode]
Maintenant que nous avons vu l’intérêt de cette nouvelle fonctionnalité Windows Server 2012 dan un contexte cluster, voyons ce qu’elle donne avec une topologie Always-On de SQL Server 2012. Pour rappel, Always-on utilise la couche de base Windows Cluster pour fonctionner. Le quorum dynamique dans ce cas peut nous aider à maintenir un niveau de disponibilité beaucoup plus élevé. Prenons le scénario suivant avec 3 réplicas dont 2 concernés par un failover automatique et un qui sera utilisé dans un contexte de disaster recovery.
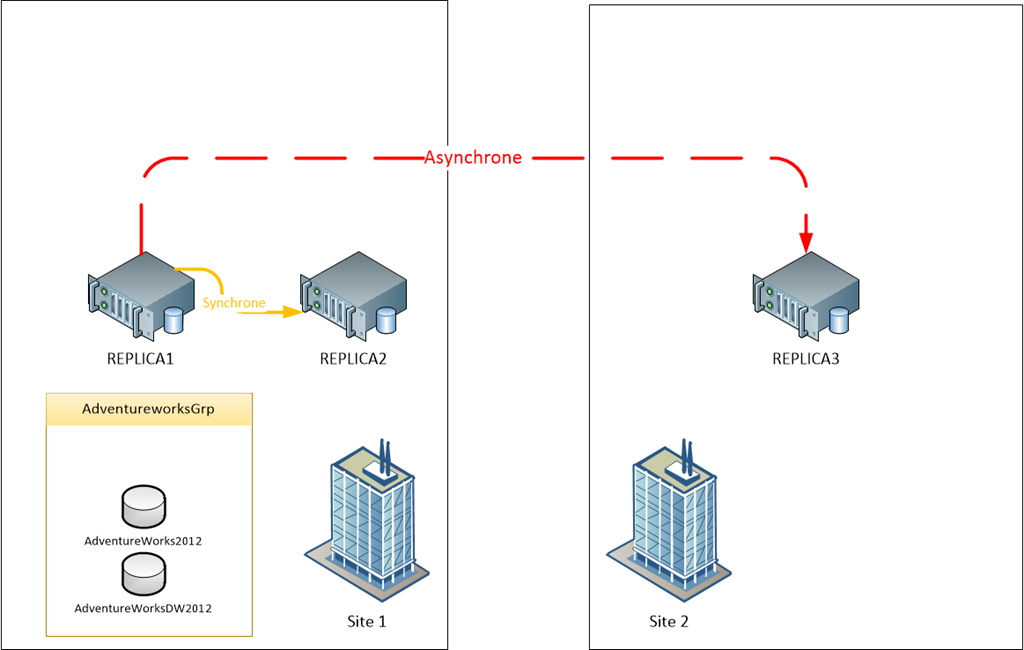
Dans ce scénario nous pourrions déjà exclure le REPLICA3 car nous ne voulons pas que celui-ci intervienne dans le vote du quorum si une coupure réseau se produit entre les 2 sites.
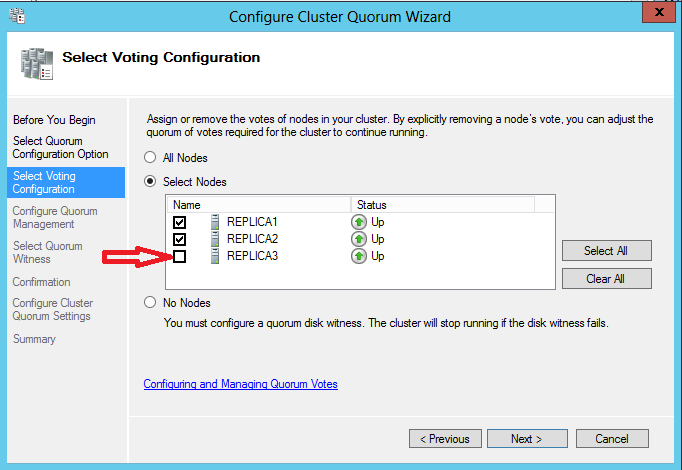
On peut visualiser la configuration directement via les DMV Always-On :
[sourcecode language='sql' ] SELECT cluster_name, quorum_type_desc, quorum_state_desc FROM sys.dm_hadr_cluster; SELECT member_name, member_type_desc, member_state_desc, number_of_quorum_votes FROM sys.dm_hadr_cluster_members; [/sourcecode]

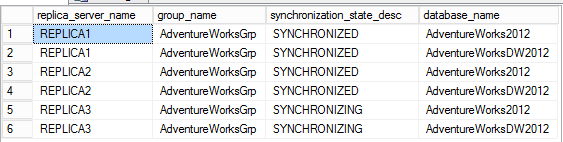
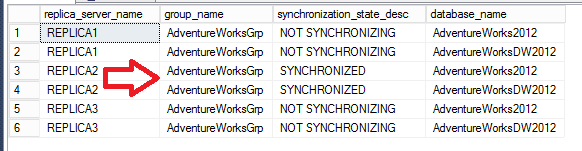
On voit effectivement que le REPLICA3 est exclu du nombre de votes pour le quorum et que le type de quorum est bien Nœuds majoritaires. La topologie Always-On est ici composée d’un seul groupe de disponibilité nommé AdventureWorksGrp avec les 2 bases AdventureWorks qui sont AdventureWorks2012 et AdventureWorks2012DW
[sourcecode language='sql' ] SELECT R.replica_server_name, G.name AS group_name, DRS.synchronization_state_desc, D.name AS database_name FROM sys.dm_hadr_database_replica_states AS DRS JOIN sys.availability_replicas AS R ON DRS.replica_id = R.replica_id JOIN sys.availability_groups AS G ON G.group_id = DRS.group_id JOIN sys.databases AS D ON D.database_id = DRS.database_id ORDER BY R.replica_server_name, G.name, D.name [/sourcecode]
l
Regardons à présent la configuration du cluster Windows :
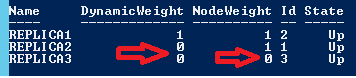
On voit également ici que le nœud REPLICA3 est bien exclu du vote du quorum (NodeWeight = 0) et que la configuration dynamique du cluster est directement configuré avec 2 nœuds exclus (REPLICA3 et REPLICA2).
Commençons par couper le réseau entre le nœud REPLICA3 et les nœuds REPLICA1 et REPLICA2 et voyons ce qui se passe au niveau du cluster et du groupe de disponibilité.

…

Ok le nœud REPLICA3 est bien tombé. Faisons tomber à présent le nœud REPLICA1 pour initier un failover automatique avec le nœud REPLICA2. Voyons si le fait d’avoir un seul nœud dans la topologie cluster + always-on fera tomber le cluster le groupe de disponibilité.
Côté cluster celui-ci est toujours en ligne et le calcul du quorum a changé et seul le nœud en ligne devient le seul membre du quorum.

Côté Always-On on retrouve le nœud REPLICA2 en ligne. On voit également qu’ici le nombre de votes n’a pas changé mais on peut rapidement constater que l’on ne voit en réalité la propriété statique NodeWeight. On avait exclu manuellement le nœud REPLICA3. C’est ce que l’on voit ici.

Le groupe de disponibilité est toujours en ligne également sur le nœud REPLICA2. Sans Windows Server 2012 il aurait fallu redémarrer le cluster Windows en mode quorum forcé avant que le groupe de disponibilité ne soit à nouveau joignable. Bien entendu si ce scénario concernait cette fois-ci un réplica asynchrone il aurait également fallu forcer le failover mais ceci est une autre histoire ![]() . En tout cas cette nouvelle fonctionnalité de Windows Server 2012 mérite d’être testée !
. En tout cas cette nouvelle fonctionnalité de Windows Server 2012 mérite d’être testée !
Bonne configuration de quorum !!
David BARBARIN (Mikedavem)
MVP SQL Server
Salut zoltix,
Oui c’est cela il n’y aura pas calcul du quorum avec une prise en compte du rĂ©plica sur le site 2. Pour rendre le site 2 actif il faudra redĂ©marrer le cluster en mode quorum forcĂ© et procĂ©der Ă un failover manuel du groupe de disponibilitĂ©.
La synchronisation ne sera pas automatique dans ce cas. Au mieux les bases de donnĂ©es seront dans Ă©tat suspendu et il suffira de rĂ©sumer les mouvements pour reprendre la synchronisation et au pire restaurer les logs bases de donnĂ©es ou restaurer complĂ©menter les bases concernĂ©s. Tout dĂ©pendra l’Ă©tat des bases après redĂ©marrage du site 1 (REVERTING or INITIALIZING), le temps passĂ© entre le crash et la remis en route du site 1 et les transactions Ă©ventuellement perdues lors du failover forcĂ© sur le site2.
En espérant avoir répondu à tes questions
++
Excellent article mais je me pose une question
Si j’ai compris, comme NodeWeight est a 0 sur le site 2(config), le site 2 ne devient pas actif automatiquement si la liaison entre site 1 et site 2 est perdue. Pour rendre site 2 actif, il devrait avoir une intervention manuelle ce qui permet d’éviter le « split brain ».
On a décidé d’activer le site 2. Après 3 jours, le site 1 est de nouveau ok, la synchro est automatique?, ou manuelle? Quel est solution utilisé pour éviter splitbrain ?