
Let’s continue with Azure stories and performance scaling …

A couple of weeks ago, we studied opportunities to replace existing clustered indexes (CI) with columnstore indexes (CCI) for some facts. To cut the story short and to focus on the right topic of this write-up, we prepared a creation script for specific CCIs based on the Niko’s technique variation (no MAXDOP = 1 meaning we enable parallelism) in order to get a better segment alignment.
CREATE CLUSTERED INDEX [PK_FACT_IDX]
ON dbo.FactTable (KeyColumn)
WITH (DROP_EXISTING = ON, DATA_COMPRESSION = PAGE);
-- Creation of the CCI
CREATE CLUSTERED COLUMNSTORE INDEX [PK_FACT_IDX]
ON dbo.FactTable
WITH (DROP_EXISTING = ON);
-- Recreation of [[... n] nonclustered indexes
CREATE INDEX [IDX_xxx … n]
ON dbo.FactTable (column)
WITH (DROP_EXISTING = ON, DATA_COMPRESSION = PAGE);
Before deploying those indexes in our SQL DB Azure environment, we staged a first scenario in on-premises instance and the creation of all indexes took ~ 1h. It is worth noting that our tests are based on the same database with the same data in all cases. But guess what, the story was different in Azure ![]() and I got feedbacks from another team who was responsible to deploy indexes in Azure, the creation script was a bit longer (~ 4h).
and I got feedbacks from another team who was responsible to deploy indexes in Azure, the creation script was a bit longer (~ 4h).
I definitely enjoyed this story because we got a deeper understanding of DB Azure performance topic.
=> Moving to the cloud means we’ll get slower performance?
Before drawing conclusions to quickly a good habit to get is to compare specifications between environments. It’s not about comparing oranges and apples. Well let’s set my own context: from one side, the on-premises virtual SQL Server environment specification includes 8vCPUs (Intel(R) Xeon(R) CPU E5-2670 v3 @ 2.30GHz), 64 GB of RAM and a high-performance storage array with micro latency device dedicated to our IO intensive workloads. From the vendor specifications, we may except very interesting IO performance with a general throughput greater than 100 KIOPs (Random) or 1GB/s (sequential). On another side, the SQL DB Azure is based on the service pricing tier General Purpose: Serverless Gen5, 8 vCores. We use the vCore purchasing model and referring to the Microsoft documentation, hardware generation 5 includes a compute specification based on Intel E5-2673 v4 (Broadwell) 2.3-GHz and Intel SP-8160 (Skylake) processors. Added to this, the service pricing tier comes with a remote SSD based storage including IO latency around 5-7ms and 2560 IOPs max. Given the opportunity of the infrastructure elasticity, we could scale to up 16 vCores, 48GB of RAM and 5120 IOPs for data. Obviously, latency remains the same in this case.
As illustration, creation of all indexes (CI + CCI + NCIs) performed in our on-premises environment gave the following storage performance figures: ~ 700MB/s and 13K IOPs for maximum values that were an aggregation of DATA + LOG activity on D: drive. Rebuilding indexes are high resource consuming operations in terms of CPU as well and we obviously noticed CPU saturation at different steps of the operation.
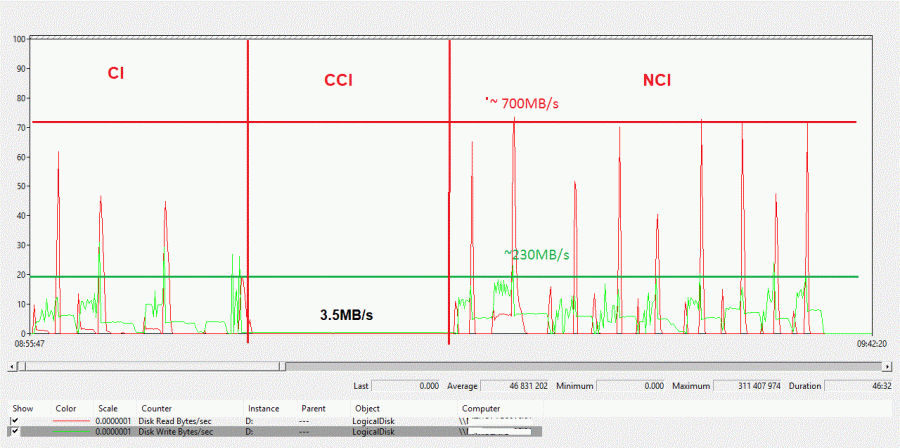
…
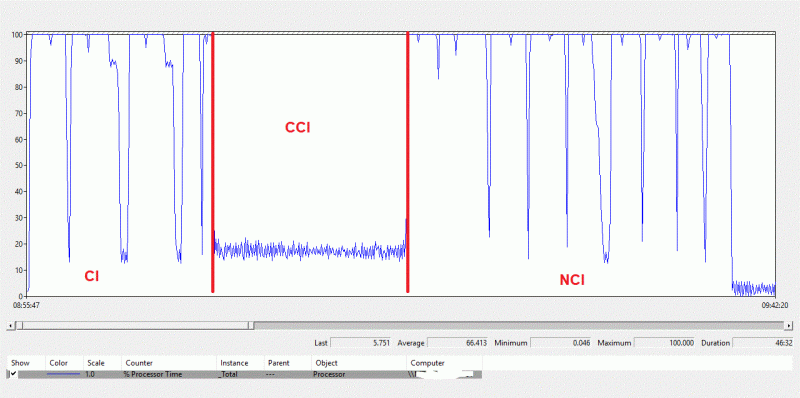
As an aside, we may notice the creation of CCI is a less intensive operation in terms of resources and we retrieve the same pattern in Azure below. Talking of which, let’s compare with our SQL Azure DB. There are different ways to get performance metrics including the portal which enables monitoring performance through easy-to-use interface or DMVs for each Azure DB like sys.dm_db_resource_stats. It is worth noting that in SQL Azure DB metrics are expressed as percentage of the service tier limit, so you need to adjust your analysis with the tier you’re using. First, we observed the same resource utilization pattern for all steps of the creation script but within a different timeline – duration has increased to 4h (as mentioned by another team). There is a clear picture of reaching the limit of the configured service tier, especially for Log IO (green line) and we already switched from GP_S_Gen5_8 to GP_S_Gen5_16 service tier
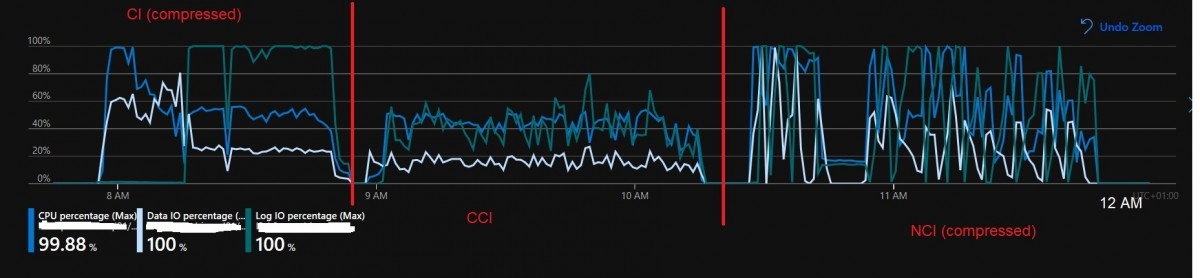
In addition, Wait stats gave interesting insights as well:

Excluding the traditional PAGEIOLATCH_xx waits, the LOG_RATE_GOVERNOR wait type appeared in the top waits and confirms that we bumped into the limits imposed on transaction log I/O by our performance tier.
=> Scaling vs Upgrading the Service for better performance?
With SQL DB Azure PaaS, we may benefit from elastic architecture. Firstly, scaling the number of CPUs is a factor of improvement and there is a direct relationship with storage (IOPs), memory or disk space allocated for tempdb for instance. But the order of magnitude varies with the service tier as shown below:
For General Purpose ServerLess Generation 5 service tier – Resources per Core

Something relevant here because even performance increases with the number of vCores provisioned, we can deduce Log IO saturation from our test in Azure (especially in the first step of the CI creation) results of max log rate limitation that doesn’t scale in the same way. This is especially relevant here because as said previously index creation can be an resource intensive operation with a huge impact on the transaction log.
What would be a solution to speed-up this operation?
First viable solution in our context would be to switch to SIMPLE recovery model that fits perfectly with our scenario because we could get minimally-logged capabilities and a lower impact on the transaction log and because it is suitable for DW environments. Unfortunately, at the moment of this write-up, this is not supported and I suggest you to vote on feedback Azure if you are interested in.
From an infrastructure standpoint, improving max log rate throughput is only possible by upgrading to a higher service tier (but at the cost of higher fees obviously). For a sake of curiosity, I did a try with the BC_Gen5_16 service tier specifications:

Even if this new service tier seems to be a better fit (suggested by the relative percentage of resource usage) …

… there are important notes here:
1) Business Critical Tier is not available for Serverless architecture
2) Moving to a different service is not instantaneous and it may require several hours according to the database size (~ 3h for a total size of ~500GB database size in my case). Well, this is not viable option even if get better performance. Indeed, if we add the time to upgrade to a higher service tier (3h) + time to run the creation script (3h or 25% of performance gain compared to the previous GP_S_Gen5_16 service tier). We may obviously upgrade again to reach performance closer to our on-premises environment but does it worth fighting for here only for an index creation script?
Concerning our scenario (Data Warehouse), it is generally easy to schedule a non-peak hours time frame that doesn’t overlap with the processing-oriented workload but it could not be the case for everyone!
See you!
Ping : 3contemporary