
A couple of days ago, I read the write-up of my former colleague @FranckPachot about refactoring procedural code to SQL. This is recurrent subject in the database world and I was interested in transposing this article to SQL Server because it was about refactoring a Scalar-Valued function to a SQL view. The latter one is a great alternative when it comes performance but something new was shipped with SQL Server 2019 and could address (or at least could mitigate) this recurrent scenario.
First of all, Scalar-Valued functions (from the User Defined Function category) are interesting objects for code modularity, factoring and reusability. No surprise to see them widely used by DEVs. But they are not always suited to performance considerations especially when it concerns the “impedance mismatch” problem. This is term used to refer to the problems that occurs due to differences between the database model and the programming language model. Indeed, from one side, a database world with SQL language that is declarative, and with queries that are set or multiset-oriented. To another side, programing world with imperative-oriented languages requiring accessing each tuple individually for processing.
To cut the story short, Scalar UDF provides programing benefits for DEVs but when performance matters, we discourage to use them for the aforementioned reasons. Before continuing, let’s precise that all the scripts and demos in the next sections are based on salika-db project on GitHub. Franck Pachot used the mysql version and fortunately there exists a sample for SQL Server as well. Furthermore, the mysql function used as initial example by Franck may be translated to SQL Server as follows:
CREATE OR ALTER FUNCTION inventory_in_stock (@p_inventory_id INT)
RETURNS BIT
BEGIN
DECLARE @v_rentals INT;
DECLARE @v_out INT;
DECLARE @verif BIT;
--AN ITEM IS IN-STOCK IF THERE ARE EITHER NO ROWS IN THE rental TABLE
--FOR THE ITEM OR ALL ROWS HAVE return_date POPULATED
SET @v_rentals = (SELECT COUNT(*) FROM rental WHERE inventory_id = @p_inventory_id);
IF @v_rentals = 0
BEGIN
SET @verif = 1
END
ELSE
BEGIN
SET @v_out = (SELECT COUNT(rental_id)
FROM inventory
LEFT JOIN rental ON inventory.inventory_id = rental.inventory_id
WHERE inventory.inventory_id = @p_inventory_id
AND rental.return_date IS NULL)
IF @v_out > 0
SET @verif = 0;
ELSE
SET @verif = 1;
END;
RETURN @verif;
END
GO
During his write-up, Franck provided a natural alternative of this UDF based on a SQL view and here a similar solution applied to SQL Server:
AS
SELECT
i.inventory_id,
CASE
WHEN NOT EXISTS (SELECT 1 FROM dbo.rental AS r WHERE r.inventory_id = i.inventory_id AND r.return_date IS NULL) THEN 1
ELSE 0
END AS inventory_in_stock
FROM dbo.inventory AS i
GO
Then similar to what Franck did, we can join this view with the inventory table to get the expected outcome:
from inventory AS i
left join v_inventory_stock_status AS v ON i.inventory_id = v.inventory_id
group by v.inventory_in_stock;
go
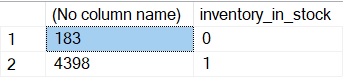
There is another alternative that could be use here base on a CTE rather than a TSQL view as follows. However, the performance is similar in both cases and it is up to each DEV which solution fits with their needs:
as
(
SELECT
i.inventory_id,
CASE
WHEN NOT EXISTS (SELECT 1 FROM dbo.rental AS r WHERE r.inventory_id = i.inventory_id AND r.return_date IS NULL) THEN 1
ELSE 0
END AS inventory_in_stock
FROM dbo.inventory AS i
)
select count(v.inventory_id),inventory_in_stock
from inventory AS i
left join cte AS v ON i.inventory_id = v.inventory_id
group by v.inventory_in_stock;
go
I compared then the performance between the UDF based version and the TSQL view:
select count(*),dbo.inventory_in_stock(inventory_id)
from inventory
group by dbo.inventory_in_stock(inventory_id)
GO
-- view
select count(v.inventory_id),inventory_in_stock
from inventory AS i
left join v_inventory_stock_status AS v ON i.inventory_id = v.inventory_id
group by v.inventory_in_stock;
go
The outcome below (CPU, Reads, Writes, Duration) is as expected. The SQL view is the winner by far.

Similar to Franck’s finding, the performance gain is as the cost of rewriting the code for DEVs in this scenario. But SQL Server 2019 provides another interesting way to continue using the UDF abstraction without compromising on performance: Scalar T-SQL UDF Inlining feature and I was curious to see how much improvement we get with such capabilities for this scenario.
First time I executed the following UDF-based TSQL script on SQL Server 2019 RTM (be sure to be in 150 compatibility mode), I ran into some OOM issues for the second query:
ALTER DATABASE SCOPED CONFIGURATION SET TSQL_SCALAR_UDF_INLINING = OFF;
GO
SELECT dbo.inventory_in_stock(10)
GO
-- SQL 2019+
ALTER DATABASE SCOPED CONFIGURATION SET TSQL_SCALAR_UDF_INLINING = ON;
GO
SELECT dbo.inventory_in_stock(10)
Msg 8624, Level 16, State 17, Line 14
Internal Query Processor Error: The query processor could not produce a query plan. For more information, contact Customer Support Services.
To be honest, not a surprise to be honest because I already aware of it by reading the blog post of @sqL_handle a couple of weeks ago. Updating to CU2 fixed my issue. The second shot revealed some interesting outcomes.
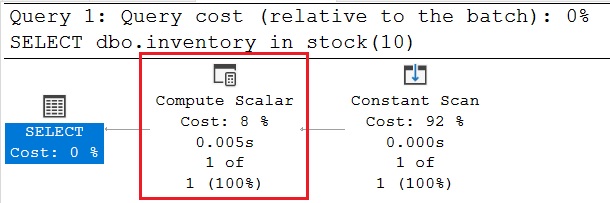
The query plan of first query (<= SQL 2017) is as we may expected usually from executing a TSQL scalar function. From an execution perspective, this black box is materialized in the form of the compute scalar operator as shown below:
But the story has changed with Scalar UDF Inlining capability. This is illustrated by the below pictures which are sample of a larger execution plan:

…
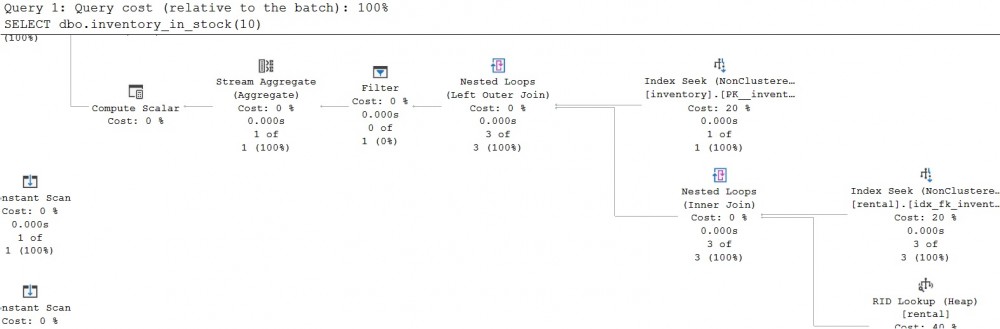
The query optimizer has inferred some relation operations from my (imperative based) scalar UDF based on the Froid framework and provides several benefits including compiler optimization and parallelism (initially not possible with UDFs).
Let’s perform the same benchmark test that I performed between the UDF-based and the TSQL view based queries. In fact, I had to propose a slightly variation of the query to hope kicking in the Scalar UDF Inline capability:
select count(*),dbo.inventory_in_stock(inventory_id)
from inventory
group by dbo.inventory_in_stock(inventory_id)
GO
-- Variation of the first query
;with cte
as
(
select inventory_id,dbo.inventory_in_stock(inventory_id) as inventory_in_stock
from inventory
)
select count(*), inventory_in_stock
from cte
group by inventory_in_stock
GO
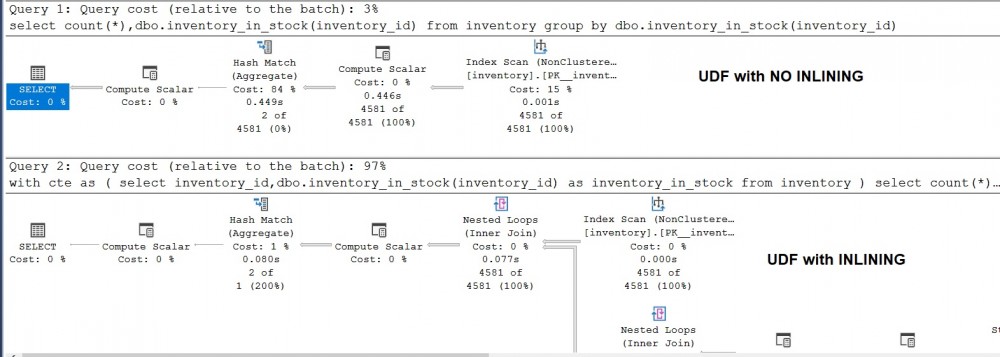
From a performance perspective, it is worth noting the improvement is not necessarily on the read operation but more the CPU and Duration times.

But let’s push the tests further by increasing the amount of data. As a reminder, the performance of the test is tied to the number of UDF execution and implicitly number of records in the Inventory table.
So, let’s add a bunch of records to the Inventory table …
SELECT
film_id,
store_id,
GETDATE()
FROM inventory;
… and let’s execute this script to get respectively a total of 146592 and 2345472 rows for each test. Here the corresponding performance outcomes:
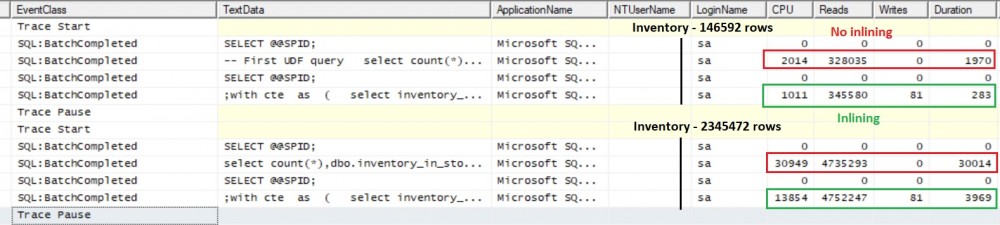
I noticed more rows there are in the inventory table better performance we get for each corresponding test:
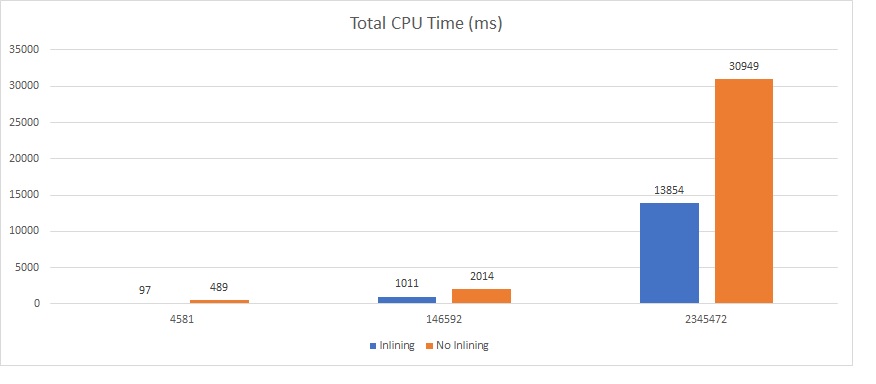
…
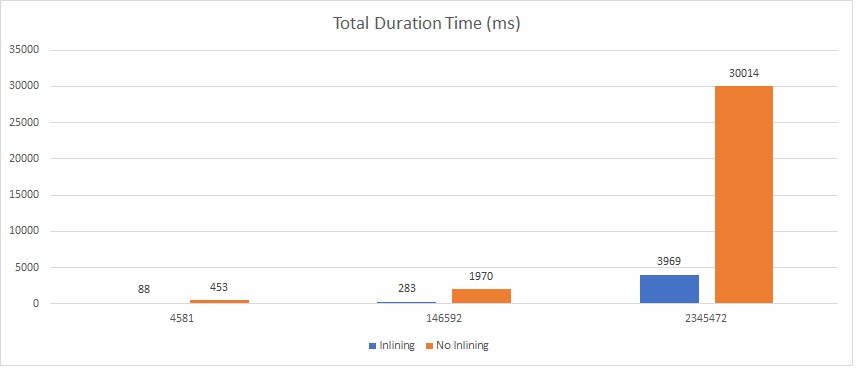
Well, interesting outcome without rewriting any code isn’t it? An 80% decrease in average for query duration time and 61% for CPU time execution. For a sake of curiosity let’s take a look at the different query plans:
Scalar UDF Inlining not enabled

Again, the real cost is hidden by the UDF black box through the compute scalar operator but we guess easily that every row processed by compute Scalar operator implies the dbo.inventory_in_stock() function.
Scalar UDF Inlining enabled
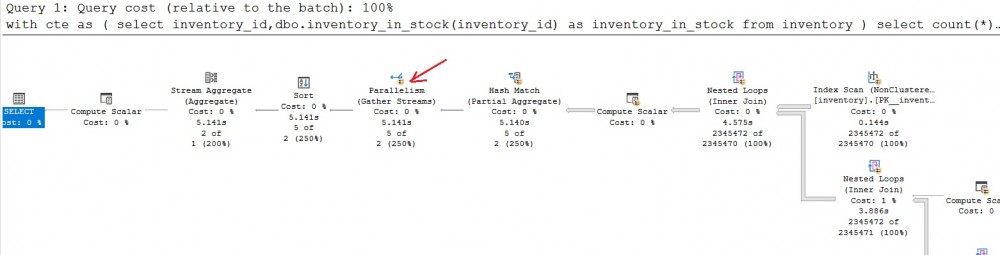
Without going into details of the execution plan, something that draw attention is compiler optimizer tricks kicked in including parallelism. All the optimization stuff done by the query processor is helpful to improve the overall performance of the query.
So last point, does Scalar UDF Inlining scale better than the SQL view?

This last output seems to confirm the SQL view remains the winner among the alternatives in this specific scenario and you will have to choose best solution and likely the acceptable tradeoff that will fit with your context.
See you!