
As DBA, your priority is to ensure your data are consistent, safely backed up and you get steady performance of your database. In on-prem environments, these tasks are generally performed through scheduled jobs including backups, check integrity and index / statistics maintenance tasks.
But moving databases to the cloud in Azure (and others) tells a different story. Indeed, even if the same concern and tasks remain, some of them are under the responsibility of the Cloud provider and some other ones not. If you’re working with Azure SQL databases – like me – some questions raise very quickly on this topic and it was my motivation to write this write-up. I would like to share with you some new experiences by digging into the different maintenance items. If you have a different story to tell, please feel free to comment and to share your own experience!
Database backups
Microsoft takes over the database backups with a strategy based on FULL (every week), DIFF (every 12 hours) and LOGs (every 5 to 10min) with cross-datacenter replication of the backup data. As far as I know, we cannot change this strategy, but we may change the retention period and extend it with an archiving period extend up to 10 years by enabling the Long-term retention. The latter assumes this is supported by your database service level and options that come with. For instance, we are using some SQL Azure databases in serverless mode which doesn’t support LTR. This strategy provides different methods to restore an Azure database including PITR, Geo-Restore or the ability to restore a deleted database. We are using some of them for our database refresh between Azure SQL Servers or sometimes to restore previous database states for testing. However, just be aware that even if restoring a database may be a trivial operation in Azure, the operation may take a long time regarding your context and factors described here. In our context and regarding the operation, a restore operation may take up to 2.5h (600GB of data to restore on GEN5
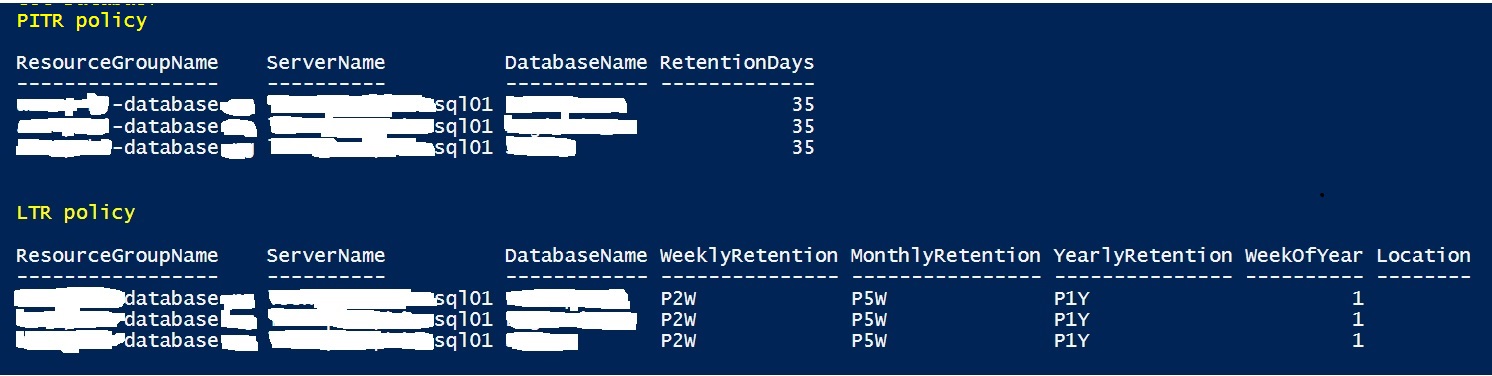
In addition, it is worth noting that there is not a free lunch here and you will pay for storing your backups and probably more than you initially expect. Cost is obviously tied to your backup size for FULL, DIFF and LOG and the retention period making the budget sometimes hard to predict. According to discussions with some colleagues and other MVPs, it seems we are not alone in this case and my advice is to keep an eye of your cost. Here a quick and real picture of the cost ratio between compute + database storage versus backup storage (PITR + LTR) with a PITR retention of 35 days and LITR (max retention of one year)
…
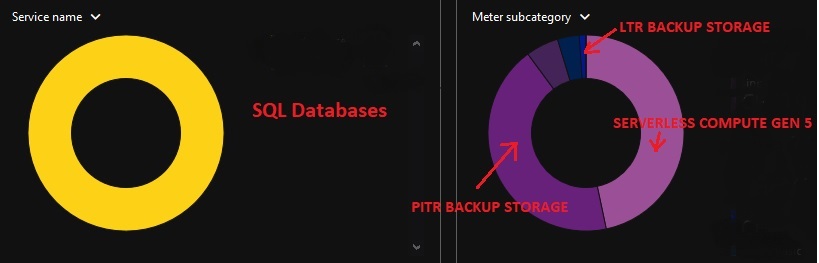
As you may notice half of the total fees for the Azure SQL Database may concern only the backup storage. From our side, we are working hard on reducing this ratio, but this is another topic out of the scope of this blog post.
Database integrity check
Should we continue to use the famous DBCC CHECKDB command? Well, the response is no, and the Azure SQL Database engineering team takes responsibility for managing data integrity. During internal team discussions we wondered what the process would be to recover corrupt data and how fast corruptions are treated by the Azure team. All questions seem to be addressed in this Microsoft blog post here and for us, it was important to know the Microsoft response time in case of database corruption because it may impact the retention policy. Faster Microsoft warns you about your integrity issue, less the retention could be to rewind to the last consistent point (in a reasonable order of magnitude obviously).
Database maintenance (statistics and indexes)
Something that is likely misunderstood with Azure SQL database is the maintenance of indexes and statistics are not anymore under the responsibility of the DBA. Referring to some discussions around me, it seems to be a misconception and the automatic index tuning was often mentioned in the discussions. Automatic tuning aims to adapt dynamically database to a changing workload by applying tuning recommendations either by creating new indexes or dropping redundant and duplicate indexes or forcing last good plan for queries as well. Even this feature (not by default) helps improving the performance for sure, it doesn’t substitute neither updating statistics nor rebuilding fragmented indexes. Concerning the statistics, it is true that some improvements about statistics has been shipped with SQL Server over the time like TF2371 which makes the formula for large tables more dynamic (by default since SQL Server 2016+) but we may arguably say that it remains situations where updating statistics should be done manually and as database administrator it is still under your own responsibility to maintain them.
Database maintenance and schedulng in Azure?
As said as the beginning of this write-up with Azure SQL DB, database maintenance is a different story and the same applies when it comes scheduling. Indeed, you quickly noticed we lacked built-in job scheduler capabilities like the traditional SQL Server agent with on-premises installations, but it doesn’t mean we were not able to schedule any job at all. In fact, there is exists different options to look at to replace the traditional SQL Server agent for database maintenance in Azure we had to look at:
1) SQL Agent jobs still exist but only available for SQL Managed Instances. In our context, we use Azure Single Database with GP_S_Gen5 SKU, so definitely not an option for us.
2) Elastic database jobs can run across multiple servers and allow to write DB maintenance tasks in T-SQL or PowerShell. But this feature has some limitations which has excluded it from the equation:
– It’s still in preview and we cannot rely on it for production scenarios
– Serverless and auto-pausing / auto-resuming used with our GP_S_Gen5 SKU database are not supported
3) Data factory could be an option because it is already part of the Azure Services consumed in our context, but we wanted to be decoupled from ETL / Business workflow.
4) Finally, we were interested by Data factory especially the integration with Git and Azure DevOps and the same capabilities are shipped with Azure Automation. One another important factor of decision was the cost because Azure automation runs for free until 500 minutes of job execution per month. In our context, we have a weekly-based schedule for our maintenance plan and we estimated one hour per runbook execution. Thus, we stay under the limit of additional fees.
Azure Automation brings a good control on credentials, but we already use the Azure Key Vault to protect sensitive information. We found that using Azure automation native capabilities and Azure Key Vault may be duplicate that could lead to decentralize our secret management and it more complex. Here a big picture of the process to perform the maintenance of our Azure databases from a scheduled runbook in Azure automation:
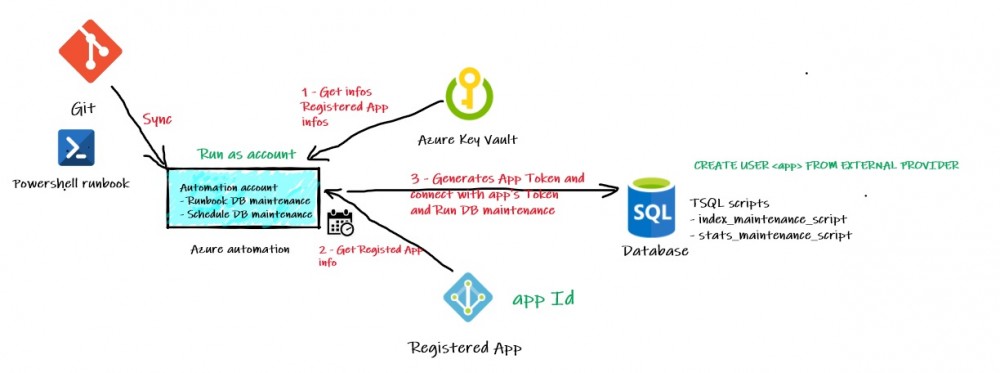
Firstly, we use a PowerShell-based runbook which in turn calls different stored procedures on the target Azure database to perform the database maintenance. To be compliant with our DevOps processes, the runbook is stored in a source control repository (Git) and published to Azure Automation through the built-in sync process. The runbook runs with “Run As Account” option to get access of Azure Key Vault and AppID for using the dedicated application identity. Finally, this identity is then used to connect to the SQL Azure DB and to perform the database maintenance based on the corresponding token authentication and granted permissions on the DB side. New token-based authentication available since the Azure SQL DB v12 and helped us to meet our security policy that prevents using SQL Logins when possible. To generate the token, we still use the old ADAL.PS module. This is something we need to update in the future.
Here a sample of interesting parts of the PowerShell code to authenticate to the Azure database:
$AzureAutomationConnectionName = "xxxx"
$ServicePrincipalConnection = Get-AutomationConnection -Name $AzureAutomationConnectionName
…
$clientId = (Get-AzKeyVaultSecret -VaultName $KeyvaultName -Name "xxxxx").SecretValueText
$response = Get-ADALToken -ClientId $clientId -ClientSecret $clientSecret -Resource $resourceUri -Authority $authorityUri -TenantId $tenantName
# Connection String
$connectionString = "Server=tcp:$SqlInstance,1433;Initial Catalog=$Database;Persist Security Info=False;MultipleActiveResultSets=False;Encrypt=True;TrustServerCertificate=False;"
# Create the connection object
$connection = New-Object System.Data.SqlClient.SqlConnection($connectionString)
# Set identity by using the corresponding token to connect to the Azure DB
$connection.AccessToken = $response.AccessToken
...
Yes, Azure is a different beast (like other Clouds) and requires from DBAs to review their habits. It may be very confusing at the beginning but everything you made in the past is possible or at least can be achieved in a different way in Azure. Just think differently would be my best advice in this case!
Ping : 2concepts