
I wrote a (dbi services) blog post concerning Linux and SQL Server IO behavior changes before and after SQL Server 2017 CU6. Now, I was looking forward seeing some new improvements with Force Unit Access (FUA) that was implemented with Linux XFS enhancements since the Linux Kernel 4.18.
As reminder, SQL Server 2017 CU6 provides added a way to guarantee data durability by using « forced flush » mechanism explained here. To cut the story short, SQL Server has strict storage requirement such as Write Ordering, FUA and things go differently on Linux than Windows to achieve durability. What is FUA and why is it important for SQL Server? From Wikipedia: Force Unit Access (aka FUA) is an I/O write command option that forces written data all the way to stable storage. FUA appeared in the SCSI command set but good news, it was later adopted by other standards over the time. SQL Server relies on it to meet WAL and ACID capabilities.
On the Linux world and before the Kernel 4.18, FUA was handled and optimized only for the filesystem journaling. However, data storage always used the multi-step flush process that could introduce SQL Server IO storage slowness (Issue write to block device for the data + issue block device flush to ensure durability with O_DSYNC).
On the Windows world, installing and using a SQL Server instance assumes you are compliant with the Microsoft storage requirements and therefore the first RTM version shipped on Linux came only with O_DIRECT assuming you already ensure that SQL Server IO are able to be written directly into a non-volatile storage through the kernel, drivers and hardware before the acknowledgement. Forced flush mechanism – based on fdatasync() – was then introduced to address scenarios with no safe DIRECT_IO capabilities.
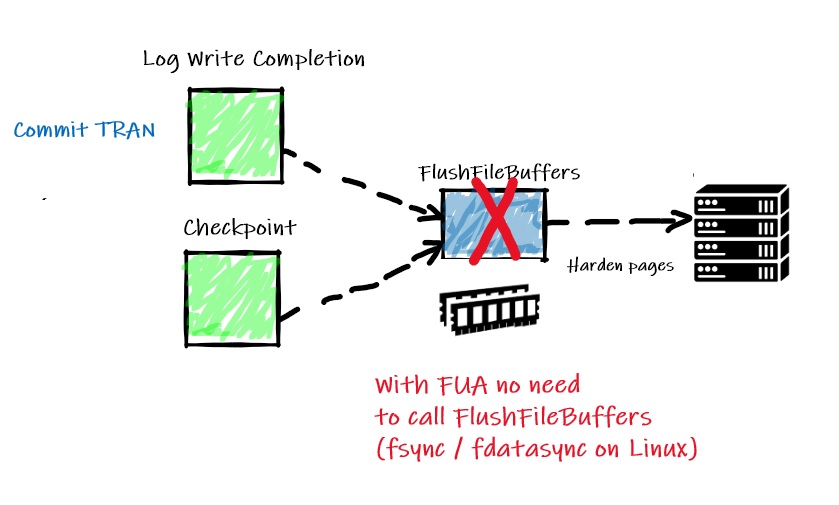
But referring to the Bob Dorr article, Linux Kernel 4.18 comes with XFS enhancements to handle FUA for data storage and it is obviously of benefit to SQL Server. FUA support is intended to improve write requests by shorten the path of write requests as shown below:
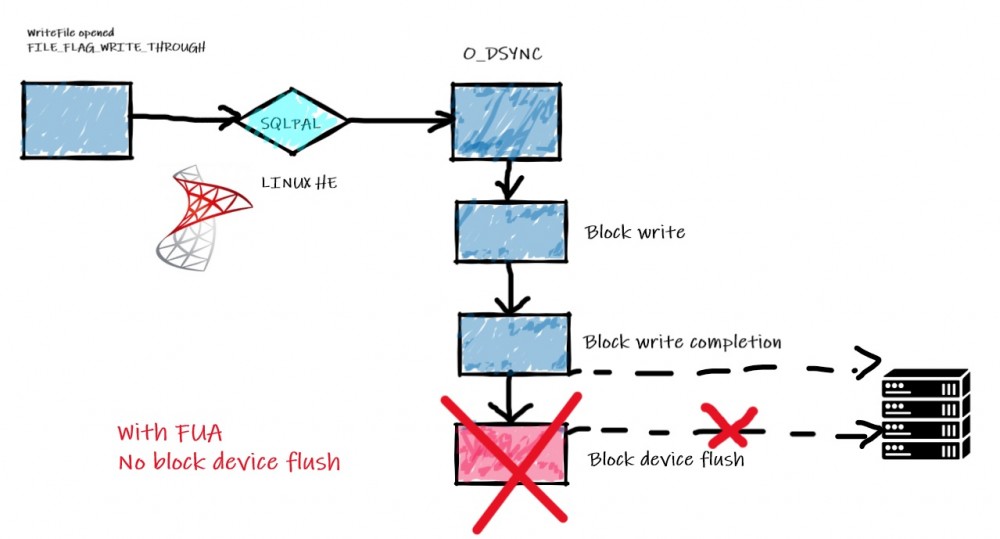
Picture from existing IO workflow on Bob Dorr’s article
This is an interesting improvement for write intensive workload and it seems to be confirmed from the tests performed by Microsoft and Bob Dorr in his article.
Let’s the experiment begins with my lab environment based on a Centos 7 on Hyper-V with an upgraded kernel version: 5.6.3-1.e17.elrepo.x86_64.
5.6.3-1.el7.elrepo.x86_64
$cat /etc/os-release | grep VERSION
VERSION="7 (Core)"
VERSION_ID="7"
CENTOS_MANTISBT_PROJECT_VERSION="7"
REDHAT_SUPPORT_PRODUCT_VERSION="7"
Let’s precise that my tests are purely experimental and instead of upgrading the Kernel to a newer version you may directly rely on RHEL 8 based distros which comes with kernel version 4.18 for example.
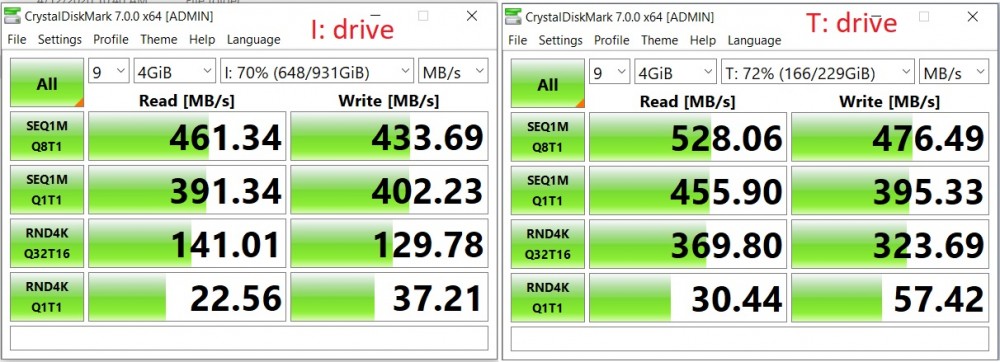
My lab environment includes 2 separate SSD disks to host the DATA + TLOG database files as follows:
I:\ drive : SQL Data volume (sdb – XFS filesystem)
T:\ drive : SQL TLog volume (sda – XFS filesystem)
The general performance is not so bad ![]()
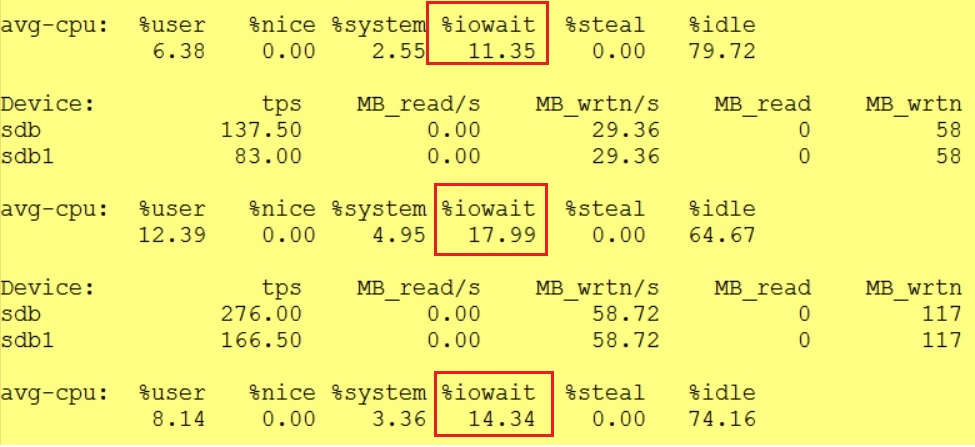
Initially I just dedicated on disk for both SQL DATA and TLOG but I quickly noticed some IO waits (iostats output) leading to make me lunconfident with my test results
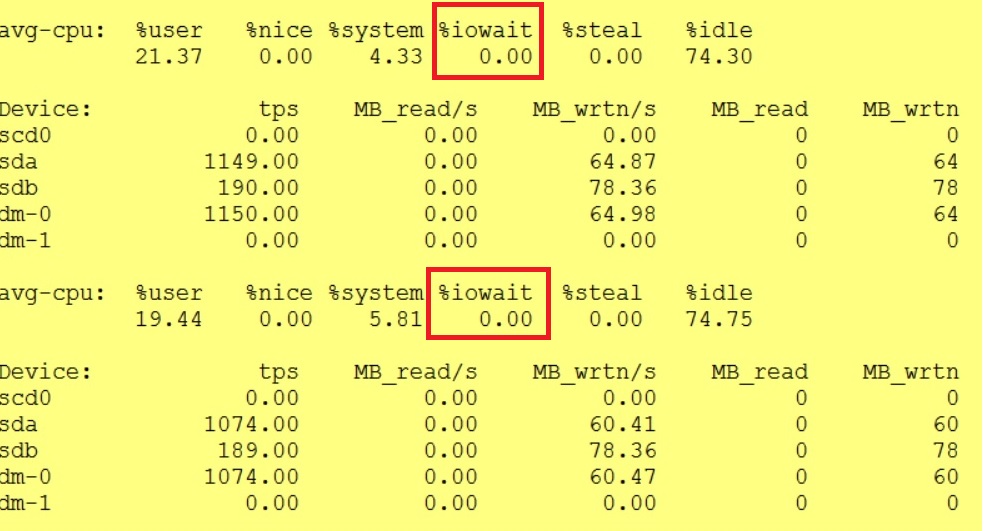
Spreading IO on physically separate volumes helped to reduce drastically these phenomena afterwards:
First, I enabled FUA capabilities on Hyper-V side as follows:
Get-VMHardDiskDrive -VMName CENTOS7 | `
ft VMName, ControllerType, ControllerLocation, Path, WriteHardeningMethod -AutoSize
Then I checked if FUA is enabled and supported from an OS perspective including sda (TLOG) and sdb (SQL DATA) disks:
NAME FSTYPE LABEL UUID MOUNTPOINT
sdb
└─sdb1 xfs 06910f69-27a3-4711-9093-f8bf80d15d72 /sqldata
sr0
sda
├─sda2 xfs f5a9bded-130f-4642-bd6f-9f27563a4e16 /boot
├─sda3 LVM2_member QsbKEt-28yT-lpfZ-VCbj-v5W5-vnVr-2l7nih
│ ├─centos-swap swap 7eebbb32-cef5-42e9-87c3-7df1a0b79f11 [SWAP]
│ └─centos-root xfs 90f6eb2f-dd39-4bef-a7da-67aa75d1843d /
└─sda1 vfat 7529-979E /boot/efi
$ dmesg | grep sda
[ 1.665478] sd 0:0:0:0: [sda] 83886080 512-byte logical blocks: (42.9 GB/40.0 GiB)
[ 1.665479] sd 0:0:0:0: [sda] 4096-byte physical blocks
[ 1.665774] sd 0:0:0:0: [sda] Write Protect is off
[ 1.665775] sd 0:0:0:0: [sda] Mode Sense: 0f 00 10 00
[ 1.670321] sd 0:0:0:0: [sda] Write cache: enabled, read cache: enabled, supports DPO and FUA
[ 1.683833] sda: sda1 sda2 sda3
[ 1.708938] sd 0:0:0:0: [sda] Attached SCSI disk
[ 5.607914] EXT4-fs (sda2): mounted filesystem with ordered data mode. Opts: (null)
Finally according to the documentation, I configured the trace flag 3979 and control.alternatewritethrough=0 parameters at startup parameters for my SQL Server instance.
$ /opt/mssql/bin/mssql-conf set control.alternatewritethrough 0
$ systemctl restart mssql-server
The first I performed was pretty similar to those in my previous (dbi services) blog post.
id INT IDENTITY,
col1 VARCHAR(2000) DEFAULT REPLICATE('T', 2000)
);
INSERT INTO dummy_test DEFAULT VALUES;
GO 67
For a sake of curiosity, I looked at the corresponding strace output:
% time seconds usecs/call calls errors syscall
------ ----------- ----------- --------- --------- ----------------
78.13 360.618066 61739 5841 2219 futex
6.88 31.731833 1511040 21 15 restart_syscall
3.81 17.592176 130312 135 io_getevents
2.95 13.607314 98604 138 epoll_wait
2.88 13.313667 633984 21 21 rt_sigtimedwait
2.60 11.997925 1333103 9 nanosleep
1.79 8.279781 242 34256 gettid
0.84 3.876021 226 17124 getcpu
0.03 0.138836 347 400 sched_yield
0.01 0.062348 254 245 getrusage
0.01 0.056065 406 138 69 readv
0.01 0.038107 343 111 read
0.01 0.037883 743 51 mmap
0.01 0.037498 180 208 epoll_ctl
0.01 0.035654 517 69 writev
0.01 0.025542 370 69 io_submit
0.00 0.019760 282 70 write
0.00 0.019555 477 41 open
0.00 0.016285 1629 10 rt_sigaction
0.00 0.012359 301 41 close
0.00 0.010069 205 49 munmap
0.00 0.006977 303 23 rt_sigprocmask
0.00 0.006256 153 41 fstat
0.00 0.004646 465 10 10 stat
0.00 0.000860 215 4 madvise
0.00 0.000321 161 2 sched_setaffinity
0.00 0.000295 148 2 set_robust_list
0.00 0.000281 141 2 clone
0.00 0.000236 118 2 sigaltstack
0.00 0.000093 47 2 arch_prctl
0.00 0.000046 23 2 sched_getaffinity
------ ----------- ----------- --------- --------- ----------------
100.00 461.546755 59137 2334 total
… And as I expected, with FUA enabled no fsync() / fdatasync() called anymore and writing to a stable storage is achieved directly by FUA commands. Now iomap_dio_rw() is determining if REQ_FUA can be used and issuing generic_write_sync() is still necessary. To dig further to the IO layer we need to rely to another tool blktrace (mentioned to the Bob Dorr’s article as well).
In my case I got to different pictures of blktrace output between forced flushed mechanism (the default) and FUA oriented IO:
-> With forced flush
34.694735000 14225 18425192 8,16 0 17165 Q WS 2048 sqlservr
34.694737000 14225 18425192 8,16 0 17166 X WS 1024 sqlservr
34.694738100 14225 18425192 8,16 0 17167 G WS 1024 sqlservr
34.694739800 14225 18426216 8,16 0 17169 G WS 1024 sqlservr
34.694740900 14225 18425192 8,16 0 17171 D WS 1024 sqlservr
34.694747200 14225 18426216 8,16 0 17174 D WS 1024 sqlservr
34.713665000 14225 0 8,16 0 17175 Q FWS 0 sqlservr
34.713668100 14225 0 8,16 0 17176 G FWS 0 sqlservr
WS (Write Synchronous) is performed but SQL Server still needs to go through the multi-step flush process with the additional FWS (PERFLUSH|WRITE|SYNC).
-> FUA
0.000000400 16305 57615336 8,0 0 2 A WFS 8 sqlservr
0.000001100 16305 57615336 8,0 0 3 Q WFS 8 sqlservr
0.000005200 16305 57615336 8,0 0 4 G WFS 8 sqlservr
0.001377800 16305 55106544 8,0 0 6 A WFS 16 sqlservr
FWS has disappeared with only WFS commands which are basically REQ_WRITE with the REQ_FUA request
I spent some times to read some interesting discussions in addition to the Bob Dorr’s wonderful article. Here an interesting pointer to a a discussion about REQ_FUA for instance.
But what about performance gain?
I had 2 simple scenarios to play with in order to bring out FUA helpfulness including the harden the dirty pages in the BP with checkpoint process and harden the log buffer to disk during the commit phase. When forced flush method is used, each component relies on additional FlushFileBuffers() function to achieve durability. This event can be easily tracked from an XE session including flush_file_buffers and make_writes_durable events.
First scenario (10K inserts within a transaction and checkpoint)
In this scenario my intention was to stress the checkpoint process with a bunch of buffers and dirty pages to flush to disk when it kicks in.
SET NOCOUNT ON;
-- Disable checkpoint to control when it will kick in
DBCC TRACEON(3505);
-- Check traceflag
DBCC TRACESTATUS;
DECLARE @i INT = 0;
DECLARE @iteration INT = 0;
DECLARE @start_upd DATETIME;
DECLARE @start_chkpt DATETIME;
DECLARE @end_upd DATETIME;
DECLARE @end_chkpt DATETIME;
TRUNCATE TABLE dummy_test;
WHILE @iteration < 251
BEGIN
SET @start_upd = GETDATE();
BEGIN TRAN;
WHILE @i <= 10000
BEGIN
INSERT INTO dummy_test DEFAULT VALUES;
SET @i += 1;
END
COMMIT TRAN;
SET @end_upd = GETDATE();
SET @i = 0;
SET @start_chkpt = GETDATE();
CHECKPOINT;
SET @end_chkpt = GETDATE();
PRINT 'INS: ' + CAST(DATEDIFF(ms, @start_upd, @end_upd) AS VARCHAR(50)) + ' - CHKPT: ' + CAST(DATEDIFF(ms, @start_chkpt, @end_chkpt) AS VARCHAR(50));
SET @iteration += 1;
END
The result is as follows:
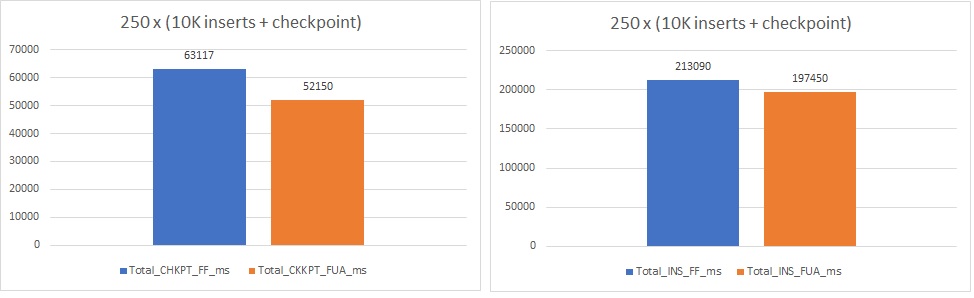
In my case, I noticed ~ 17% of improvement for the checkpoint process and ~7% for the insert transaction including the commit phase with flushing data to the TLog. In parallel, looking at the extended event aggregated output confirms that FUA avoids a lot of additional operations to persist data on disk illustrated by flush_file_buffers and make_writes_durable events.

Second scenario (100x 1 insert within a transaction and checkpoint)
In this scenario, I wanted to stress the log writer by forcing a lot of small transactions to commit. I updated the TSQL code as shown below:
SET NOCOUNT ON;
-- Disable checkpoint to control when it will kick in
DBCC TRACEON(3505);
-- Check traceflag
DBCC TRACESTATUS;
DECLARE @i INT = 0;
DECLARE @iteration INT = 0;
DECLARE @start_upd DATETIME;
DECLARE @start_chkpt DATETIME;
DECLARE @end_upd DATETIME;
DECLARE @end_chkpt DATETIME;
TRUNCATE TABLE dummy_test;
WHILE @iteration < 251
BEGIN
SET @start_upd = GETDATE();
WHILE @i <= 100
BEGIN
INSERT INTO dummy_test DEFAULT VALUES;
SET @i += 1;
END
SET @end_upd = GETDATE();
SET @i = 0;
SET @start_chkpt = GETDATE();
CHECKPOINT;
SET @end_chkpt = GETDATE();
PRINT 'INS: ' + CAST(DATEDIFF(ms, @start_upd, @end_upd) AS VARCHAR(50)) + ' - CHKPT: ' + CAST(DATEDIFF(ms, @start_chkpt, @end_chkpt) AS VARCHAR(50));
SET @iteration += 1;
END
The new picture is the following:
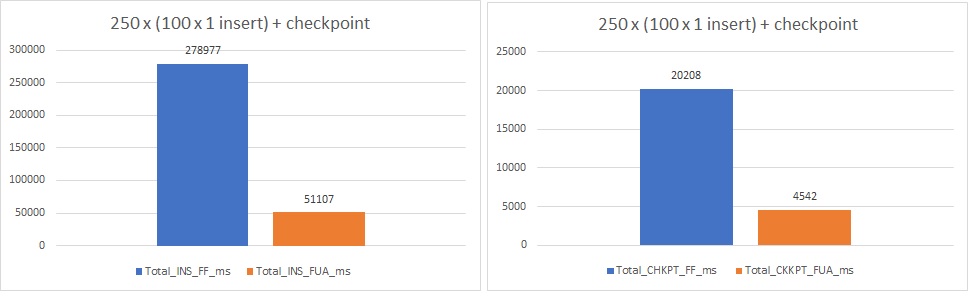
This time the improvement is definitely more impressive with a decrease of ~80% of the execution time about the INSERT + COMMIT and ~77% concerning the checkpoint phase!!!
Looking at the extended event session confirms the shorten IO path has something to do with it ![]()

Well, shortening the IO path and relying directing on initial FUA instructions was definitely a good idea both to join performance and to meet WAL and ACID capabilities. Anyway, I’m glad to see Microsoft to contribute improving to the Linux Kernel!!!
Ping : Homepage
Ping : 1distinguished