
Je vois souvent sur le forum SQL Server l’utilisation de curseurs alors qu’une vraie requĂŞte SQL pourrait le remplacer.
Outre le fait que les curseurs datent de COBOL (1956 …), et que leur spĂ©cification en COBOL et T-SQL est similaire Ă s’y mĂ©prendre, comparons donc les temps d’exĂ©cution entre un curseur et une requĂŞte sur un traitement très simple …
Ce test a été réalisé sur mon ordinateur personnel, dont voici la configuration matérielle :
– Windows XP SP3
– 2 Go de RAM
– CPU Intel Core 2 Duo Ă 2.13 GHz
Voici les requĂŞtes :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | --------------------------------- -- Nicolas SOUQUET - 05/04/2009 - --------------------------------- SET NOCOUNT ON GO CREATE TABLE BASE_DATA ( ID INT IDENTITY CONSTRAINT PK_BASE_DATA PRIMARY KEY, Nombre INT CONSTRAINT DF_BASE_DATA_Nombre DEFAULT 0 ) GO INSERT INTO dbo.BASE_DATA VALUES (DEFAULT) GO 10 |
Le contenu de la table BASE_DATA après ces deux requêtes est le suivant :
ID Nombre ----------- ----------- 1 0 2 0 3 0 4 0 5 0 6 0 7 0 8 0 9 0 10 0
Voici la requĂŞte avec le curseur :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 | --------------------------------- -- Nicolas SOUQUET - 05/04/2009 - --------------------------------- DECLARE @dateDeb DATETIME DECLARE @dateFin DATETIME DECLARE @ID INT SET @dateDeb = GETDATE() DECLARE cur CURSOR FOR SELECT ID FROM dbo.BASE_DATA FOR UPDATE OF Nombre OPEN cur FETCH NEXT FROM cur INTO @ID WHILE @@FETCH_STATUS = 0 BEGIN UPDATE dbo.BASE_DATA SET Nombre = 10 * @ID WHERE ID = @ID FETCH NEXT FROM cur INTO @ID END SET @dateFin = GETDATE() DEALLOCATE cur SELECT DATEDIFF(millisecond, @dateDeb, @dateFin) |
Et la requĂŞte avec UPDATE :
1 2 | UPDATE BASE_DATA SET Nombre = 10 * ID |
Entre chaque exĂ©cution, j’ai augmentĂ© le nombre de lignes suivant les puissances de 10 :
1 2 3 4 5 6 7 8 9 10 11 12 13 | --------------------------------- -- Nicolas SOUQUET - 05/04/2009 - --------------------------------- INSERT INTO dbo.BASE_DATA VALUES (DEFAULT) GO 90 INSERT INTO dbo.BASE_DATA VALUES (DEFAULT) GO 900 INSERT INTO dbo.BASE_DATA VALUES (DEFAULT) GO 9000 INSERT INTO dbo.BASE_DATA VALUES (DEFAULT) GO 90000 INSERT INTO dbo.BASE_DATA VALUES (DEFAULT) GO 900000 |
Entre le relevĂ© de temps d’exĂ©cutions pour le curseur et pour la requĂŞte, j’ai exĂ©cutĂ© :
TRUNCATE TABLE dbo.BASE_DATA
Et voici le résultat :
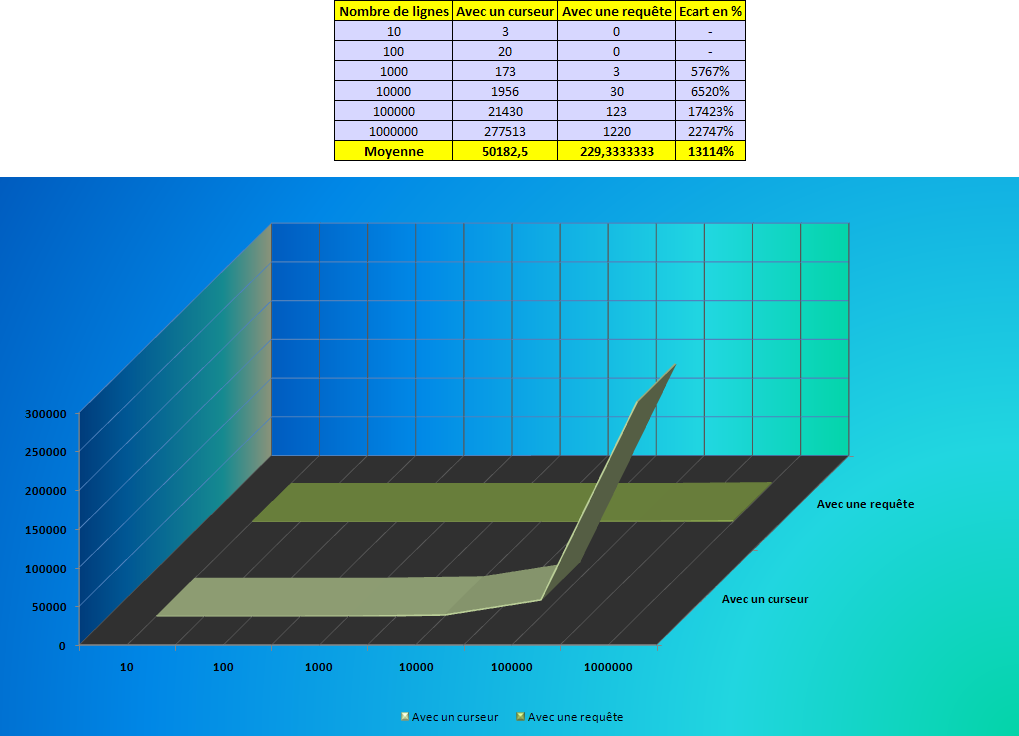
Salut elsuket.
J’ai refais le test en tenant compte de vos remarques. Voici le nouveau tableau que j’obtiens :
+———–+————–+————–+———-+
| Nombre de | Avec Curseur | Sans Curseur | Ecart |
| lignes | (Curs1) | (Curs2) | en % |
+———–+————–+————–+———-+
| 10 | 16 | 0 | – |
| 100 | 16 | 0 | – |
| 1.000 | 86 | 0 | – |
| 10.000 | 863 | 16 | 539,37 % |
| 100.000 | 8.716 | 163 | 534,72 % |
| 1.000.000 | 89.826 | 1.490 | 602,85 % |
+———–+————–+————–+———-+
| Moyenne | 99.523 | 1.669 | 593,30 % |
+———–+————–+————–+———-+
Avec curseur, j’obtiens Ă peu près la mĂŞme chose que prĂ©cĂ©demment.
Donc votre remarque, celle d’itĂ©rer 100.000 fois sur une table ne contenant que 10 lignes, n’est pas justifiĂ©e, pour la partie curseur.
Au final, l’approche sans curseur (ensembliste) reste encore bien meilleur. Cela ne remet pas en cause la conclusion de ce sujet.
Mais je ferai remarquer que mettre une surcouche (le curseur) Ă ce que sait dĂ©jĂ faire SQL Server en interne n’est pas justifiĂ© dans ce cas.
–> le traitement par curseur est simplement catastrophique.
Oui, les résultats en millisecondes sont catastrophiques.
Mais chez moi, l’Ă©cart reste stable alors que chez vous elle est en augmentation.
Comparativement, vous obtenez 13.114 %, tandis que j’obtiens 593,30 %.
Vous ĂŞtes Ă plus du double de ma performance !
Normalement, nous aurions dû trouver à peu de chose près les mêmes résultats.
@+
Salut elsuket.
[quote= »elsuket »]Outre le fait que les curseurs datent de COBOL (1956 …),[/quote]
Cobol est un langage de programmation qui est apparu en 1959.
Ensuite, ils sont apparus dans le cobol avec l’apparition de DB2, donc cela date des annĂ©es 80.
[quote= »elsuket »]comparons donc les temps d’exĂ©cution entre un curseur et une requĂŞte sur un traitement très simple …[/quote]
Faut-il comparer des choses qui sont comparables entre eux !
Tu proposes de comparer un update dans un curseur avec un insert sans mise Ă jour de la colonne.
C’est sĂ»r que le insert sera bien plus rapide que le update, mĂŞme sans curseur.
Puisque tu m’as proposĂ© de refaire ton test de comparaison, je propose de revoir les points suivants :
1) je reprends ton exemple de la création de la table sans rien modifier.
2) j’ai crĂ©Ă© deux procĂ©dures ayant la mĂŞme structure.
3) la procĂ©dure curs1 travaille avec un curseur et vient mettre Ă jour la colonne « [c]nombre[/c] »
4) la procĂ©dure curs2 modifie aussi la colonne « [c]nombre[/c] », mais par un traitement ensembliste.
5) la nouveautĂ© par rapport Ă ton test, je traite dans la procĂ©dure le nombre d’itĂ©ration.
Ainsi dix itérations va traiter 100 lignes, soit 10 itérations X 10 lignes.
Je suis sous windows 10, avec Microsoft SQL Server Express 2014.
Mon ordinateur est un HP Compaq 6830s avec un processeur deux coeurs tournant Ă 2,40 Ghz.
Voici le rĂ©sultat que j’obtiens :
[code]– ===========
— ParamĂ©trage
— ===========
SET NOCOUNT ON
— ==================
— Lien vers Database
— ==================
use tempdb
Le contexte de la base de donnĂ©es a changĂ©Â ; il est maintenant ‘tempdb’.
— ========================
— Suppression Table ‘test’
— ========================
IF OBJECT_ID(N’dbo.test’, N’U’) IS NOT NULL
DROP TABLE dbo.test
— =====================
— CrĂ©ation Table ‘test’
— =====================
create table test (
id integer identity(1, 1) not null,
nombre integer not null default 0
constraint pk_test_id primary key clustered (id)
)
— =============================
— Suppression ProcĂ©dure ‘curs1′
— =============================
IF OBJECT_ID(N’dbo.curs1′, N’P’) IS NOT NULL
DROP PROCEDURE dbo.curs1
— ==========================
— crĂ©ation procĂ©dure ‘curs1′
— ==========================
create procedure dbo.curs1
@nbre integer
as
declare @datedeb datetime = cast(current_timestamp as datetime)
declare @datefin datetime
declare @id integer
begin
declare curs cursor scroll for select id from dbo.test for update of nombre
open curs
fetch next from curs into @id
while (@nbre > 0)
begin
while (@@FETCH_STATUS = 0)
begin
update dbo.test set nombre = 10 * @id where current of curs
fetch next from curs into @id
end
fetch first from curs into @id
set @nbre = @nbre – 1
end
close curs
deallocate curs
set @datefin = cast(current_timestamp as datetime)
SELECT DATEDIFF(millisecond, @dateDeb, @dateFin) as ‘temps elaps’
end
— =============================
— Suppression ProcĂ©dure ‘curs2′
— =============================
IF OBJECT_ID(N’dbo.curs2′, N’P’) IS NOT NULL
DROP PROCEDURE dbo.curs2
— ==========================
— crĂ©ation procĂ©dure ‘curs2′
— ==========================
create procedure dbo.curs2
@nbre integer
as
declare @datedeb datetime = cast(current_timestamp as datetime)
declare @datefin datetime
begin
while (@nbre > 0)
begin
update dbo.test set nombre = 10 * id
set @nbre = @nbre – 1
end
set @datefin = cast(current_timestamp as datetime)
SELECT DATEDIFF(millisecond, @dateDeb, @dateFin) as ‘temps elaps’
end
— =====================
— Insertion dans ‘test’
— =====================
insert into test (nombre) values (0), (0), (0), (0), (0), (0), (0), (0), (0), (0)
— ================
— Vidage de ‘test’
— ================
select * from test;
id nombre
———– ———–
1 0
2 0
3 0
4 0
5 0
6 0
7 0
8 0
9 0
10 0
— =================
— procĂ©dure ‘curs1′
— =================
execute dbo.curs1 1
temps elaps
———–
16
execute dbo.curs1 10
temps elaps
———–
16
execute dbo.curs1 100
temps elaps
———–
83
execute dbo.curs1 1000
temps elaps
———–
816
execute dbo.curs1 10000
temps elaps
———–
7896
execute dbo.curs1 100000
temps elaps
———–
80116
— =================
— procĂ©dure ‘curs2′
— =================
execute dbo.curs2 1
temps elaps
———–
0
execute dbo.curs2 10
temps elaps
———–
0
execute dbo.curs2 100
temps elaps
———–
13
execute dbo.curs2 1000
temps elaps
———–
70
execute dbo.curs2 10000
temps elaps
———–
380
execute dbo.curs2 100000
temps elaps
———–
3933
Appuyez sur une touche pour continuer…[/code]
Je te donne, sous forme de tableau, le récapitulatif des résultats de ce test :
[code]
+———–+————–+————–+———-+
| Nombre de | Avec Curseur | Sans Curseur | Ecart |
| lignes | (Curs1) | (Curs2) | en % |
+———–+————–+————–+———-+
| 10 | 16 | 0 | – |
| 100 | 16 | 0 | – |
| 1.000 | 83 | 13 | 63.84 % |
| 10.000 | 816 | 70 | 116,57 % |
| 100.000 | 7.896 | 380 | 207,78 % |
| 1.000.000 | 80.116 | 3.933 | 203,70 % |
+———–+————–+————–+———-+
| Moyenne | 88.943 | 4.396 | 202,32 % |
+———–+————–+————–+———-+[/code]
Je n’obtiens pas du tout les mĂŞmes rĂ©sultats que toi, mĂŞme si le traitement par curseur (Curs1) est plus long que le traitement ensembliste (curs2)
Dans ton traitement avec curseur, le « [c]update[/c] » sur le curseur ne se fait pas comme tu l’as fait.
La bonne façon de mettre à joueur un curseur est comme ci-après :
[code]update dbo.test set nombre = 10 * @id [color=red]where current of curs[/color][/code]
il est inutile de prĂ©ciser la ligne par un « [c]where id = @id[/c] » car tu es dĂ©jĂ positionnĂ© sur la ligne courante.
tandis que sans curseur, la mise Ă jour se fait ainsi :
[code]update dbo.test set nombre = 10 * id[/code]
Il y a peu de différence entre ces deux écritues.
La différence se fait sur la simulation par curseur, de ce que fait en interne SQL Server par la requête ensembliste.
Sinon, je trouve tes résultats (13.114,00 %) six fois moins bon que les miens (202,32 %).
@+
Je compare des choses comparables. L’UPDATE est fait soit ligne Ă ligne avec un curseur, soit d’un tir en une seule instruction.
L’INSERT permet seulement d’augmenter le nombre de lignes sur lequel on teste les deux approches. Ce n’est pas la durĂ©e de l’INSERT que l’on mesure. D’oĂą le tableau qui montre le nombre de lignes de la table suivant les puissances de 10 : c’est ce que fait l’INSERT et que j’ai mis en commentaire, et le commentaire suivant dans l’exposition des rĂ©sultats :
« Entre chaque exĂ©cution, j’ai augmentĂ© le nombre de lignes suivant les puissances de 10″.
Evidemment vous n’obtenez pas les mĂŞme rĂ©sultats que moi parce que vous UPDATEz en boucle le mĂŞme nombre de lignes ! Mettre Ă jour 10 lignes seulement, en boucle, ce n’est pas un test : 10 lignes c’est de la gnognotte, et ce n’est pas rĂ©aliste : aucun traitement business ne fait cela sur une base de donnĂ©es relationnelle SQL, ou alors c’est une erreur !
C’est pour ça que j’augmente le nombre de lignes de la table, et que l’on voit clairement que quand le nombre de lignes de la table augmente, le traitement par curseur est simplement catastrophique.
Vous avez une fâcheuse tendance Ă confondre 3 lignes qui se battent en duel dans une table, avec des tables qui en contiennent des millions voire des milliards. Or c’est Ă cela que l’on mesure des performances : mettre Ă jour 10 lignes en boucle peut ĂŞtre fait avec Excel.
Regardez comme je vous l’ai indiquĂ© les tests TPC, et travaillez sur bases de donnĂ©es qui supportent une charge OLTP ou OLAP et dont le volume se mesure en centaines de Go, ou en To, ou plus encore. Une fois votre implĂ©mentation faite avec des curseurs, vous me direz ce que votre employeur ou client en pense : je serai ravi de vous voir le partager ici !