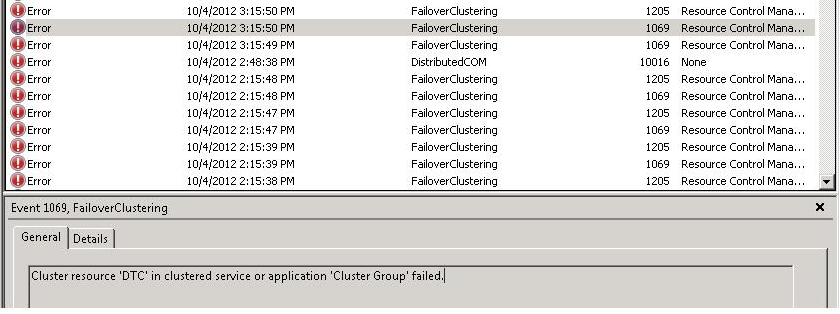
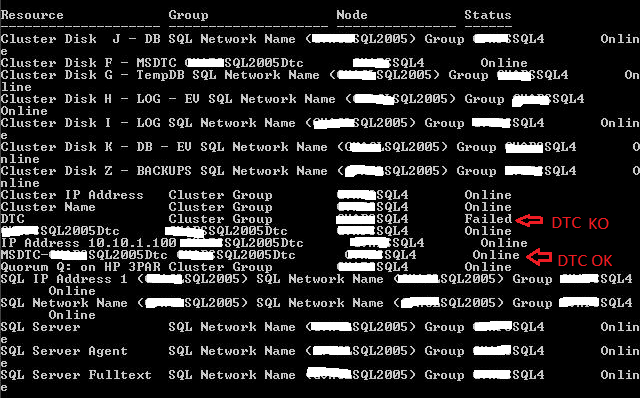
La vĂ©rification d’intĂ©gritĂ© des bases de donnĂ©es s’effectue par la commande DBCC CHECKDB. Le rĂ©sultat de cette commande est assez verbeuse par dĂ©faut et peut poser problème lorsque la vĂ©rification d’intĂ©gritĂ© est utilisĂ© dans des scripts T-SQL personnalisĂ©s de maintenance par exemple.
Posons un peu le contexte et le pourquoi de ce billet. En rĂ©alitĂ© j’ai eu l’occasion de travailler (comme beaucoup je pense) sur la crĂ©ation de plans de maintenance "custom". L’idĂ©e a Ă©tĂ© de construire un jeu de script permettant de pouvoir gĂ©rer l’ensemble des tâches que l’on peut avoir Ă utiliser pour la maintenance des bases de donnĂ©es. Une de ces tâches concerne la vĂ©rification d’intĂ©gritĂ© des bases. Cette vĂ©rification se fait Ă l’aide de la commande bien connue DBCC CHECKDB. Dans notre contexte l’idĂ©e est de pouvoir exĂ©cuter une tâche de maintenance et d’enregistrer dans une table de log les donnĂ©es suivantes :
- Nom de la tâche
- Nom de la base concernée
- Durée de la tâche
- Statut de la tâche (OK ou en échec)
- Envoi par mail des tâches en Ă©chec Ă posteriori avec le dĂ©tail de l’erreur
Ceci nous permet d’avoir une traçabilitĂ© des tâches de maintenance par la suite et pouvoir les consommer Ă des fins d’analyse.
Lorsque l’on scripte une vĂ©rification d’intĂ©gritĂ© Ă l’aide de la commande DBCC CHECKDB on s’aperçoit rapidement que la gestion des erreurs liĂ©es Ă cette commande n’est pas triviale. C’est que nous verrons dans le cadre de ce billet.
 Une sortie verbeuse
Une sortie verbeuse
Voici la sortie d’une commande DBCC CHECKDB sur une base de donnĂ©es corrompue :
DBCC CHECKDB ('DemoCorruptMetadata')
DBCC results for ‘DemoCorruptMetadata’.
Service Broker Msg 9675, State 1: Message Types analyzed: 14.
Service Broker Msg 9676, State 1: Service Contracts analyzed: 6.
Service Broker Msg 9667, State 1: Services analyzed: 3.
Service Broker Msg 9668, State 1: Service Queues analyzed: 3.
Service Broker Msg 9669, State 1: Conversation Endpoints analyzed: 0.
Service Broker Msg 9674, State 1: Conversation Groups analyzed: 0.
Service Broker Msg 9670, State 1: Remote Service Bindings analyzed: 0.
Service Broker Msg 9605, State 1: Conversation Priorities analyzed: 0.
Msg 8992, Level 16, State 1, Line 1
Check Catalog Msg 3853, State 1: Attribute (object_id=1977058079) of row (object_id=1977058079,column_id=1) in sys.columns does not have a matching row (object_id=1977058079) in sys.objects.
Msg 8992, Level 16, State 1, Line 1
Check Catalog Msg 3853, State 1: Attribute (object_id=1977058079) of row (object_id=1977058079,column_id=2) in sys.columns does not have a matching row (object_id=1977058079) in sys.objects.
CHECKDB found 0 allocation errors and 2 consistency errors not associated with any single object.
DBCC results for ‘sys.sysrscols’.
There are 872 rows in 9 pages for object "sys.sysrscols".
DBCC results for ‘sys.sysrowsets’.
There are 124 rows in 1 pages for object "sys.sysrowsets".
DBCC results for ‘sys.sysclones’.
There are 0 rows in 0 pages for object "sys.sysclones".
DBCC results for ‘sys.sysallocunits’.
There are 138 rows in 2 pages for object "sys.sysallocunits".
DBCC results for ‘sys.sysfiles1′.
There are 2 rows in 1 pages for object "sys.sysfiles1".
DBCC results for ‘sys.sysseobjvalues’.
There are 0 rows in 0 pages for object "sys.sysseobjvalues".
DBCC results for ‘sys.syspriorities’.
There are 0 rows in 0 pages for object "sys.syspriorities".
DBCC results for ‘sys.sysdbfrag’.
There are 0 rows in 0 pages for object "sys.sysdbfrag".
DBCC results for ‘sys.sysfgfrag’.
There are 0 rows in 1 pages for object "sys.sysfgfrag".
DBCC results for ‘sys.sysdbfiles’.
There are 2 rows in 1 pages for object "sys.sysdbfiles".
DBCC results for ‘sys.syspru’.
There are 0 rows in 0 pages for object "sys.syspru".
DBCC results for ‘sys.sysbrickfiles’.
There are 0 rows in 0 pages for object "sys.sysbrickfiles".
DBCC results for ‘sys.sysphfg’.
There are 1 rows in 1 pages for object "sys.sysphfg".
DBCC results for ‘sys.sysprufiles’.
There are 2 rows in 1 pages for object "sys.sysprufiles".
DBCC results for ‘sys.sysftinds’.
There are 0 rows in 0 pages for object "sys.sysftinds".
DBCC results for ‘sys.sysowners’.
There are 14 rows in 1 pages for object "sys.sysowners".
DBCC results for ‘sys.sysdbreg’.
There are 0 rows in 0 pages for object "sys.sysdbreg".
DBCC results for ‘sys.sysprivs’.
There are 136 rows in 1 pages for object "sys.sysprivs".
DBCC results for ‘sys.sysschobjs’.
There are 2180 rows in 29 pages for object "sys.sysschobjs".
DBCC results for ‘sys.syscolpars’.
There are 698 rows in 11 pages for object "sys.syscolpars".
DBCC results for ‘sys.sysxlgns’.
There are 0 rows in 0 pages for object "sys.sysxlgns".
DBCC results for ‘sys.sysxsrvs’.
There are 0 rows in 0 pages for object "sys.sysxsrvs".
DBCC results for ‘sys.sysnsobjs’.
There are 1 rows in 1 pages for object "sys.sysnsobjs".
DBCC results for ‘sys.sysusermsgs’.
There are 0 rows in 0 pages for object "sys.sysusermsgs".
DBCC results for ‘sys.syscerts’.
There are 0 rows in 0 pages for object "sys.syscerts".
DBCC results for ‘sys.sysrmtlgns’.
There are 0 rows in 0 pages for object "sys.sysrmtlgns".
DBCC results for ‘sys.syslnklgns’.
There are 0 rows in 0 pages for object "sys.syslnklgns".
DBCC results for ‘sys.sysxprops’.
There are 0 rows in 0 pages for object "sys.sysxprops".
DBCC results for ‘sys.sysscalartypes’.
There are 34 rows in 1 pages for object "sys.sysscalartypes".
DBCC results for ‘sys.systypedsubobjs’.
There are 0 rows in 0 pages for object "sys.systypedsubobjs".
DBCC results for ‘sys.sysidxstats’.
There are 130 rows in 1 pages for object "sys.sysidxstats".
DBCC results for ‘sys.sysiscols’.
There are 317 rows in 3 pages for object "sys.sysiscols".
DBCC results for ‘sys.sysendpts’.
There are 0 rows in 0 pages for object "sys.sysendpts".
DBCC results for ‘sys.syswebmethods’.
There are 0 rows in 0 pages for object "sys.syswebmethods".
DBCC results for ‘sys.sysbinobjs’.
There are 23 rows in 1 pages for object "sys.sysbinobjs".
DBCC results for ‘sys.sysaudacts’.
There are 0 rows in 0 pages for object "sys.sysaudacts".
DBCC results for ‘sys.sysobjvalues’.
There are 134 rows in 13 pages for object "sys.sysobjvalues".
DBCC results for ‘sys.syscscolsegments’.
There are 0 rows in 0 pages for object "sys.syscscolsegments".
DBCC results for ‘sys.syscsdictionaries’.
There are 0 rows in 0 pages for object "sys.syscsdictionaries".
DBCC results for ‘sys.sysclsobjs’.
There are 16 rows in 1 pages for object "sys.sysclsobjs".
DBCC results for ‘sys.sysrowsetrefs’.
There are 0 rows in 0 pages for object "sys.sysrowsetrefs".
DBCC results for ‘sys.sysremsvcbinds’.
There are 0 rows in 0 pages for object "sys.sysremsvcbinds".
DBCC results for ‘sys.sysxmitqueue’.
There are 0 rows in 0 pages for object "sys.sysxmitqueue".
DBCC results for ‘sys.sysrts’.
There are 1 rows in 1 pages for object "sys.sysrts".
DBCC results for ‘sys.sysconvgroup’.
There are 0 rows in 0 pages for object "sys.sysconvgroup".
DBCC results for ‘sys.sysdesend’.
There are 0 rows in 0 pages for object "sys.sysdesend".
DBCC results for ‘sys.sysdercv’.
There are 0 rows in 0 pages for object "sys.sysdercv".
DBCC results for ‘sys.syssingleobjrefs’.
There are 156 rows in 1 pages for object "sys.syssingleobjrefs".
DBCC results for ‘sys.sysmultiobjrefs’.
There are 107 rows in 1 pages for object "sys.sysmultiobjrefs".
DBCC results for ‘sys.sysguidrefs’.
There are 0 rows in 0 pages for object "sys.sysguidrefs".
DBCC results for ‘sys.sysfoqueues’.
There are 0 rows in 0 pages for object "sys.sysfoqueues".
DBCC results for ‘sys.syschildinsts’.
There are 0 rows in 0 pages for object "sys.syschildinsts".
DBCC results for ‘sys.syscompfragments’.
There are 0 rows in 0 pages for object "sys.syscompfragments".
DBCC results for ‘sys.sysftsemanticsdb’.
There are 0 rows in 0 pages for object "sys.sysftsemanticsdb".
DBCC results for ‘sys.sysftstops’.
There are 0 rows in 0 pages for object "sys.sysftstops".
DBCC results for ‘sys.sysftproperties’.
There are 0 rows in 0 pages for object "sys.sysftproperties".
DBCC results for ‘sys.sysxmitbody’.
There are 0 rows in 0 pages for object "sys.sysxmitbody".
DBCC results for ‘sys.sysfos’.
There are 0 rows in 0 pages for object "sys.sysfos".
DBCC results for ‘sys.sysqnames’.
There are 100 rows in 1 pages for object "sys.sysqnames".
DBCC results for ‘sys.sysxmlcomponent’.
There are 100 rows in 1 pages for object "sys.sysxmlcomponent".
DBCC results for ‘sys.sysxmlfacet’.
There are 112 rows in 1 pages for object "sys.sysxmlfacet".
DBCC results for ‘sys.sysxmlplacement’.
There are 19 rows in 1 pages for object "sys.sysxmlplacement".
DBCC results for ‘sys.sysobjkeycrypts’.
There are 0 rows in 0 pages for object "sys.sysobjkeycrypts".
DBCC results for ‘sys.sysasymkeys’.
There are 0 rows in 0 pages for object "sys.sysasymkeys".
DBCC results for ‘sys.syssqlguides’.
There are 0 rows in 0 pages for object "sys.syssqlguides".
DBCC results for ‘sys.sysbinsubobjs’.
There are 3 rows in 1 pages for object "sys.sysbinsubobjs".
DBCC results for ‘sys.syssoftobjrefs’.
There are 0 rows in 0 pages for object "sys.syssoftobjrefs".
DBCC results for ‘sys.queue_messages_1993058136′.
There are 0 rows in 0 pages for object "sys.queue_messages_1993058136".
DBCC results for ‘sys.queue_messages_2025058250′.
There are 0 rows in 0 pages for object "sys.queue_messages_2025058250".
DBCC results for ‘sys.queue_messages_2057058364′.
There are 0 rows in 0 pages for object "sys.queue_messages_2057058364".
DBCC results for ‘sys.filestream_tombstone_2089058478′.
There are 0 rows in 0 pages for object "sys.filestream_tombstone_2089058478".
DBCC results for ‘sys.syscommittab’.
There are 0 rows in 0 pages for object "sys.syscommittab".
DBCC results for ‘sys.filetable_updates_2121058592′.
There are 0 rows in 0 pages for object "sys.filetable_updates_2121058592".
CHECKDB found 0 allocation errors and 2 consistency errors in database ‘DemoCorruptMetadata’.
DBCC execution completed. If DBCC printed error messages, contact your system administrator.
On se rend vite compte que la quantitĂ© d’information qui nous intĂ©resse ici reste nĂ©gligeable par rapport Ă la quantitĂ© totale d’information produite en sortie par notre commande. Ici la commande DBCC CHECKDB a produit 162 lignes d’information alors que moins de 10 lignes nous intĂ©resse ici. Heureusement pour nous, nous pouvons jouer avec les options NO_INFOMSGS et ALL_ERRORMSGS pour limiter le nombre d’informations produites par DBCC CHECKDB. Pour rappel NO_INFOMSGS permet d’Ă©liminer les messages d’information produites en sortie et ALL_ERRORMSGS permet d’afficher toutes les erreurs rencontrĂ©es lors d’une opĂ©ration de vĂ©rification de bases de donnĂ©es. Par dĂ©faut seulement les 1000 premiers messages d’erreur sont affichĂ©s depuis SQL Server Management Studio.
 Utilisation des options NO_INFOMSGS, ALL_ERRORMSGS
Utilisation des options NO_INFOMSGS, ALL_ERRORMSGS
DBCC CHECKDB ('DemoCorruptMetadata') WITH NO_INFOMSGS, ALL_ERRORMSGS
Msg 8992, Level 16, State 1, Line 1
Check Catalog Msg 3853, State 1: Attribute (object_id=1977058079) of row (object_id=1977058079,column_id=1) in sys.columns does not have a matching row (object_id=1977058079) in sys.objects.
Msg 8992, Level 16, State 1, Line 1
Check Catalog Msg 3853, State 1: Attribute (object_id=1977058079) of row (object_id=1977058079,column_id=2) in sys.columns does not have a matching row (object_id=1977058079) in sys.objects.
CHECKDB found 0 allocation errors and 2 consistency errors not associated with any single object.
CHECKDB found 0 allocation errors and 2 consistency errors in database ‘DemoCorruptMetadata’.
On a ici bien rĂ©duit le nombre de lignes produites par notre commande DBCC CHECKDB avec l’affichage du dĂ©tail des erreurs rencontrĂ©es et 2 messages d’information qui ne sont ni plus ni moins qu’un rĂ©capitulatif de ces erreurs.
 Gestion de la sortie de la commande DBCC CHECKDB dans un script T-SQL
Gestion de la sortie de la commande DBCC CHECKDB dans un script T-SQL
Après avoir limitĂ© le nombre d’information utiles comment nous en servir pour construire une logique de maintenance par script ? L’idĂ©e ici est simplement de pouvoir dĂ©tecter un problème d’intĂ©gritĂ© et de prĂ©venir les personnes concernĂ©es (notamment l’Ă©quipe DBA) qu’un problème est survenu Ă ce moment lĂ
A priori 2 voies d’exploitation Ă©videntes peuvent ĂŞtre prises en compte :
- On peut utiliser la variable @@ERROR et vérifier que celle-ci soit différente de 0
- On peut utiliser les blocs de gestions d’erreur TRY CATCH
Avec la variable @@ERROR :
dbcc checkdb('DemoCorruptMetadata') WITH no_infomsgs, all_errormsgs;
IF @@ERROR <>0
BEGIN
print '';
print '--> error during dbcc checkdb';
END
Msg 8992, Level 16, State 1, Line 1
Check Catalog Msg 3853, State 1: Attribute (object_id=1977058079) of row (object_id=1977058079,column_id=1) in sys.columns does not have a matching row (object_id=1977058079) in sys.objects.
Msg 8992, Level 16, State 1, Line 1
Check Catalog Msg 3853, State 1: Attribute (object_id=1977058079) of row (object_id=1977058079,column_id=2) in sys.columns does not have a matching row (object_id=1977058079) in sys.objects.
CHECKDB found 0 allocation errors and 2 consistency errors not associated with any single object.
CHECKDB found 0 allocation errors and 2 consistency errors in database ‘DemoCorruptMetadata’.
–> error during dbcc checkdb
La variable @@ERROR nous permet effectivement de pouvoir dĂ©tecter les erreurs engendrĂ©es par la commande DBCC CHECKDB. Il suffit ensuite de coder la logique de maintenance qui nous intĂ©resse. Cependant si on utilise notre script T-SQL dans un job SQL Server, les erreurs produites impliqueront une Ă©tape de job en Ă©chec. La question est donc de savoir ce rĂ©sultat est attendu ou non ? Effectivement ce n’est pas parce qu’une commande DBCC CHECKDB produit une erreur qu’un job SQL Server doit forcĂ©ment partir en Ă©chec. En rĂ©alitĂ© tout dĂ©pendra de la logique d’exĂ©cution globale concernĂ©e par ce script. On peut tout Ă fait traiter l’erreur de job et effectuer une surveillance sur l’Ă©tat de ce job par envoi d’alerte ou via des outils tiers par exemple. On peut aussi vouloir enregistrer l’erreur sans que le job parte en Ă©chec, avec l’exĂ©cution d’Ă©tapes supplĂ©mentaires sans pour autant avoir une logique d’exĂ©cution complexe du style "si Ă©tape 1 Ă©chec –> aller Ă l’Ă©tape 3 sinon aller Ă l’Ă©tape 2 etc … A mon humble avis les jobs SQL Server ne sont pas vraiment dĂ©signĂ©s pour gĂ©rer des logiques complexes de workflow . Dans le cadre de notre script nous avons retenu une solution gĂ©nĂ©rique et simple : si une tâche gĂ©nère une erreur alors celle-ci est enregistrĂ©e dans une table de log et l’information pourra ĂŞtre envoyĂ© Ă posteriori par email. Le choix est laissĂ© Ă l’utilisateur final.
Avec le bloc de gestion d’erreur BEGIN TRY, CATCH :
BEGIN try
dbcc checkdb('DemoCorruptMetadata') WITH no_infomsgs, all_errormsgs;
END try
BEGIN catch
print '--> error during dbcc checkdb';
END catch
CHECKDB found 0 allocation errors and 2 consistency errors not associated with any single object.
CHECKDB found 0 allocation errors and 2 consistency errors in database ‘DemoCorruptMetadata’.
Comme on peut le remarquer le bloc de gestion TRY , CATCH ne va malheureusement pas nous ĂŞtre d’une grande utilitĂ© ici car les dernières lignes d’information produites par la commande DBCC CHECKDB empĂŞchent notre bloc de gestion d’erreur de dĂ©tecter les erreurs produites par notre commande DBCC CHECKDB quelques lignes plus haut.
Avons nous une autre alternative dans ce cas ? La rĂ©ponse est oui. Il est Ă©galement possible d’enregistrer les erreurs produites lors d’une vĂ©rification d’intĂ©gritĂ© dans une table SQL en utilisant l’option TABLERESULTS de cette manière :
 Utilisation de l’option TABLERESULTS
Utilisation de l’option TABLERESULTS
DBCC CHECKDB('DemoCorruptMetadata')
WITH NO_INFOMSGS, ALL_ERRORMSGS, TABLERESULTS

Il suffit ici d’extraire les informations produites dans la table et de gĂ©rer sa propre logique de maintenance. Dans mon cas je remplis une variable de table avec le rĂ©sultat de la commande DBCC CHECKDB et l’option TABLERESULETS et je vĂ©rifie qu’au moins une ligne existe pour dĂ©tecter la prĂ©sence d’une erreur (la commande DBCC CHECKDB ne produit aucune ligne d’erreur si aucun problème d’intĂ©gritĂ© n’est dĂ©tectĂ©). L’information est ensuite enregistrĂ©e dans une table de log avec le numĂ©ro d’erreur et sera envoyĂ© par mail Ă postĂ©riori.
L’option TABLERESULTS est-elle lĂ solution miracle ? Malheureusement non car la commande DBCC CHECKDB peut produire certaines erreurs propres Ă son exĂ©cution et qui stopper franchement le script en cours d’exĂ©cution. C’est le cas de certaines erreurs sĂ©vères rencontrĂ©s par la commande DBCC CHECKDB.
 Gestion des erreurs liĂ©es Ă l’exĂ©cution mĂŞme de la commande DBCC CHECKDB
Gestion des erreurs liĂ©es Ă l’exĂ©cution mĂŞme de la commande DBCC CHECKDB
Voici quelques cas oĂą l’exĂ©cution de la commande DBCC CHECKDB provoquera une erreur grave et un arrĂŞt net du script T-SQL en cours d’exĂ©cution.
- Après avoir corrompu la page PFS (page id = 1) Ă l’aide d’un Ă©diteur hexadĂ©cimal de ma base DemoCorruptMetada le script SQL se stoppera net avec le message d’erreur suivant :
Msg 0, Level 11, State 0, Line 0
A severe error occured on the current command. The results, if any, should be discarded
- De la mĂŞme manière Après avoir supprimer une ligne dans la table système sys.syscolpars en redĂ©marrant l’instance SQL Server en mode mono utilisateur et se connectant en mode administrateur dĂ©diĂ© la commande DBCC CHECKDB gĂ©nère le message suivant :
Msg 0, Level 20, State 0, Line 0
A severe error occured on the current command. The results, if any, should be discarded
Pour une description des niveaux d’erreurs voir la documentation en ligne SQL Server (section "Understanding DBCC errors messages"). Dans ce cas il faudra effectivement gĂ©rer l’erreur de manière diffĂ©rente. Dans mon cas au dĂ©but de chaque tâche une ligne est enregistrĂ©e dans une table de log. Si le script T-SQL est arrĂŞtĂ© a date de fin de la tâche ne sera pas renseignĂ©. Un email est envoyĂ© pour les cas suivants :
- Le statut de la tâche est égale à false
- Le statut de la tâche est inconnu ou la date de fin d’une tâche n’est pas renseignĂ©e
Bonne gestion d’erreur !!
David BARBARIN (Mikedavem)
MVP SQL Server









































































_1262")