décembre
2010
 Un article de zinzineti
Un article de zinzineti

On entend souvent dire qu’il faut poser des index sur les clés étrangères (FK) pour optimiser les requêtes. S’agit-il de créer automatiquement des index sur les colonnes FK pour aider l’optimiseur de requêtes ? Examinons le problème à partir d’un exemple simple.
——————————————————
–> Petit rappel pour analyser un plan d’exécution
——————————————————
Les opérateurs indiquant une bonne performance des requêtes :
¤ Index Seek
¤ Nested Loops
¤ Merge Join
Les opérateurs indiquant une mauvaise performance des requêtes :
¤ Table Scan
¤ Index Scan
¤ Sort
¤ Hash Join
——————————————————
–> Création et chargement des tables
——————————————————
DROP TABLE dbo.T_FILLE
DROP TABLE dbo.T_PARENT
CREATE TABLE dbo.T_PARENT
(
idp INT NOT NULL PRIMARY KEY,
valp varchar(20) NOT NULL
)
CREATE TABLE dbo.T_FILLE
(
idf INT NOT NULL PRIMARY KEY,
idp INT NOT NULL CONSTRAINT FK_idp FOREIGN KEY REFERENCES T_PARENT(idp),
valf VARCHAR(20) NOT NULL
)
– Chargement des tables
DECLARE @counter int;
SET @counter = 1;
WHILE @counter <= 100
BEGIN
INSERT INTO T_PARENT(idp,valp) VALUES(@counter,'parent'+ convert(varchar(5),@counter));
INSERT INTO T_FILLE(idf,idp,valf) VALUES(@counter,@counter,'fille'+convert(varchar(5),@counter));
SET @counter = @counter + 1
END;
Activons l’indicateur de performance
SET STATISTICS IO ON
Puis exécutons la requête suivante
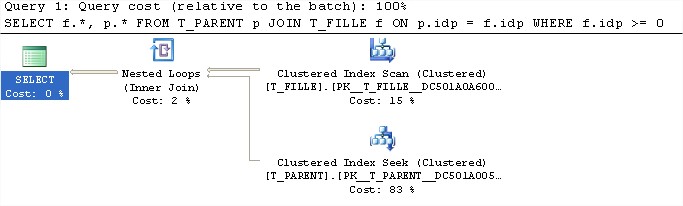
SELECT f.*, p.*
FROM T_PARENT p JOIN T_FILLE f ON p.idp = f.idp
WHERE f.idp >= 0
–Résultat : Index Scan sur la table T_FILLE et Clustered Index sur la table T_PARENT.
Table ‘T_PARENT’ lectures logiques 200
Table ‘T_FILLE’ lectures logiques 2
–Créons un index sur la colonne FK
CREATE INDEX IX_NC_idp ON T_FILLE (idp)
–Testons la requête initiale, après création de l’index IX_NC_idp sur la FK
SELECT f.*, p.*
FROM T_PARENT p JOIN T_FILLE f ON p.idp = f.idp
WHERE f.idp >= 0
–Résultat : Index Scan sur la table T_FILLE et Clustered Index sur la table T_PARENT.
Table ‘T_PARENT’ lectures logiques 200
Table ‘T_FILLE’ lectures logiques 2
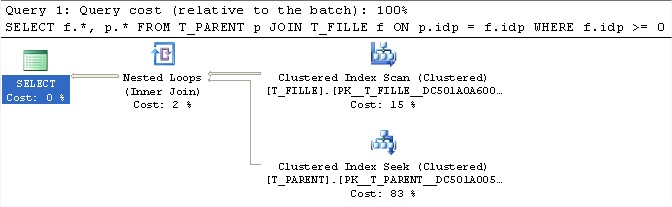
La création d’index sur la colonne FK n’a apporté aucune amélioration notable sur la performance de la requête !
–Supprimons maintenant l’index IX_NC_idp et Créons un index sur la FK avec colonnes incluses
DROP INDEX IX_NC_idf ON T_FILLE
CREATE INDEX IX_NC_idp_INCLUDE_idf_valf ON T_FILLE (idp) INCLUDE (idf,valf)
Puis testons à nouveau la requête initiale.
–Résultat : Index Seek sur les deux tables : T_FILLE et T_PARENT.
Table ‘T_PARENT’ lectures logiques 2
Table ‘T_FILLE’ lectures logiques 2
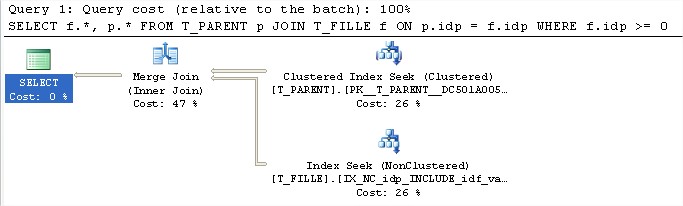
Que pouvons-nous retenir de cet exemple rapide ?
Que les colonnes de clé étrangère sont souvent employées dans les critères de jointure. Et poser un index approprié sur une clé étrangère aide le moteur SQL à rechercher rapidement des données associées dans la table de clés étrangères. Donc il ne s’agit pas de créer aveuglement des index sur les colonnes FK !
Si la création systématique des index sur les colonnes FK apportait un avantage indéniable, Microsoft l’aurait implémenter ! Et le fait de ne pas créér bêtement des index sur les FK a du sens lorsqu’on essaye de comprendre à quoi servent (et comment marche)
clé primaire – clé étrangère – index.
—————————————————————————-
Auteur : Etienne ZINZINDOHOUE
—————————————————————————-
Désolé mais cette démonstration est entièrement basée sur un exemple trivial.
Déjà, vous y avez une relation 1 – 1.
Ensuite, en plus d’être posé sur la table enfant, votre filtre (>= 0) renverra toutes les lignes de la table enfants.
Alors un query qui renvoi 100% des enfant, chacun bilatéralement lié à strictement 1 parent ne peut se conclure que par 2 full scan.
Faites un exemple ou chaque parents à un ou plusieurs enfants et posez une condition portants sur les parents.
Les indexes sur les FK sont très pertinentes.
Car si à la question « Qui est le parent de X » la réponse sera toujours rapide (puisque FK = vers PK ou UNIQUE), à la question « Quels sont les enfants de Y » la rapidité de la réponse dépendra des indexes sur la FK.
Désolé mais cette démonstration est entièrement basée sur un exemple trivial.
Vous y avez une relation 1 – 1 et vous en plus d’être posé sur la table enfant, votre filtre (>= 0) renverra toutes les lignes de la table enfants.
Alors un query qui renvoi 100% des enfant, chacun bilatéralement lié à strictement 1 parent ne peut se conclure que par 2 full scan.
Faites un exemple ou chaque parents à un ou plusieurs enfants et posé une condition sur les parents.
Les indexes sur les FK sont très pertinentes.
je te propose de lire également :
1-) Intégrité référentielle – Performance des requêtes
http://blog.developpez.com/zinzineti/p9455/sql-server-2005/integrite-referentielle-performance-des/#more9455
2-) SUPPRESSION DES DONNEES DANS DES TABLES PARENT-ENFANT
http://blog.developpez.com/zinzineti/p9033/sql-server-2000/suppression-des-donnees-dans-des-tables-2/#more9033
3-) ON DELETE CASCADE – ON UPDATE CASCADE
http://blog.developpez.com/zinzineti/p9035/sql-server-2000/on-delete-cascade-on-update-cascade/#more9035
A+
Bonjour;
L’index sur la colonne en FK sert également lorsqu’on veut supprimer dans dbo.T_PARENT, si tu n’as pas d’index et que T_FILLE est très volumineuse la vérification d’intégrité lors du delete risque de prendre du temps. Récemment il a fallu que je supprime des lignes dans une table T_PARENT qui avait 3 filles volumineuses et aucune des filles n’avait d’index sur idp, la première chose que j’ai faite a été de créer les index avant suppression, j’ai fait la suppression, et j’ai supprimé les index après car ils n’avaient aucun interet fonctionnel, et que la suppression dans T_PARENT se produit une fois tous les dix ans.
A+
Soazig