
Vous avez certainement remarquĂ© que les sites marchands sont capables de vous proposer d’acheter d’autres articles en fonction de celui dont vous ĂŞtes en train d’explorer les caractĂ©ristiques, ou dont vous venez de valider l’achat. La plupart du temps, ces articles sont plutĂ´t bien corrĂ©lĂ©s avec l’article achetĂ© ou revu : c’est un exemple de ce que l’on peut faire calculer Ă un algorithme d’exploration de donnĂ©es.
Vous vous en doutez donc : si le Data Mining est un ensemble de fonctionnalitĂ©s qui est rarement abordĂ©, il n’en est pas moins très intĂ©ressant, et a un bel avenir devant lui. Je vous propose donc de dĂ©couvrir très simplement avec SQL Server cette discipline, aussi stimulante techniquement que « dĂ©cisionnellement ». En effet, celle-ci transforme le consommateur de rapports d’un rĂ´le passif / interactif Ă un rĂ´le proactif.
Commençons d’abord par installer la base de donnĂ©es exemple d’entrepĂ´t de donnĂ©es AdventureWorks, que l’on trouve ici pour les versions 2008, 2008 R2 et 2012.
Pour voir comment installer cette base de donnĂ©es sur votre instance SQL Server, c’est par ici.
Dans cette base de données existe une vue dbo.vTargetMail, que nous allons utiliser pour caractériser les clients les plus enclins à acheter un vélo.

Nous créons donc un nouveau projet avec SQL Server Data Tools (le nouveau Business Intelligence Development Studio), et nous choisissons un projet SQL Server Analysis Services and Data Mining :

Une fois le tout validĂ© par OK, la solution s’ouvre et nous devons tout d’abord crĂ©er une source de donnĂ©es :

Un nouveau dialogue s’ouvre alors, et nous devons cliquer sur le bouton New …

Nous mettons un point pour signifier le serveur local, et choisissons la base de donnĂ©es que nous venons d’installer :

Nous devons maintenant dĂ©finir sous quel utilisateur nous allons nous connecter Ă la source de donnĂ©es. Nous choisissons l’utilisateur courant pour des raisons pratiques, mais ce n’est pas ce que l’on ferait pour un environnement de production.

Notons Ă©galement que le compte de service qui exĂ©cute le service SQL Server Analysis Services doit ĂŞtre enregistrĂ© sur l’instance SQL Server (moteur de base de donnĂ©es). Par dĂ©faut, ce compte est NT Service\MSSQLServerOLAPService. Nous devons donc exĂ©cuter le script suivant :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | CREATE LOGIN [NT Service\MSSQLServerOLAPService] FROM WINDOWS USE AdventureWorksDW2012 GO CREATE USER [NT Service\MSSQLServerOLAPService] FOR LOGIN [NT Service\MSSQLServerOLAPService] GO -- SQL Server 2021 et suivants ALTER ROLE db_datareader ADD MEMBER [NT Service\MSSQLServerOLAPService] -- Jusqu'Ă SQL Server 2008 (R2 inclus) EXEC sp_addrolemember 'db_datareader', 'NT Service\MSSQLServerOLAPService' |
Nous pouvons cliquer sur Next, puis sur Finish, et voilĂ notre source de donnĂ©es crĂ©Ă©e. De retour dans l’explorateur de solutions, il nous faut maintenant crĂ©er une vue source de donnĂ©es :

Nous aurions pu crĂ©er la source de donnĂ©es Ă partir du dialogue qui s’affiche :

Comme nous l’avons dĂ©jĂ crĂ©Ă©e, nous nous contentons de cliquer sur Next, et obtenons le dialogue suivant, qui prĂ©sente la liste des tables et vues prĂ©sentes dans la base de donnĂ©es AdventureWorksDW2012 :

Nous ajoutons donc la vue dbo.vTargetMail, et cliquons sur Next, qui nous amène à un dialogue de revue, et nous validons le tout par Finish.
Nous devons maintenant crĂ©er une structure d’exploration de donnĂ©es. De retour dans l’explorateur de solutions, il nous suffit pour ce faire de cliquer-droit sur Mining Structures :

Nous sautons la page d’introduction de l’Assistant d’Exploration de DonnĂ©es en cliquant directement sur Next, ce qui nous amène le dialogue suivant :

Nous continuons avec l’option « A partir d’une base de donnĂ©es relationnelle ou d’un entrepĂ´t de donnĂ©es« , et cliquons sur Next :

Ici nous avons le choix de plusieurs algorithmes, expliquĂ©s succinctement (plus de dĂ©tails dans le livre rĂ©fĂ©rencĂ© en fin d’article):

Nous cliquons sur Next, et obtenons un dialogue de revue et de validation de la vue de donnĂ©es : nous cliquons une nouvelles fois sur Next. Nous devons maintenant spĂ©cifier la liste des vues Ă partir desquelles l’algorithme va calculer les rĂ©ponses possibles. La case Ă cocher Case permet de spĂ©cifier l’entitĂ© que l’on souhaite explorer. En gĂ©nĂ©ral, un cas est reprĂ©sentĂ© par une ligne d’une table ou d’une vue qui stocke ou montre les caractĂ©ristiques de transactions. Nous continuons donc avec la proposition de l’assistant :

Nous devons maintenant choisir suivant quelles caractĂ©ristiques de l’acheteur nous souhaitons que l’algorithme nous aide Ă prĂ©dire quels sont les meilleurs clients potentiels. Comme il s’agit d’acheteurs de vĂ©los, nous choisissons Age, CommuteDistance, HouseOwnerFlag et NumberCarsOwned :
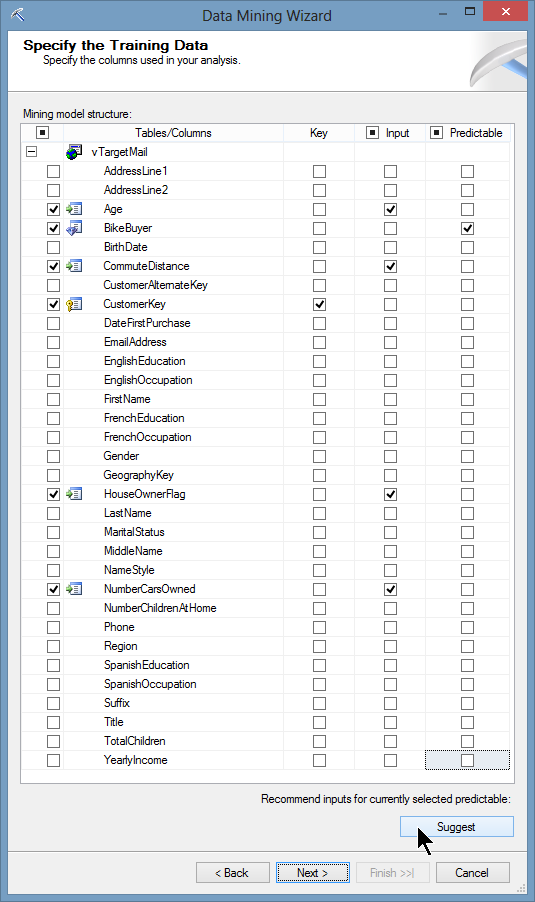
On peut aussi cliquer sur Suggest : le moteur échantillonne alors les données pour faire quelques propositions :

Nous ne modifions pas la matrice, et validons par Next, ce qui amène la fenêtre suivante :
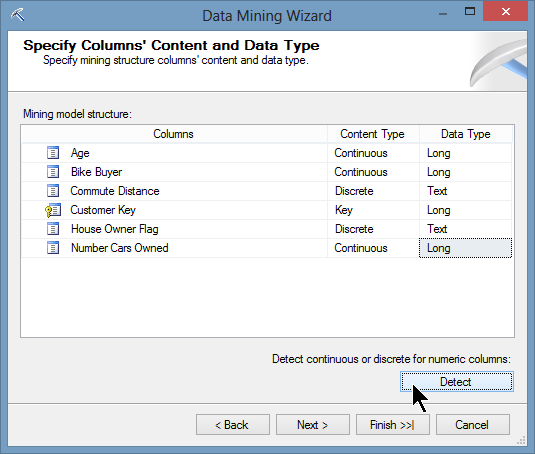
En dernier lieu, il convient de spécifier le type des données : ceci se fait par un simple clic sur Detect.
Après une validation par clic sur Next, nous pouvons enfin choisir le taux d’Ă©chantillonnage : comme 30% des donnĂ©es est un extrait relativement raisonnable, on peut se permettre de ne pas le changer. La lecture de l’explication nous permet de comprendre ce que va faire l’algorithme :

Nous validons le tout par un clic sur Next, ce qui nous permet de revoir notre paramĂ©trage et de renommer la structure et le modèle, mais surtout de cocher la case qui nous permettra d’obtenir les dĂ©tails de l’analyse jusqu’au niveau des transactions exposĂ©es par la vue.

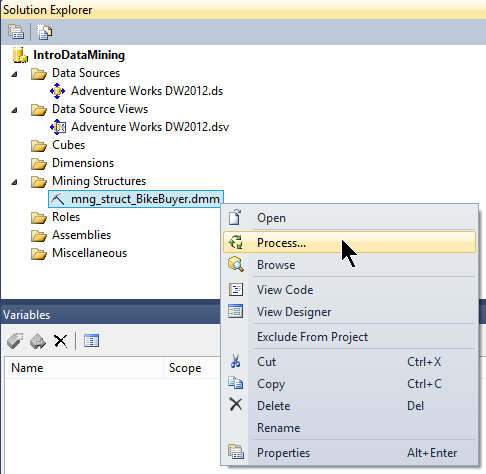
Nous pouvons maintenant valider le tout par Finish, et entraĂ®ner le modèle que nous venons de crĂ©er. Pour ce faire, il nous suffit de choisir l’option Process… du menu contextuel du modèle :
Notons que l’on peut faire la mĂŞme chose sous SQL Server Management Studio, après s’ĂŞtre connectĂ© Ă l’instance SQL Server Analysis Services :
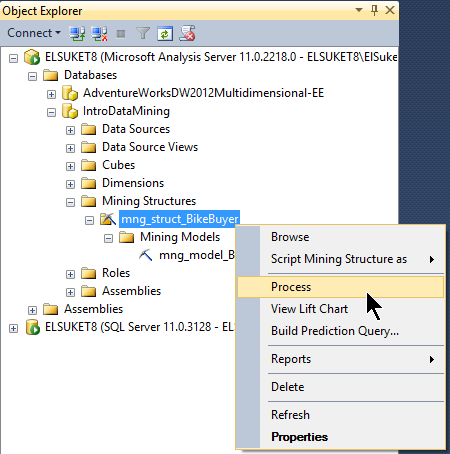
Il nous faut d’abord enregistrer le modèle sur le serveur : jusqu’ici le modèle n’existait que dans SQL Server Data Tools. Nous validons donc par Yes l’avertissement suivant :
Ceci nous amène le dialogue suivant. Pour simplifier, nous continuons avec les options par dĂ©faut, et cliquons sur Run … :
Le modèle est alors en cours d’entraĂ®nement :
Une fois le succès de l’opĂ©ration annoncĂ©, nous fermons les dialogues successivement en cliquant sur Close. Nous basculons alors vers l’onglet Mining Model Viewer, ce qui nous permet de parcourir l’arbre :
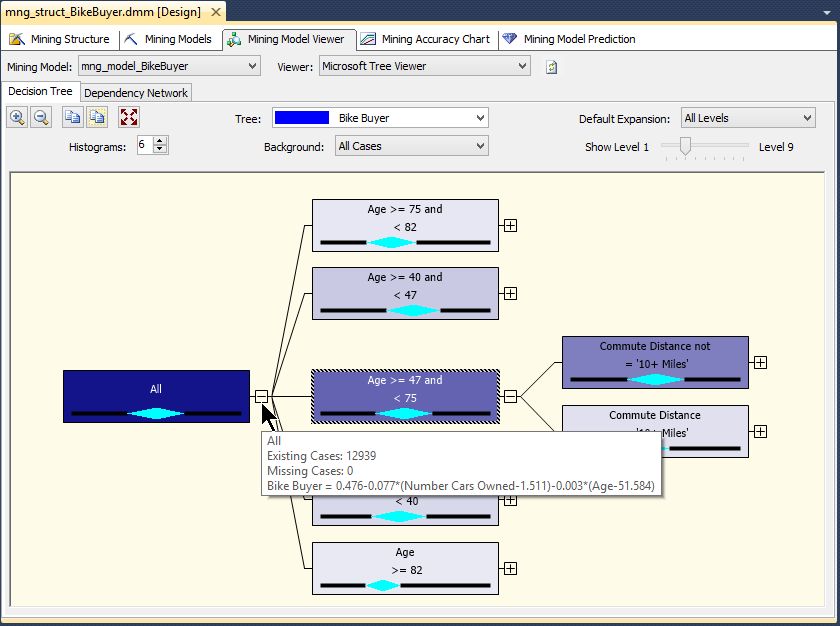
Le gradient de couleurs qui caractĂ©rise chaque nĹ“ud est d’intensitĂ© plus faible Ă mesure que la population sous-jacente diminue.
Voici ce qu’indique la lĂ©gende lorsqu’on clique sur le nĹ“ud Age > 47 and < 75 :
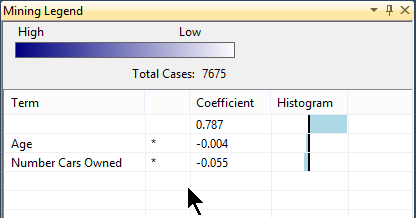
La classe d’âge 48-74 comporte 7675 de nos clients. Les facteurs qui influent le plus l’achat d’un vĂ©lo dans cette classe d’âge sont en premier lieu le nombre de voitures possĂ©dĂ©es, suivi par l’âge. On peut d’ailleurs vĂ©rifier cela en basculant dans l’onglet Dependancy Network :
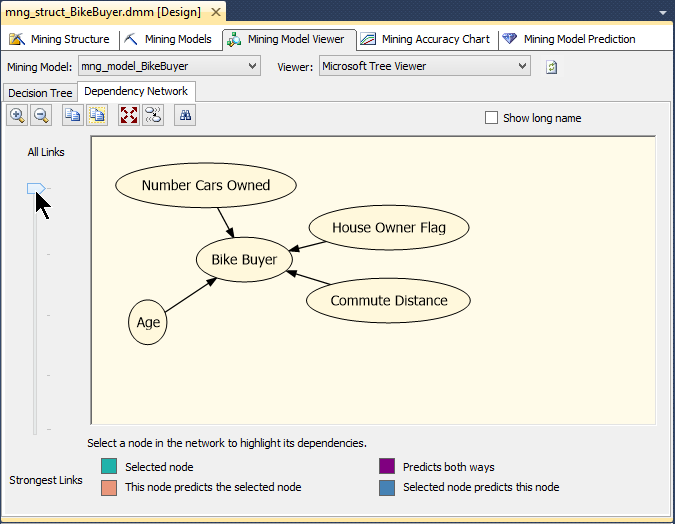
Si l’on dĂ©place le curseur en butĂ©e basse, on voit clairement que le facteur qui influence le plus l’achat d’un vĂ©lo est le nombre de voitures que l’acheteur potentiel possède. Si l’on rapproche le curseur de sa position originale, nous observons que viennent ensuite l’âge, la distance sĂ©parant le domicile du lieu de travail, et enfin la propriĂ©tĂ© d’une maison.
Si vous souhaitez approfondir vos connaissances sur l’Exploration de DonnĂ©es avec SQL Server, voici quelques ressources :
– Le site MarkTab.net, qui pointe vers de nombreux blogs et publie quelques vidĂ©os sur YouTube.
– Le site SQLServerDataMining.com.
– Le livre Data Mining with Microsoft SQL Server 2008 (ISBN: 978-0-470-27774-4, un pavĂ© de 672 pages).