Au niveau algorithmique, la compression de donnĂ©es sans perte (Ă la ZIP, RAR, TAR.GZ, 7Z) n’a plus beaucoup Ă©voluĂ© ces dernières annĂ©es : il s’agit toujours d’un assemblage de dictionnaires, de code de Huffman, de codage arithmĂ©tique, de modèle statistique. Il n’empĂŞche : ces techniques, bien maĂ®trisĂ©es, peuvent toujours s’amĂ©liorer petit Ă petit et donner des outils de compression redoutablement efficaces, comme Google Brotli, arrivĂ© sur le marchĂ© dĂ©but 2016.
Bien maĂ®trisĂ©es, ces techniques peuvent… faire d’Ă©normes progrès ! C’est ainsi que RAD Games a annoncĂ© de nouveaux outils de compression (propriĂ©taires et payants) qui fonctionnent nettement mieux que la concurrence (principalement libre), en fonction du critère de comparaison. Au niveau de l’implĂ©mentation, rien de vraiment neuf, si ce n’est un soin tout particulier apportĂ© par de fins connaisseurs du domaine de la compression, avec et sans pertes.
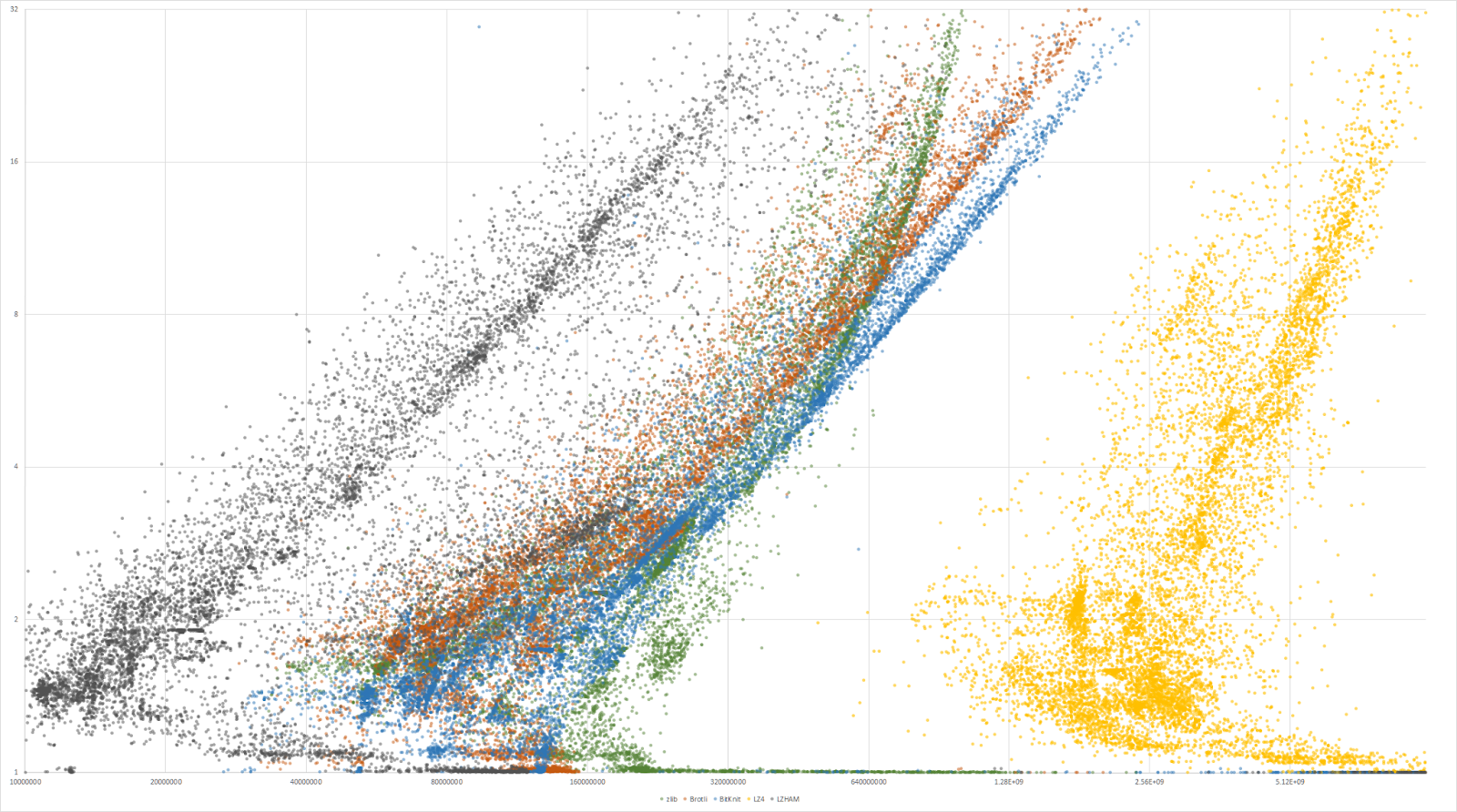
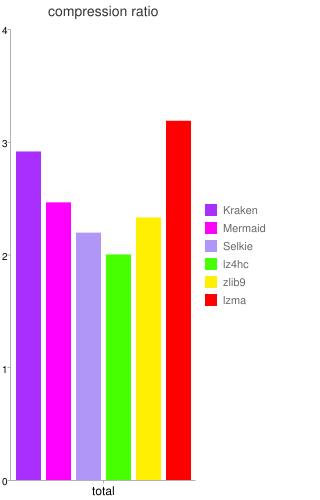
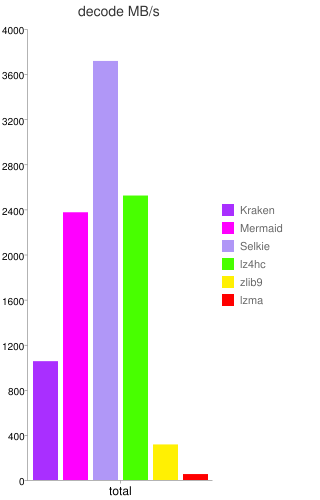
La sociĂ©tĂ© peut maintenant se targuer de proposer un outil de compression dont la principale caractĂ©ristique est une dĂ©compression extrĂŞmement rapide (de trois Ă cinq fois plus que zlib) avec des taux de compression du mĂŞme ordre que LZMA (en Ă©tant dix Ă trente fois plus rapide que ce dernier), nommĂ© Kraken. Il donne aussi du fil Ă retordre Ă LZ4 : ce dernier reste le plus rapide sur tous les types de documents, mais Kraken s’en rapproche fortement tout en gardant une compression nettement meilleure que LZ4.
Deux dĂ©rivĂ©s (disponibles depuis cet Ă©tĂ©) de cet outil sont plus spĂ©cialisĂ©s, en compressant moins mais en dĂ©compressant (beaucoup) plus vite : Mermaid offre une compression moyenne (du mĂŞme ordre que ZIP), tout en Ă©tant extrĂŞmement rapide en dĂ©compression (de sept Ă douze fois plus que zlib, c’est-Ă -dire plus de deux fois plus rapide que Kraken) ; Selkie, au contraire, abandonne encore un peu de compression (entre ZIP et LZ4), pour dĂ©passer LZ4 d’un facteur de presque deux (la dĂ©compression est très proche d’une copie en mĂ©moire, ce qui est un tour de force technique pour une compression non triviale).
Les chiffres du terrain
Les chiffres donnés sont les officiels, reste encore à les confirmer par des extérieurs. Les comparaisons parfaitement équitables sont difficiles à obtenir, puisque les outils de compression ne sont pas si faciles à obtenir.
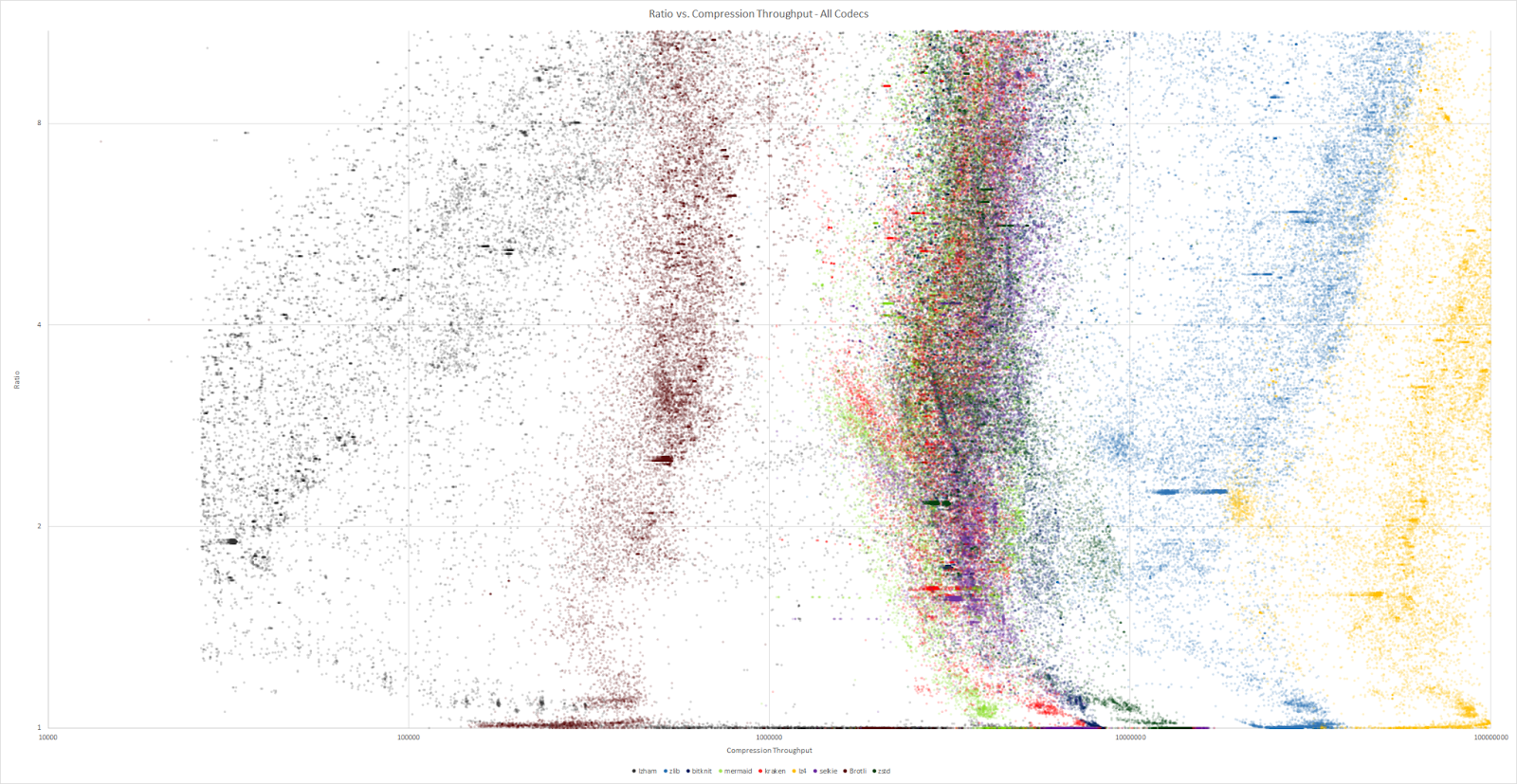
En comparant le ratio de compression avec les dĂ©bits, ces trois outils sont collĂ©s du cĂ´tĂ© des hauts dĂ©bits (mĂŞme si Kraken n’y est que peu prĂ©sent). Zlib occupe une place intermĂ©diaire.
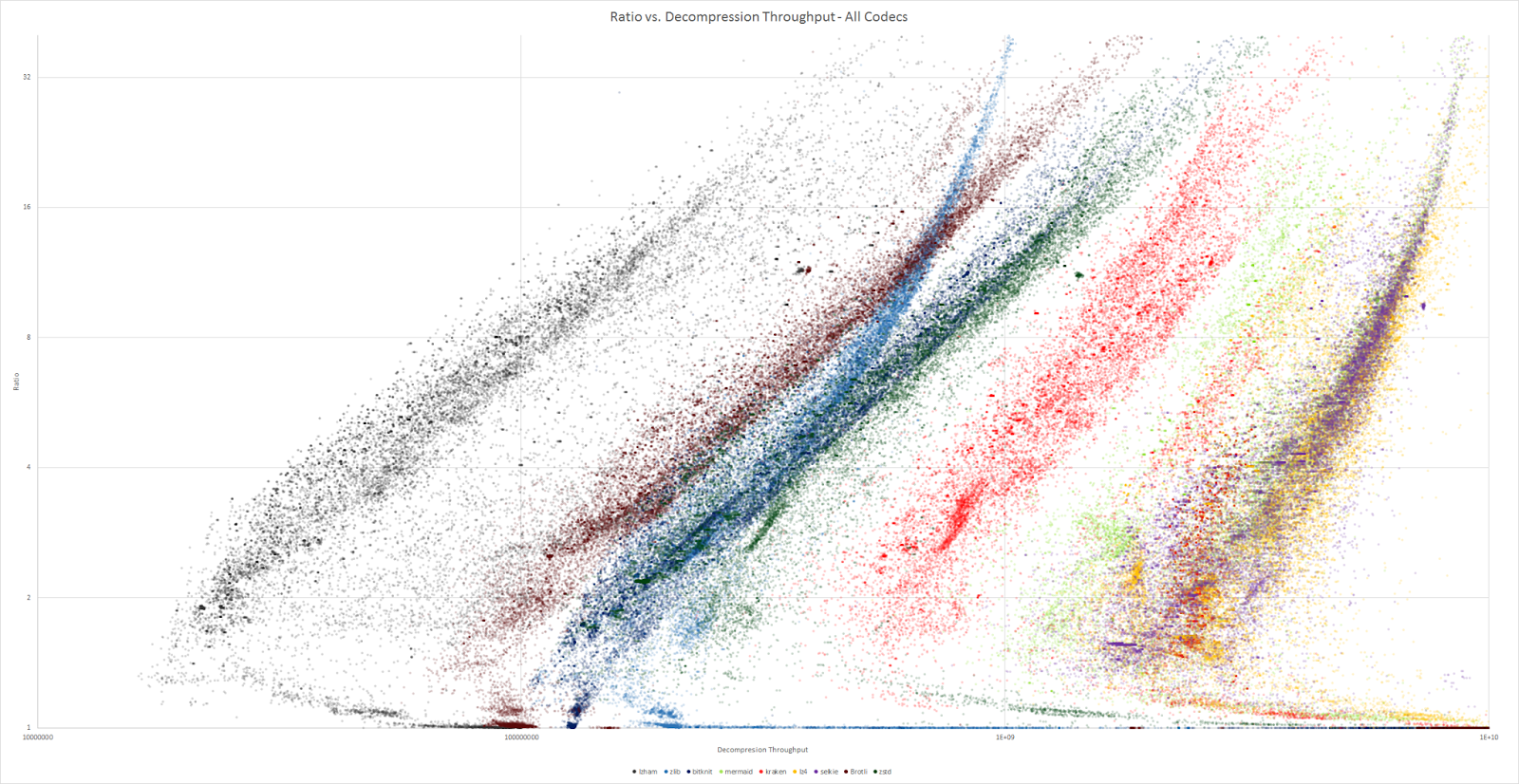
Ces algorithmes sont moins optimisĂ©s en temps pour la compression, il n’empĂŞche qu’ils prĂ©sentent de bons rĂ©sultats. Ils sont nettement plus Ă©loignĂ©s de leurs meilleurs concurrents (comme LZ4… ou zlib).
Du côté algorithmique ?
Ces outils Ă©tant propriĂ©taires, difficile d’aller lire leur code source pour comprendre les amĂ©liorations proposĂ©es. Cependant, certains s’avancent et proposent des pistes qui auraient permis d’atteindre ces nouveaux sommets. Le dĂ©codage très rapide pourrait venir d’une utilisation très judicieuse de la hiĂ©rarchie mĂ©moire des processeurs actuels : autant de donnĂ©es que possible sont stockĂ©es dans les caches du processeur afin de limiter les accès Ă la mĂ©moire vive (qui sont extrĂŞmement lents).
Une tout autre piste suit la thĂ©orie des langages formels, en tentant de construire une grammaire dont le seul mot acceptĂ© est le fichier Ă compresser : les promesses de l’algorithme GLZ sont d’atteindre des taux de compression dignes des algorithmes de prĂ©diction par reconnaissance partielle (la probabilitĂ© de rencontrer un symbole — par exemple, un octet — dĂ©pend d’un certain nombre de symboles dĂ©jĂ lus) tout en gardant la rapiditĂ© des algorithmes de la famille LZ (qui fonctionnent avec des dictionnaires). Les grammaires ainsi gĂ©nĂ©rĂ©es ont pour particularitĂ© d’avoir une entropie faible, c’est-Ă -dire qu’elles se compressent très bien par d’autres algorithmes.
Toutefois, il semblerait que ces pistes n’aient pas Ă©tĂ© suivies pour le dĂ©veloppement de ces algorithmes. Peut-ĂŞtre nourriront-elles la prochaine gĂ©nĂ©ration d’outils de compression ? Cependant, les compromis subsisteront probablement : la rĂ©volution d’un algorithme qui compresse très vite et très bien et qui dĂ©compresse au moins aussi vite n’est pas encore en vue.
Sources : site officiel d’Oodle, nouveautĂ©s d’Oodle 2.3.0 (dont images), Kraken compressor , Grammatical Ziv-Lempel Compression: Achieving PPM-Class Text Compression Ratios With LZ-Class Decompression Speed, RAD’s ground breaking lossless compression product benchmarked (dont images).
Voir aussi : le blog de Charles Bloom, développeur de Kraken, Mermaid et Selkie.