Depuis quelques années, NVIDIA a lancé sa suite de bibliothèques logicielles baptisée GameWorks. Elles sont spécifiquement prévues pour le jeu vidéo et donnent la possibilité aux développeurs d’intégrer aisément des effets, comme la simulation de poils en tout genre avec HairWorks ou encore d’herbe avec Turf Effects. La famille compte aussi GameWorks VR, qui promet d’importants gains en performance pour les jeux exploitant la réalité virtuelle.
NVIDIA met en avant l’optimisation effectuée sur ces implémentations et la facilité d’intégration, ce qui décharge les studios d’une bonne partie du travail… sauf qu’il semblerait que l’optimisation peut se faire au détriment d’AMD. L’exemple de Witcher 3 a montré que HairWorks exploitait un point fort du matériel vendu par NVIDIA, la tesselation — ce qui nuisait fortement à la performance sur les cartes AMD.
Une stratégie : l’ouverture
Justement, AMD prépare sa réponse à GameWorks sous le nom de GPUOpen, en arrêtant de se focaliser sur l’aspect matériel du jeu vidéo. La différence principale par rapport à GameWorks est la licence du code : là où les bibliothèques GameWorks sont disponibles gratuitement après enregistrement, sous une licence propriétaire peu restrictive (les sources sont disponibles sur demande sous licence), AMD envisage de proposer ses bibliothèques GPUOpen comme logiciels libres, sous licence MIT, distribués sur GitHub, dès janvier. Rien n’indique cependant que le développement aura bien lieu sur GitHub et que les contributions seront facilement acceptées (y compris les optimisations pour le matériel autre que celui d’AMD).
Cet élément n’est pas le premier de la stratégie actuelle de AMD. Peu auparavant, ils avaient annoncé une couche de compatibilité avec CUDA, la technologie propriétaire de calcul sur processeur graphique de NVIDIA. AMD a aussi lancé une nouvelle version de leurs pilotes pour carte graphique, dénommée Radeon Software Crimson Edition, qui a apporté un tout nouveau panneau de configuration, bien plus pratique à l’usage que le précédent, ainsi qu’une performance améliorée pour les jeux (bien qu’invisible sous Linux). Globalement, AMD essaye de rattraper son retard par rapport à ses concurrents du côté PC — malgré son omniprésence sur le marché des consoles.

Du contenu pour les jeux…
Dans les bibliothèques disponibles, une bonne partie du contenu sera tout à fait nouveau. Il y aura bien sûr TressFX, sa solution de simulation de cheveux, poils et brins d’herbe, dans la version 3.0. Elle était déjà disponible gratuitement, sources comprises, sur le site d’AMD — un mécanisme moins facile d’accès que GitHub. Également, AMD devrait rendre disponibles en janvier les bibliothèques GeometryFX (opérations géométriques ou simulation physique, selon les sources), ShadowFX pour les ombres et AOFX pour l’occultation ambiante. AMD inclura ses exemples de code, tant pour DirectX 11 et 12 qu’OpenGL.
Les bibliothèques proposées ne devraient pas seulement s’étendre du côté des effets pour des jeux vidéo, avec notamment LiquidVR pour la réalité virtuelle, le moteur de rendu par lancer de rayons FireRender et la bibliothèque de lancer de rayons FireRays, RapidFire pour le déploiement dans le nuage. Pour faciliter le développement, AMD devrait aussi fournir CodeXL pour l’analyse statique de code (y compris pour DirectX 12) et Tootle pour le prétraitement des maillages des modèles 3D à afficher afin d’améliorer la performance au rendu (même si le développement de cet outil a officiellement cessé en 2010).

… mais pas seulement !
GPUOpen ne profitera pas seulement au secteur du jeu vidéo, mais aussi pour le calcul de haute performance, l’initiative Boltzmann étant incluse sous ce nom, avec un nouveau compilateur HCC, un pilote pour Linux spécifiquement optimisé pour le calcul sur GPU ou encore HIP pour la compatibilité avec CUDA.
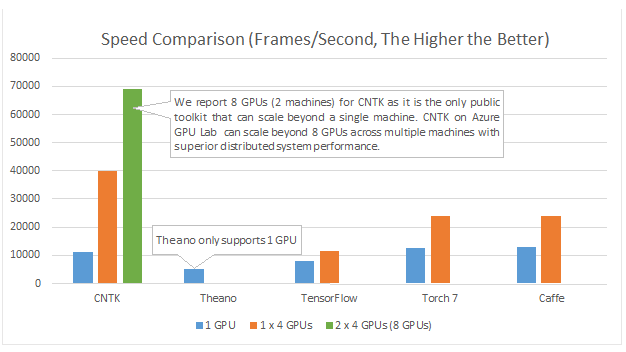
Ils participent aussi au projet Caffe, actif dans le domaine de l’apprentissage profond (technique notamment utilisée avec succès dans la vision par ordinateur), pour lequel ils optimisent une version OpenCL (sans indiquer d’avantage en performance par rapport à cuDNN, l’option de NVIDIA).

Du libre aussi pour Linux
Le dernier point mis en avant par AMD pour ce projet GPUOpen est la mise en place effective de leur architecture de pilote libre pour leurs cartes graphiques. La performance des pilotes actuellement fournis par AMD n’est pas optimale pour tous les types d’utilisation, étant parfois largement dépassés par l’implémentation complètement libre Radeon — les deux étant souvent décrits comme largement en deçà des attentes, notamment pour les machines Steam.
La nouvelle architecture, déjà annoncée l’année dernière, s’articule autour d’une partie libre — AMDGPU —, directement incluse dans le noyau Linux. Cette partie n’aura aucune implémentation des piles graphiques telles que OpenGL ou Vulkan — totalement inutiles dans les applications de calcul pur.
Ensuite, les implémentations libre et propriétaire pourront diverger pour tout ce qui concerne OpenGL, l’accélération du décodage de vidéos, OpenCL et HSA. L’implémentation propriétaire d’OpenCL et de Vulkan devrait être distribuée en libre dans le futur, un mouvement qui n’est pas encore prévu pour OpenGL. Les fonctionnalités spécifiques aux cartes professionnelles FirePro seront, bien évidemment, uniquement propriétaires, même si rien n’empêche l’implémentation libre de les fournir.
Ces suppléments au pilote noyau fonctionneront entièrement en espace utilisateur, ce qui devrait améliorer la sécurité de l’implémentation et diminuer le nombre de changements de contexte utilisateur-noyau.

Sources : présentation d’AMD, Direkte Kontrolle der Radeon-Hardware für Spieleentwickler, AMD Further Embraces Open Source with GPUOpen, for Games and Compute, AMD embraces open source to take on Nvidia’s GameWorks.
Merci à Claude Leloup pour ses corrections.