juillet
2010
 Un article de zinzineti
Un article de zinzineti

Si le serveur rame c’est qu’il y a problème de performance. Lenteur = problème de performances.
Comment identifier la (les) source(s) du lenteur ?
/**************************************************************************
— Description : Diagnostiquer les problèmes de performance
— Auteur : Etienne ZINZINDOHOUE
**************************************************************************/
–> Quel sont les sources du lenteur ?
==============================================================================================
SELECT TOP 20
wait_type AS [Type Attente] -- Nom du type d'attente
,wait_time_ms / 1000 AS [Temps Attente Total (s)] -- Temps d'attente (en seconde)
,waiting_tasks_count AS [Nombre d'attente] -- Nombre d'attentes sur ce type d'attente. Ce compteur est incrémenté au début de chaque attente
,CONVERT(DECIMAL(12,2), wait_time_ms * 100.0 / SUM(wait_time_ms) OVER()) AS [% Temps Attente]
FROM sys.dm_os_wait_stats
ORDER BY [% Temps Attente] DESC;
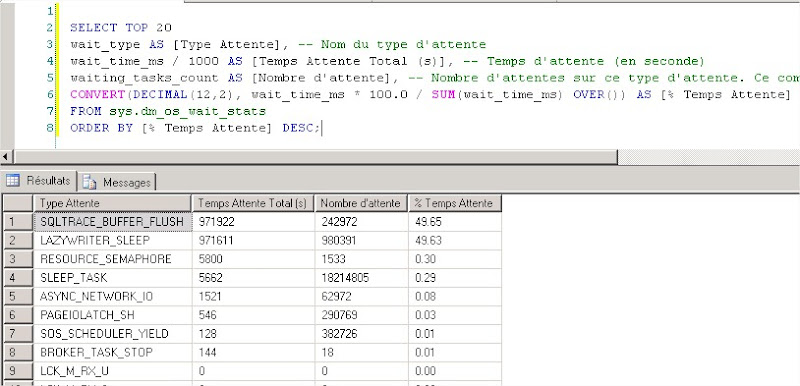
sur mon serveur de test j’ai cet écran :
 |
–> Résultat
==============================================================================================
Les sources de lenteurs observées :
SQLTRACE_BUFFER_FLUSH: Se produit lorsqu’une tâche attend qu’une tâche en arrière-plan vide les tampons de traçage sur le disque toutes les quatre secondes.
LAZYWRITER_SLEEP : Se produit lorsque des tâches d’écriture différée sont suspendues. Il s’agit d’une mesure de la durée consacrée aux tâches en arrière-plan qui attendent. Ne considérez pas cet état lorsque vous cherchez des blocages d’utilisateur.
RESOURCE_SEMAPHORE : Se produit lorsqu’une demande de mémoire de requête ne peut pas être accordée immédiatement en raison d’autres requêtes simultanées. Des temps d’attente élevés peuvent indiquer un trop grand nombre de requêtes simultanées ou des quantités de demande de mémoire trop importantes.
SLEEP_TASK : Se produit lorsqu’une tâche est en état de veille en attendant qu’un événement générique survienne.
ASYNC_NETWORK_IO : Se produit sur des écritures réseau lorsque la tâche est bloquée derrière le réseau. Vérifiez que le client traite les données du serveur.
PAGEIOLATCH_SH : Se produit lorsqu’une tâche attend sur un verrou interne un tampon qui est une demande d’E/S. La demande de verrou interne est en mode partagé. De longues attentes peuvent indiquer l’existence de problèmes au niveau du sous-système de disque.
SOS_SCHEDULER_YIELD : Se produit lorsqu’une tâche abandonne volontairement le planificateur pour d’autres tâches à exécuter. Durant cette attente, la tâche attend le renouvellement de son quantum.
BROKER_TASK_STOP: Se produit lorsque le gestionnaire de tâches de file d’attente Service Broker essaie d’arrêter la tâche. Le contrôle d’état est sérialisé et doit être au préalable dans un état d’exécution.
–> Analyse du résultat
==============================================================================================
Le temps d’attente le plus long concerne le type SQLTRACE_BUFFER_FLUSH, ce qui veut dire qu’il y a problème d’E/S disque, donc de non disponibilité de ressource disque. Ce qui est confirmé par la présence des types PAGEIOLATCH_SH et ASYNC_NETWORK_IO
Or les principales causes d’attente de libération de ressources disques sont généralement des problèmes :
* de mémoire virtuelle (insuffisante,…)
* d’index (fragmentation, absence,…)
* de croissance des fichiers de base de données (tempdb,…)
* des requêtes( INSERT, UPDATE,…) peu performantes
* ou toute autre activité qui cause l’activité du disque dur
Remarques :
1.) Les statistiques ne sont pas conservées lors d’un redémarrage de SQL Server /!\
Les statistiques sont donc perdu au redémarrage des services SQL Server /!\
2.) la Commande DBCC SQLPERF (‘sys.dm_os_wait_stats’, CLEAR); permet de réinitialiser la vue sys.dm_os_wait_stats c-a-d remettre tous les compteurs à Zéro.
–> Quelles sont donc les bases qui lisent et écrivent le plus de pages logiques ?
==============================================================================================
Lecture et écriture de pages logiques puisque il y a d’abord écriture de pages en mémoire avant écriture sur le disque.
SELECT TOP 20
SUM(total_logical_reads + total_logical_writes) AS [Total ES]
,SUM(total_logical_reads + total_logical_writes)/SUM(qs.execution_count) AS [Moyenne ES]
,DB_NAME(qt.dbid) AS [DatabaseName]
FROM sys.dm_exec_query_stats qs
CROSS APPLY sys.dm_exec_sql_text(qs.sql_handle) as qt
GROUP BY DB_NAME(qt.dbid)
ORDER BY [Total ES] DESC;
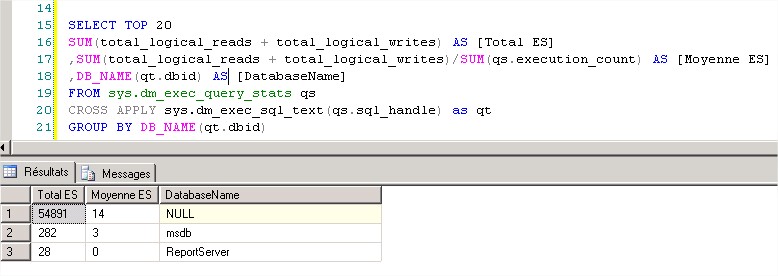
Dans mon environnement de test j’ai cet écran :
 |
–> Analyse du résultat
==============================================================================================
La base de données qui a le plus de Total E/S a pour valeur NULL. cette valeur NULL identifie les instructions SQL ad hoc et préparées. ça veut dire quoi ? Autrement dit cette valeur NULL identifie le niveau d’utilisation de SQL natif, qui peut être lui-même cause potentielle de nombreux problèmes :
* non réutilisation des plans d’éxécution de requête
* non réutilisation de codes
* au niveau sécurité
Ensuite on a les bases msdb et ReportServer dans la liste des résultats.
Allons voir ce qui se passe dans les fichiers de ces base de données ( msdb et ReportServer )à l’aide de la fonction :
fn_virtualfilestats(DB_ID(N'msdb'), x)
avec x l’ID du fichier (data,log,index,…)
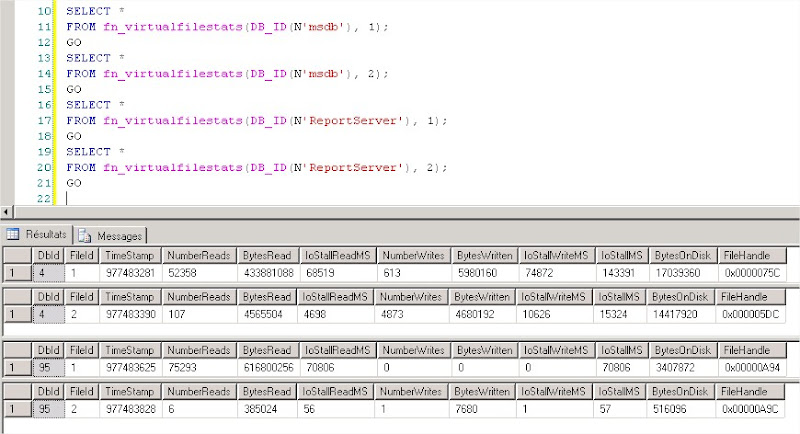 |
on peut noter que l’ID de la base msdb = 4 (noté ID du fichier de données est 1 et le log 2)
et que l’ID de la base ReportServer = 95 (noté ID du fichier de données est 1 et le log 2)
Pour la base msdb :
–> IoStallMS Durée totale (en millisecondes) d’exécution des E/S de lecture et d’écriture sur le fichier de données (ID = 1) est supérieur à 2minutes !
Pour ReportServer
–> IoStallMS Durée totale (en millisecondes) d’exécution des E/S de lecture et d’écriture sur le fichier de données (ID = 1) est supérieur à 1 minute !
Donc dans mon cas, je dois me focaliser sur ce qui se passe sur la base msdb
Un rapide coup d’oeil dans cette base montre qu’elle contient 54 tables utilisateurs et 103 procédures stockées qui servent à faire du reporting !!!
–> Piste vers le diagnostic des problèmes de performances
==============================================================================================
N’oublions pas la question initiale : Pourquoi mon serveur rame ?
La première réponse pour mon cas c’est qu’il y a des problèmes sur la base msdb.
Mais quel est exactement le problème sur cette base ?
Les questions qu’il faut se poser après :
1) Est-ce des problèmes d’index sur la base ?
2) Est-ce des problèmes de requêtes peu performantes ?
On peut utiliser des DMVs pour identifier des requêtes à optimisées
3) Faut-il collecter/analyser des compteurs de performances ?
les outils avancés de diagnostic des problèmes de performances SQL Server
4) ….
Que faut-il retenir ?
==============================================================================================
Diagnostiquer les sources de problèmes de performance est un travail d’expert.
Ce travail demande une bonne maîtrise du fonctionnement de moteur SQL Serveur et surtout une bonne dose de patience.
Alors comment doser patience et urgence (car pour un serveur qui commence à ramer il faut vite trouver une solution pour éviter le pire) ?
D’où l’importance d’une surveillance quotidienne des compteurs de perf des serveurs afin d’être proactif.
Article très complet qui m’a permis de comprendre beaucoup de choses !
Merci beaucoup !