août
2010
 Un article de zinzineti
Un article de zinzineti

Comment forcer le moteur SQL Server à utiliser les index malgré la présence de clause NON SARGeable dans ma requête ?
Démo …
–> Etape 0 : Préparation
=================================================
Mesurer le nombre de pages logiques
J’ai préparé un petit script pour mesurer le nombre de pages logiques lues par ma requête
-- Initialisation <br />
DECLARE @logical_reads_Debut int <br />
SELECT @logical_reads_Debut = logical_reads -- Nombre de lectures logiques effectuées <br />
FROM sys.dm_exec_requests <br />
WHERE session_id = @@spid <br />
<br />
-- Mettre la requête à analyser ici <br />
<br />
-- Obtenir les valeurs des indicateurs <br />
SELECT logical_reads - @logical_reads_Debut AS [Pages logiques lues] <br />
FROM sys.dm_exec_requests <br />
WHERE session_id = @@spid ;
–> Etape 1 : La requête à analyser
=================================================
SELECT SUM(UnitPrice*OrderQty*(1.00-UnitPriceDiscount)) AS Rev, <br />
OrderDate, <br />
ProductID <br />
FROM Sales.SalesOrderDetail AS od JOIN Sales.SalesOrderHeader AS o <br />
ON od.SalesOrderID=o.SalesOrderID <br />
WHERE ProductID Like '%00' <br />
AND OrderDate = CONVERT(datetime,'05/01/2002',101) <br />
GROUP BY OrderDate, ProductID
L’exécution de la requête donne les résultats suivants :
Nombre de pages logiques lues : 1943 avec le plan d’exécution avec 2 index scan
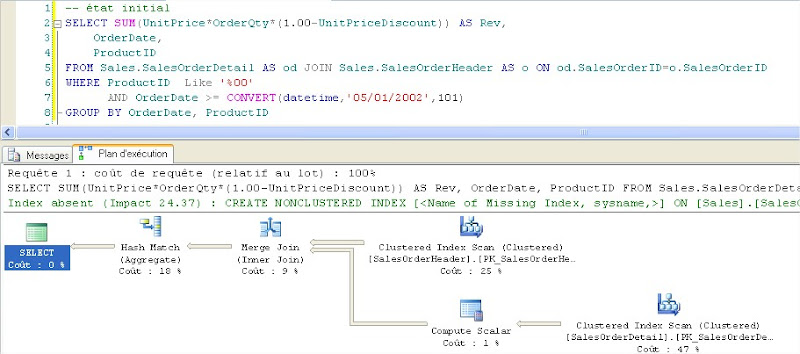 |
Le moteur SQL Server estime que l’implémentation de l’index sur la colonne OrderDate INCLUDE SalesOrderID peut améliorer le coût de requête de 24.37%.
–> Etape 2 : Créons l’index propsé par le moteur SQL
=================================================
GO <br />
CREATE NONCLUSTERED INDEX [IDX_Date_SalesOrderID] <br />
ON [Sales].[SalesOrderHeader] ([OrderDate]) INCLUDE ([SalesOrderID]) <br />
GO
–> Etape 3 : Exécutons à nouveau la requête (la requête de l’Etape 1)
=================================================
Après exécution on obtient :
Nombre de pages logiques lues : 1321
avec le plan d’exécution ci-dessous montrant un index scan et un index seek:
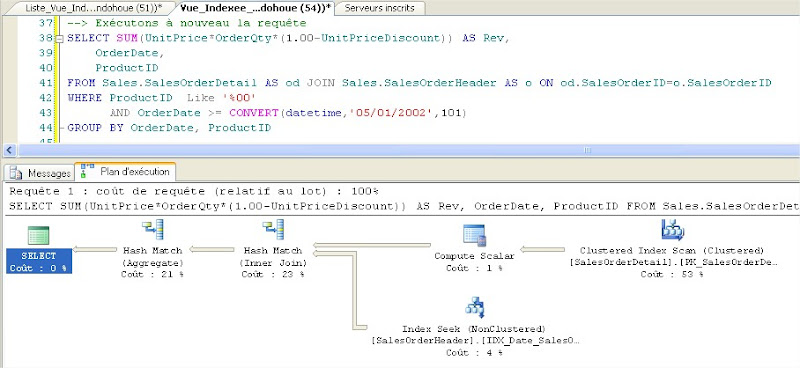 |
On peut penser qu’en créant un index sur la colonne ProductID contenu dans la clause WHERE que la requête serait plus optimisée. Pourquoi ne pas l’essayer ?
–> Etape 4 : Créons un index sur la colonne ProductID
=================================================
GO <br />
CREATE NONCLUSTERED INDEX [IDX_ProductID] <br />
ON [Sales].[SalesOrderDetail]([ProductID])
Exécutons notre requête pour voir le comportement du moteur SQL.
Résultat :Nombre de pages logiques lues : 1297
avec le plan d’exécution ci-dessous montrant un index scan et un index seek
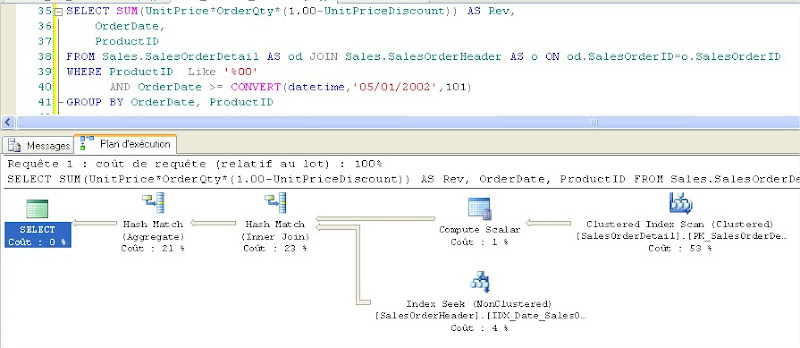 |
Etape 5 : Supprimons les deux index crées pour revenir à l’état initial
=================================================
GO <br />
DROP INDEX [IDX_ProductID]ON [Sales].[SalesOrderDetail] <br />
–>Etape 6 : Créons maintenant une vue indexée
=================================================
La vue indexée à créer tient compte des colonnes OrderDate et ProductID contenu dans la clause WHERE
GO <br />
--Options pour créer une vue indexée <br />
SET NUMERIC_ROUNDABORT OFF; <br />
SET ANSI_PADDING, ANSI_WARNINGS, CONCAT_NULL_YIELDS_NULL, ARITHABORT, <br />
QUOTED_IDENTIFIER, ANSI_NULLS ON; <br />
GO <br />
--Création de la vue avec SCHEMABINDING (pour les vues indexées) <br />
IF OBJECT_ID ('Sales.vOrders', 'view') IS NOT NULL <br />
DROP VIEW Sales.vOrders ; <br />
GO <br />
CREATE VIEW Sales.vOrders <br />
WITH SCHEMABINDING <br />
AS <br />
SELECT SUM(UnitPrice*OrderQty*(1.00-UnitPriceDiscount)) AS Revenue, <br />
OrderDate, <br />
ProductID, <br />
COUNT_BIG(*) AS COUNT <br />
FROM Sales.SalesOrderDetail AS od, Sales.SalesOrderHeader AS o <br />
WHERE od.SalesOrderID = o.SalesOrderID <br />
GROUP BY OrderDate, ProductID; <br />
GO <br />
--Création de l'index sur la vue <br />
CREATE UNIQUE CLUSTERED INDEX IDX_V1 <br />
ON Sales.vOrders (OrderDate, ProductID); <br />
GO
–>Etape 7 : Exécution de la requête après création de la vue indexée
=================================================
Résultats :
Nombre de pages logiques lues : 177
avec le plan d’exécution ci-dessous montrant un index seek
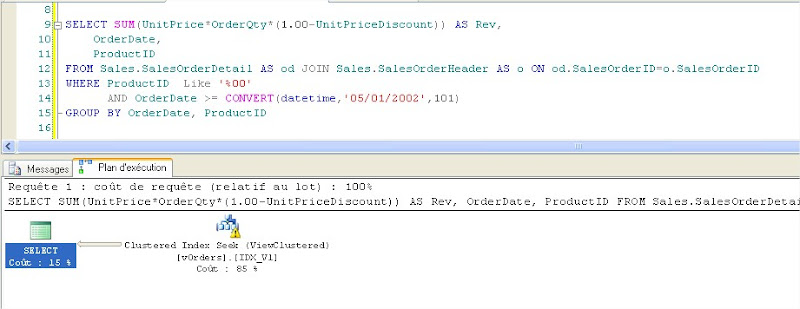 |
Voici le détail de l’index Seek
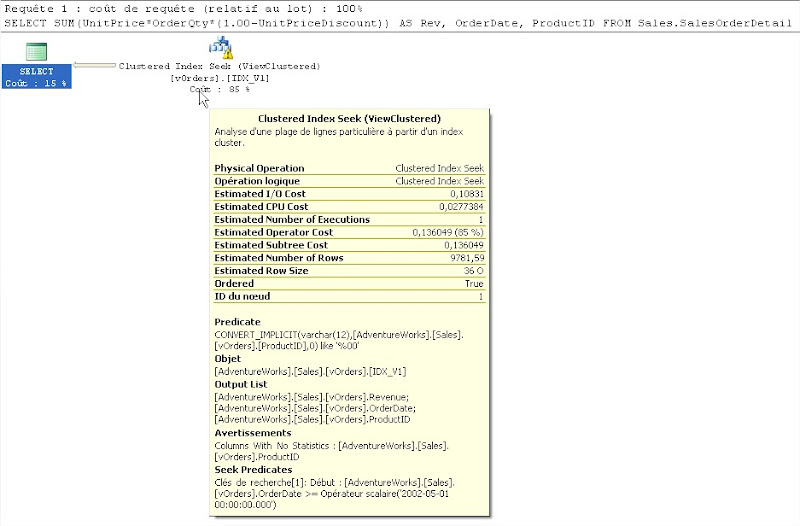 |
Le « Seek Predicates » indique que la clé de recherche est bien la colonne OrderDate
–>Etape 8 : Requête avec uniquement la clause Non SARGable(Like ‘%00′)
=================================================
ProductID <br />
FROM Sales.SalesOrderDetail AS od JOIN Sales.SalesOrderHeader AS o ON od.SalesOrderID=o.SalesOrderID <br />
WHERE ProductID Like '00%' <br />
GROUP BY ProductID
Résultats :
Nombre de pages logiques lues : 1240
avec le plan d’exécution ci-dessous montrant un Index Scan
L’index de la vue n’est pas utilisé
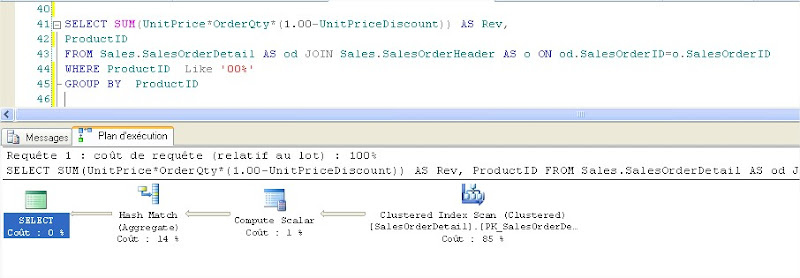 |
Conclusion
======================
Bien que ma requête contienne une clause WHERE NON SARGeable (Like ‘%00′) le moteur SQL Server à quand même utilisé l’index composite de la vue en se basant sur la colonne OrderDate dont la clause dans le WHERE est bien SARGable. Alors faut-il donc conclure que la présence de prédicats non SARGable n’empêche pas le moteur SQL d’utiliser les index des clauses SARGable ?
———————————————————
— Auteur : Etienne ZINZINDOHOUE
———————————————————
Merci SQLPro pour les remarques. Il est vrai que SET STATISTICS IO ON/OFF est moins complexe à gérer, mais ce qui me gène c’est le flot d’informations renvoyées par la commande. Personnellement je trouve qu’on perd plus de temps à chercher la valeur de deux indicateurs (« temps cpu » et le « nombre de pages lues »)dans l’onglet Messages (si on travaille sous SSMS).
Voici un exemple concret.
Soit la requête suivante
USE AdventureWorks
SELECT
det.ProductID,
YEAR(hdr.OrderDate)AS [Annee],
det.LineTotal
FROM Sales.SalesOrderDetail det
JOIN Sales.SalesOrderHeader hdr
ON det.SalesOrderID = hdr.SalesOrderID
Avec la commande SET STATTISTICS IO ON :
il faut aller dans l’onglet Messages
et on a les informations ci-dessous :
(121317 row(s) affected)
Table ‘SalesOrderDetail’. Nombre d’analyses 1, lectures logiques 1238, lectures physiques 0, lectures anticipées 0, lectures logiques de données d’objets volumineux 0, lectures physiques de données d’objets volumineux 0, lectures anticipées de données d’objets volumineux 0.
Table ‘SalesOrderHeader’. Nombre d’analyses 1, lectures logiques 703, lectures physiques 0, lectures anticipées 0, lectures logiques de données d’objets volumineux 0, lectures physiques de données d’objets volumineux 0, lectures anticipées de données d’objets volumineux 0.
On voit bien ce qui se passe au niveau de chaque table(ce qui est bien), mais ce qui m’intéresse c’est juste le temps CPU et nombre de pages logiques lues pour la requête !
Alors que ma commande affichage exclusivement le « temps CPU » et le « Nombre de page logiques » pour la requête. et je n’ai plus besoin d’aller faire de la fouille dans l’onglet Messages de SSMS pour voir « temps CPU » et le « Nombre de page logiques « . ce qui me fait gagner du temps dans ce cas précis.
Bref je pense que SET STATISTICS IO ON est trop bavard et me fait perdre du temps lorsque je veux juste voir la valeur de deux indicateurs de performances.
Par ailleurs, j’ai lu ton l’indexation et j’avoue que ça m’a beaucoup éclairé Thanks
Thanks
« la sur normalisation », tu as un papier sur le sujet ? ça m’interesse.
En tout cas merci beaucoup
A+
Plutôt que d’utiliser une requête pour connaître le nombre de pages lues, préférez utiliser l’option de session STATISTICS IO (SET STATISTICS IO ON puis OFF) ceci est plus détaillé et moins complexe à gérer.
Enfin, l’exemple que vous donnez est assez similaire à celui que je traite dans ce papier :
http://sqlpro.developpez.com/optimisation/indexation/
Mais il existe d’autres possibilité d’optimisation pour réduire le nombre de pages lues, comme la sur normalisation (inutile dans le cas que vous présentez).
A +