La premi├©re pr├®version publique de CUDA 7.5 est disponible pour tous les d├®veloppeurs CUDA enregistr├®s aupr├©s de NVIDIA. La principale nouveaut├® est la gestion des nombres ├Ā virgule flottante cod├®s sur seize bits, c’est-├Ā-dire la moiti├® de l’encodage traditionnel (float sur trente-deux bits). Cette format est principalement utilis├®e pour du stockage de donn├®es quand la pr├®cision requise n’est pas tr├©s importante, mais aussi pour des calculs sous la m├¬me hypoth├©se.
Calculs sur seize bits
L’effet sur la performance du code peut ├¬tre ├®norme : la bande passante requise est divis├®e par deux, ce qui permet de transmettre deux fois plus de nombres par unit├® de temps sur les bus existants, d’en stocker deux fois plus sur la m├¬me quantit├® de m├®moire. Ils pourront donc se r├®v├®ler tr├©s utiles pour les applications o├╣ ces ├®l├®ments sont limitatifs, comme l’apprentissage de r├®seaux neuronaux de grande taille ou le filtrage de signaux en temps r├®el.
L’avantage en temps de calcul n’est disponible que sur les GPU ayant une partie pr├®vue pour l’arithm├®tique sur seize bits, ce qui n’est pas le cas pour la majorit├® des processeurs disponibles, sauf sur Tegra. La prochaine architecture de GPU de NVIDIA, connue sous le nom de Pascal, aura des transistors allou├®s pour les calculs sur seize bits : le nombre de calculs effectu├®s par seconde doublera entre les pr├®cisions FP16 et FP32 (le m├¬me rapport qu’entre FP32 et FP64). Entre temps, les calculs seront effectu├®s en interne sur les m├¬mes circuits que pr├®c├®demment, avec une pr├®cision bien plus ├®lev├®e que des circuits d├®di├®s (bien qu’elle soit en grande partie perdue lors de l’arrondi vers les seize bits).
R├®seaux neuronaux
L’un des chevaux de bataille actuels de NVIDIA est l’apprentissage automatique, en particulier par r├®seaux neuronaux, plus sp├®cifiquement profonds, par exemple pour une utilisation dans les voitures intelligentes. Ils ont par exemple d├®velopp├® la biblioth├©que cuDNN (CUDA deep neural network), qui acc├®l├©re les calculs par un GPU. La troisi├©me version de cette biblioth├©que a ├®t├® optimis├®e, particuli├©rement au niveau des convolutions (FFT et 2D), ce qui am├®liore la performance lors de l’entra├«nement de r├®seaux neuronaux (gain d’un facteur deux pour l’apprentissage sur des GPU Maxwell). Elle g├©re ├®galement les nombres en virgule flottante sur seize bits, ce qui est utile pour des r├®seaux tr├©s grands, mais n’am├®liore pas (encore) les temps de calcul.

NVIDIA a aussi d├®velopp├® l’outil DIGITS, un logiciel de bien plus haut niveau que cuDNN pour les m├¬mes r├®seaux neuronaux, pr├®vu pour des profils plus scientifiques que pour des programmeurs. L’une des nouveaut├®s est l’apprentissage distribu├® sur plusieurs GPU : ajouter un deuxi├©me GPU aide ├Ā r├®duire fortement les temps de calcul (d’un facteur l├®g├©rement inf├®rieur ├Ā deux), nettement moins impressionnant en ajoutant deux autres (facteur de deux et demi). Le gain sera probablement plus important avec les prochaines architectures de GPU, Pascal devant utiliser la technologie NVLink au lieu du bus PCI Express (partag├®) pour la communication entre cartes.
Alg├©bre lin├®aire creuse
CUDA vient ├®galement avec la biblioth├©que cuSPARSE pour l’alg├©bre lin├®aire sur des matrices creuses acc├®l├®r├®e sur GPU. Une nouvelle op├®ration vient d’y ├¬tre ajout├®e, nomm├®e GEMVI, utilis├®e pour la multiplication entre une matrice pleine et un vecteur creux ŌĆö la sortie ├®tant ├®videmment un vecteur plein. Ce genre d’op├®rations est tr├©s utile pour l’apprentissage automatique, plus particuli├©rement dans le cas du traitement des langues. En effet, dans ce cas, un document r├®dig├® dans une langue quelconque (fran├¦ais, anglais, allemandŌĆ”) peut ├¬tre repr├®sent├® comme un comptage des occurrences de mots d’un dictionnaire ; bien ├®videmment, tous les mots du dictionnaire (m├¬me partiel) ne sont pas pr├®sents dans le texte, sa repr├®sentation vectorielle contient donc un grand nombre de z├®ros, il est donc creux. Une fois le dictionnaire d├®fini, pour am├®liorer l’efficacit├® des traitements, le dictionnaire peut ├¬tre r├®duit en taille pour n’en garder qu’un sous-espace vectoriel qui pr├®serve la s├®mantique des textes : la transformation de la repr├®sentation du texte demande justement un produit entre le vecteur creux initial et une matrice de transformation.
C++11 et fonctions anonymes
La version pr├®c├®dente de CUDA a commenc├® ├Ā comprendre C++11, la derni├©re it├®ration du langage de programmation. Les fonctions anonymes (lambdas) en font partie et servent notamment ├Ā ├®crire du code plus concis. CUDA 7.0 ne les tol├®rait que dans le code ex├®cut├® c├┤t├® client, pas encore sur le GPU : ce point est corrig├®, mais seulement comme fonctionnalit├® exp├®rimentale. Par exemple, un code comptant les fr├®quences de quatre lettres dans une cha├«ne de caract├©res pourra s’├®crire comme ceci :
void xyzw_frequency_thrust_device(int *count, char *text, int n) {
using namespace thrust;
*count = count_if(device, text, text+n, [] __device__ (char c) {
for (const auto x : { 'x','y','z','w' })
if (c == x) return true;
return false;
});
}
La m├¬me fonctionnalit├® permet d’├®crire des boucles for pour une ex├®cution en parall├©le, avec une syntaxe similaire ├Ā OpenMP, par exemple une somme de deux vecteurs (SAXPY pour BLAS) :
void saxpy(float *x, float *y, float a, int N) {
using namespace thrust;
auto r = counting_iterator(0);
for_each(device, r, r+N, [=] __device__ (int i) {
y[i] = a * x[i] + y[i];
});
}
Profilage
La derni├©re nouveaut├® annonc├®e concerne le profilage de code, n├®cessaire pour d├®terminer les endroits o├╣ les efforts d’am├®lioration de la performance doivent ├¬tre investis en priorit├®. CUDA 7.5 am├®liore les outils NVIDIA Visual Profiler et NSight Eclipse Edition en proposant un profilage au niveau de l’instruction PTX (uniquement sur les GPU Maxwell GM200 et plus r├®cents), pour d├®termines les lignes pr├®cises dans le code qui causent un ralentissement. Pr├®c├®demment, le profilage ne pouvait se faire qu’au niveau d’un noyau, ├®quivalent d’une fonction pour la programmation sur GPU (temps pris par le noyau ├Ā l’ex├®cution, importance relative par rapport ├Ā l’ex├®cution compl├©te).
CUDA 6 avait d├®j├Ā am├®lior├® la situation en affichant une corr├®lation entre les lignes de code et le nombre d’instructions correspondantes. Cependant, un grand nombre d’instructions n’indique pas forc├®ment que le noyau correspondant prendra beaucoup de temps ├Ā l’ex├®cution. Pour remonter jusqu’├Ā la source du probl├©me, ces informations sont certes utiles, mais pas suffisantes, ├Ā moins d’avoir une grande exp├®rience. Gr├óce ├Ā CUDA 7.5, le profilage se fait de mani├©re beaucoup plus traditionnelle, avec un ├®chantillonnage de l’ex├®cution du programme, pour trouver les lignes qui prennent le plus de temps.
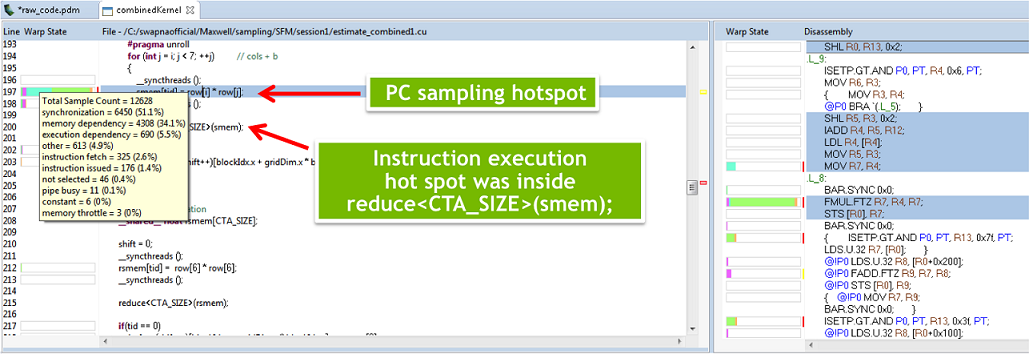
Sources et cr├®dit des images : New Features in CUDA 7.5, NVIDIA @ ICML 2015: CUDA 7.5, cuDNN 3, & DIGITS 2 Announced.