décembre
2008
 Un article de Bruno Orsier
Un article de Bruno Orsier

Jeudi dernier nous avons tenu notre deuxième dojo, cette fois sur une journée complète. Dans la matinée nous avons travaillé sur des thèmes assez généraux, susceptibles d’intéresser le plus grand nombre, c’est-à-dire développeurs + utilisateurs embarqués. Le matin j’ai donc proposé 2 brainstormings, une vidéo, et une discussion sur un article d’Emmanuel Chenu. L’après-midi a été passé sur le challenge de programmation (le simulateur de fourmis) dont j’ai parlé dans un précédent billet.
Ce billet est un compte-rendu de toutes ces activités.
Brainstorming
Brainstorming sur le thème : « Comment architecturer les projets de développement, le plus tôt possible, pour qu’ils offrent toujours un maximum de possibilités de test (à tous les niveaux) »
Ce thème a été proposé par l’une des équipes, car ils ont mis du temps à découvrir qu’ils pouvaient simplifier grandement certains de leurs tests en remplaçant notre moteur d’impression par une doublure facile à réaliser (un mock / simulacre-). Pour leur projet les tests d’impression sont devenus très simples : il s’agit juste de vérifier que la doublure a bien été appelée – inutile en effet aller jusqu’au bout de la véritable impression puisque que notre moteur d’impression (utilisé dans d’autres applications) est considéré comme très fiable. Cette équipe vient donc d’identifier et résoudre un type de gaspillage : retester continuellement (dans chaque sprint – ils développent un produit toujours livrable) quelque chose qui est déjà au point ! C’est un gaspillage de type processus superflus, étapes inutiles (voir ce billet sur QualityStreet pour plus de détails sur les gaspillages).
Durant le brainstorming, plusieurs recommandations pour de futurs projets sont apparues :
- favoriser toutes les formes de découplage, afin de permettre l’utilisation de doublures de tests
- avoir un projet de test différent pour chaque niveau de (unitaires, intégration, fonctionnels, afin de pouvoir les exécuter sur différentes machines si besoin, et surtout pouvoir les exécuter chacun à son rythme propre (sur un projet où tests d’intégrations longs et tests unitaires rapides étaient liés dans un même projet, l’habitude d’exécuter tout le temps les tests unitaires s’est vite perdue).
- dès le départ du projet, utiliser un framework de tests automatisés, et si possible un outil existant, comme FitNesse ou GreenPepper, au lieu de développer un framework interne au long du projet.
- permettre le pilotage de l’application par un outil externe (par exemple par le framework de tests) – en gros le code derrière les éléments de la GUI devrait pouvoir être appelé par un outil externe, de telle sorte que le test manuel puisse se résumer à vérifier que la fonctionnalité est activée, au lieu de vérifier le comportement de la fonctionnalité.
- mettre en place un outil de mesure de couverture de tests dès le début du projet.
Ce sont des idées que l’on peut trouver ailleurs bien sûr, mais ce qui est très positif c’est qu’ici elles viennent des équipes elles-mêmes. Ainsi il y a beaucoup plus de chances pour que ces idées soient adoptées.
Vidéo
Vidéo en anglais (5 minutes) “Why does Agile Software Development pay?” http://www.youtube.com/watch?v=OWvSnYjqOTQ
Cette vidéo décrit en détail le schéma ci-dessous, schéma qui vise à expliquer pourquoi un développement agile (avec livraisons rapides et fréquentes) serait plus rentable qu’un développement non-agile (avec peu de livraisons très espacées).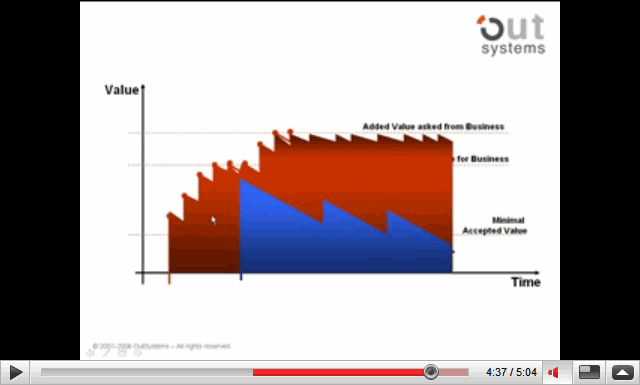
L’hypothèse centrale derrière ce raisonnement est qu’un logiciel livré se déprécie aussitôt, tout comme une voiture quand on l’achète… C’est un point sans doute peu intuitif (un logiciel ne s’use pas), mais qui me paraît vraiment digne d’intérêt, car en effet l’environnement dans lequel le logiciel est utilisé change constamment (nouveaux besoins utilisateurs, autres logiciels concurrents, nouvelles versions de systèmes d’exploitation, etc.).
Si vous acceptez cette idée de dépréciation d’un logiciel, alors le raisonnement exposé dans cette vidéo semble tenir la route. En tout cas je vous invite à la visionner, et à poster vos commentaires.
Ces idées ont paru raisonables aux participants du dojo, et pour nous la conclusion est qu’il faudrait sensibiliser nos directeurs de produits (product owners) au grand intérêt de sortir un logiciel rapidement, quitte à ce qu’il ne contienne pas toutes les fonctionnalités souhaitées (je connais leur réponse d’avance, à savoir que c’est impossible dans nos marchés, mais est-ce un fait ou bien une hypothèse qui pourrait être remise en cause ?).
Un sujet de débat dans les équipes a été le fait de faire démarrer la valeur du développement agile aussi haut sur le graphique (le premier point rouge) : est-ce qu’on peut fournir autant de valeur aussi tôt ? Même si n’est pas le cas, cela n’annule pas le raisonnement de toute manière (la surface rouge restera supérieure à la bleue).
Pratiques d’équipe
Afin de progresser sur le thème de l’auto-organisation des équipes, j’ai ensuite proposé une discussion sur l’article d’Emmanuel Chenu « Pratiques d’équipe – 6ème édition » http://emmanuelchenu.blogspot.com/2008/11/pratiques-dequipe-6eme-edition.html. Ce document décrit l’organisation vers laquelle une équipe de développeurs a convergé pour s’améliorer. Les participants avaient lu le document à l’avance, car il fait tout de même 28 pages. Voici les remarques des participants au dojo :
- globalement nous sommes assez proches de ce que font Emmanuel et ses collègues,
- leur concept de « war room » est intéressant, ce serait bien pour nous aussi (actuellement nous devons aller dans une autre salle pour certaines réunions, comme les démarrages de sprint, mais nos documents et les infos visuelles restées dans le bureau nous manquent alors)
- ils vont plus loin que nous dans le pair-programming, sans être intransigeants sur la question, puisque le pair-programming n’est pas systématique pour toutes les tâches. Dans les améliorations possibles, nous ne permutons pas systématiquement les deux personnes durant la session, et nous n’avons pas trop défini le rôle de chacun d’elles.
- problème pour nous, certains membres de l’équipe ne sont qu’à 50% sur le projet.
- leurs « mêlées quotidiennes » (daily meetings) semblent mieux menées que les nôtres (nous ne sommes pas assez rigoureux sur la durée ni le contenu)
- ils n’utilisent apparemment pas de logiciel de gestion de projet, alors que nous utilisons VersionOne. VersionOne nous est nécessaire pour pouvoir assurer une certaine traçabilité (et tenir au courant un product owner situé aux USA par exemple). J’ai souligné que dans le cas de Emanuel et al., la traçabilité paraît obtenue par la production de documents spécifiques (qui font donc partie des livrables) – ce que nous cherchons à éviter en utilisant un logiciel de gestion de projet adapté à Scrum. Mais cela nous prive sans doute des bénéfices des supports visuels qui apparaissent en l’absence de tel logiciel (en fait l’une de nos équipes utilise de plus en plus un support papier affiché au mur du bureau, et met à jour VersionOne en plus)
- dans les supports visuels mentionnés par Emmanuel, nous pourrions peut-être adopter la boîte à idées, le « blocking board », et le niko-niko.
- l’idée de faire vivre les métriques en les notant sur un post-it géant pourrait aussi être adoptée, et nous sommes d’accord sur le fait qu’il y a un vrai risque de négliger les métriques affichées sur un site web.
- l’utilité du Gizmo (la peluche qui indique quel poste est en cours de synchronisation avec la base de code commune) ne nous a pas paru évidente, mais cela est sans doute dû au petit nombre de développeurs dans nos équipes (en tout cas dans celles du dojo).
- ils arrivent à intégrer une nouvelle personne par mois. Nous nous sommes demandé s’il s’agissait de débutants ou de personnes expérimentées. Leur idée de main-courante pour tracer les décisions de conception importantes paraît intéressante.
- ils minutent beaucoup ce qu’ils font – cela a suscité un débat, certains de nos participants trouvant cela un peu stressant !
- le document ne s’étend pas trop sur la question des objectifs individuels versus objectifs d’équipe, c’est dommage car c’est l’un de nos problèmes d’organisation.
Ce document a été très apprécié, et la discussion qu’il a générée a été très stimulante. Nous verrons plus tard si cela se traduit en actions concrètes (décider d’actions n’est pas le but du dojo, il y a déjà les rétrospectives pour cela).
Brainstorming
Brainstorming : Comment intégrer un nouvel employé dans une équipe Scrum – avec la contrainte qu’il faut l’évaluer pour décider si on le garde à la fin de la période d’essai.
Plusieurs idées ont été discutées :
- demander à des personnes extérieures à l’équipe d’aider à cette intégration, afin que l’équipe ne soit pas ralentie. Par exemple certaines activités devraient être faites par le chef d’équipe : formation TDD, TP divers, formations internes obligatoires…
- idée de TP : lui faire faire des tests a posteriori sur un projet qui en manque, afin d’améliorer notre couverture de test, et de faire comprendre que c’est ce qu’il faut éviter de faire !
- l’équipe peut facilement et à faible coût faire comprendre Scrum et ses divers mécanismes, tout simplement en embarquant le nouveau dans toutes les réunions
- l’équipe travaillera avec le nouveau en pair-programming
- l’équipe pourra déménager dans un nouveau bureau qui pourra être aménagé en « war-room » avec des supports visuels au mur pour faciliter la compréhension du projet par le nouveau, comme recommandé dans l’article ci-dessus.
- l’équipe devra être capable de prendre la décision de garder le nouveau non seulement sur les aspects techniques, mais sur des aspects « sociaux » : est-ce que sa manière de discuter, d’argumenter, de s’impliquer ou non dans un démarrage (par exemple) conviendront à l’équipe sur le moyen terme ?
Randori
Le randori s’est bien passé, même si nous n’avons pas beaucoup avancé. Nous avons mis en place un projet de tests unitaires, et attaqué une première histoire d’utilisateur : « en tant qu’utilisateur du simulateur, je voudrais qu’en l’absence de nourriture les fourmis se déplacent de manière aléatoire ».
Nous avons respecté le principe du randori, à savoir permutation toutes les 5 minutes, et le rythme a été assez bien tenu.
La séance a permis de réviser le TDD en général, le principe DRY (Do not Repeat Yourself) en particulier, et de faire partager à tout le monde certains principes de programmation connus seulement de certains (par exemple en Delphi, et en Pascal, on peut déclarer des tableaux indexés par un type énuméré, ce qui permet d’éviter certaines erreurs de programmation, et de réduire la complexité cyclomatique en supprimant les instructions de type case).
Par contre nous avons un peu galéré sur le principe des tests unitaires portant sur le caractère aléatoire de l’histoire utilisateur. D’après cet article sur wikipedia que j’ai trouvé après le dojo :
« Cependant, il faut retenir qu’un générateur peut toujours réussir n tests et échouer au n + 1ieme. De plus aucun générateur ne peut réussir tous les tests que l’on pense constitutif du hasard, car il n’existe aucune suite qui possède toutes les propriétés dont la probabilité est de 100%. »
il n’y a peut-être pas de moyen pour faire en sorte que nos tests unitaires soient complètement fiables. Bref tout cela nous a un peu perturbés et ralentis car nous ne sommes pas très familiers de ce genre de questions (nous ne travaillons jamais avec des nombres aléatoires dans nos applications). En préparant plus le randori, j’aurais peut-être pu éviter un certain enlisement dans sa deuxième moitié !
Néanmoins le principe du randori a été validé et a donné à tout le monde l’envie de continuer.
Note : vous pouvez être intéressés par ce compte-rendu d’une session de randori à Devoxx 2008 par Dave Nicolette.
Discussion à chaud
D’après la rétrospective du premier dojo (faite via un site web permettant des enquêtes anonymes) il avait manqué une discussion à chaud à la fin de la séance. Nous en avons donc fait une, en 15 minutes. Voici les points discutés :
- ce dojo change du train-train habituel
- le randori permet de tendre vers du code parfait
- les solutions sont plus élégantes car on est plus nombreux
- on n’est pas contraints par le temps, on peut rechercher la meilleure solution
- c’était intéressant le matin de d’avoir une réflexion plus générale, non technique, de plus haut niveau sur d’autres aspects de notre métier
- on apprend mieux par la pratique que par un cours magistral
- c’était bien de se focaliser sur les problématiques de tests
- l’utilisateur embarqué présent dans le randori ne s’est pas ennuyé.
Donc une impression générale assez positive. Il y aura de toute manière une rétrospective anonyme. Ce dojo semble déjà porter des fruits, une équipe vient déjà mettre en pratique ces derniers jours ce qui a été vu dans le randori : développement d’une nouvelle histoire d’utilisateur en TDD « pur », mise en pratique des tableaux indexés par types énumérés…
4 Commentaires + Ajouter un commentaire
Commentaires récents
- dans Des tableaux pour l’intégration d’un équipier dans une équipe Scrum
- dans Rétrospectives, la directive première
- dans Des tableaux pour l’intégration d’un équipier dans une équipe Scrum
- dans Des tableaux pour l’intégration d’un équipier dans une équipe Scrum
- dans Des tableaux pour l’intégration d’un équipier dans une équipe Scrum
Joseph, merci beaucoup pour ce commentaire. Comme livres, le plus simple est peut-être de commencer par « Scrum et XP depuis les tranchées » (cf. un billet précédent) – c’est un livre vraiment important, et c’est un des rares en français, et il est gratuit.
A la fin du livre il y a une bibliographie avec les bouquins les plus importants à lire (Schwaber, Beck, Cohn, Poppendieck…)
Bruno
Salut Bruno
Merci beaucoup pour ces tickets très intéressants, un vrai régal à lire.
Une question en passant : quels livres conseillerais tu pour approfondir les sujets « Agile » ?
merci d’avance
++
joseph
Merci Manu pour ces précisions.
Annonce : pour ceux qui voudraient participer à un dojo, le Club Agile Rhône-Alpes organise plusieurs séances ouvertes au public en janvier 2009. L’annonce est ici : http://clubagile.org/evenements/coding-dojo/
B.
Hello Bruno,
je suis content que l’article puisse servir!
Vous avez raison d’être critiques: nous ne sommes pas une référence, nous essayons tout simplement des pratiques.
+ Niveau d’expérience des développeurs intégrés à l’équipe:
Les développeurs que nous accueillons sont toujours débutants dans les pratiques agiles. Ce n’est pas un choix. Ils ont rarement une pratique sérieuse des tests ou des principes avancés de conception objet (SRP, LSP, OCP, DIP, ADP … cf livre d’Uncle Bob). Cela n’est pas un choix non plus. Par contre, on accueille des développeurs de toutes anciennetés dans le développement de logiciels.
+ Gizmo
L’objectif est:
+ d’apprendre à découper son travail en petites activités livrables;
+ de stimuler l’entre-aide dans l’équipe;
+ d’apprendre à faire de l’intégration continue « à la main »;
+ de fluidifier le flux de valeur en s’amusant.
+ Objectifs individuels / collectifs
Je suis désolé de ne pas aider, mais nous n’avons pas de solution. Nous sommes en désaccord sur ce point avec notre management. D’ailleurs, on me demande de retirer ce point de l’article …
Bon courage à vous!
A++
ManU
—