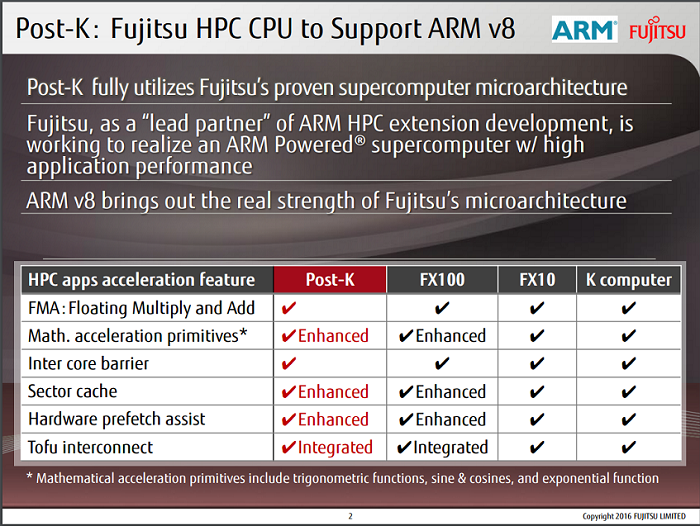
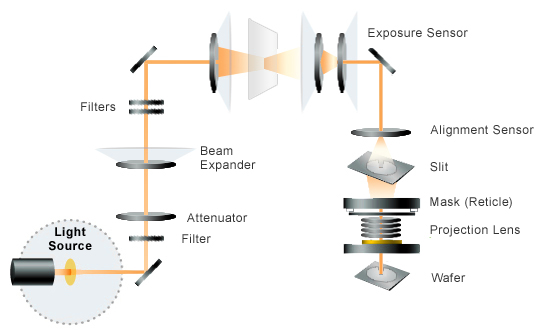
Dans l’industrie des semiconducteurs, la loi de Moore suppose que la quantitĂ© de transistors sur une puce double tous les deux ans (la taille de ces puces Ă©tant limitĂ©e par les processus de production). Jusqu’Ă prĂ©sent, bien qu’entièrement empirique, elle a Ă©tĂ© respectĂ©e, mĂŞme si de plus en plus de gens la dĂ©clarent morte : il faut maintenant plus de deux ans pour doubler la densitĂ© de transistors. Par exemple, Intel a annoncĂ© avoir changĂ© son cycle d’ingĂ©nierie des processeurs : le rythme est toujours d’une nouvelle gamme de processeurs par an, une pour l’amĂ©lioration du processus physique (Core 5e gĂ©nĂ©ration, dite Broadwell, sortie en 2014-2015), une pour l’amĂ©lioration de la microarchitecture (Core 6e gĂ©nĂ©ration, dite Skylake, sortie en 2015-2016), puis une d’optimisation (Core 7e gĂ©nĂ©ration, dite Kaby Lake, qui devrait commencer Ă arriver dans les rayons fin de cette annĂ©e 2016).
Cependant, mĂŞme les industriels ne sont pas toujours entièrement d’accord avec l’affirmation que la loi de Moore est morte : elle pourrait continuer Ă s’appliquer dans la prochaine dĂ©cennie grâce Ă une nouvelle gĂ©nĂ©ration de transistors 3D. Chez Intel et les autres fondeurs qui exploitent des processus 14-16 nm, les transistors actuellement gravĂ©s sur les processeurs sont dĂ©jĂ en 3D, des FinFET. Plusieurs de ces transistors doivent ĂŞtre associĂ©s pour effectuer une opĂ©ration sur un ou plusieurs bits, c’est-Ă -dire former une porte logique (par exemple, le complĂ©ment d’un bit, le ET logique de deux bits, etc.) ; les fonctions intĂ©ressantes des processeurs sont obtenues en combinant ces portes logiques.
Adieu CMOS ?
Les idĂ©es en cours de dĂ©veloppement dans l’industrie partent plutĂ´t sur un changement de paradigme plus profond que simplement des transistors 3D amĂ©liorĂ©s. Pour former des portes logiques (par exemple, un NOT), ces transistors sont associĂ©s en paires : un seul des deux transistors de la paire laisse passer du courant en sortie, l’autre Ă©tant bloquĂ© (ce qui permet de choisir la valeur binaire en sortie, selon la tension reliĂ©e Ă chacun des deux transistors). Ces paires sont donc symĂ©triques (chacun des deux transistors effectue la mĂŞme opĂ©ration), mais complĂ©mentaires (chacun est reliĂ© Ă une tension diffĂ©rente). Ce principe est Ă la base des technologies CMOS (complementary metal-oxyde semiconductor), prĂ©dominantes sur le marchĂ© des semiconducteurs depuis les annĂ©es 1960.
Cette technologie CMOS a bon nombre d’avantages, comme une consommation d’Ă©nergie rĂ©duite en fonctionnement statique (le transistor consomme une certaine quantitĂ© d’Ă©nergie pour commuter, mais presque rien sinon) ou une grande immunitĂ© au bruit. Par contre, il est très difficile d’assembler les transistors en trois dimensions. Pour augmenter la densitĂ© de transistors sur une mĂŞme puce, la seule solution, dans le paradigme CMOS, est de rĂ©duire la taille de chaque transistor : c’est ce qui est fait depuis des annĂ©es dans l’industrie, en amĂ©liorant les processus de lithographie. En passant dans la troisième dimension, il devient possible d’augmenter la densitĂ© de transistors sur une mĂŞme puce sans forcĂ©ment changer ces transistors. Il n’empĂŞche que les processus de lithographie doivent s’adapter Ă cette nouvelle manière de penser.
De nouvelles portes logiques
Ce type de construction devient un choix de plus en plus clair : quand la taille de la plus petite altĂ©ration du silicium tend vers 10 nm, les courants de fuite Ă travers les transistors deviennent problĂ©matiques. Ă€ l’horizon 2020-2025, la situation aura empirĂ©, puisque la lithographie aura atteint des prĂ©cisions de gravure de quelques nanomètres, c’est-Ă -dire Ă peine quelques dizaines d’atomes (un atome de silicium a un diamètre de 0,22 nm). Ă€ cela s’ajouteront d’autres problèmes d’ordre quantique (l’effet tunnel permettra Ă des Ă©lectrons de franchir un transistor).
Dans cette ère nanoscopique, l’Ă©lectronique CMOS serait remplacĂ©e par des transistors Ă spin ou des transistors Ă effet tunnel (TFET), afin de rĂ©duire la consommation Ă©nergĂ©tique (le facteur limitant des processeurs actuels). Ces TFET peuvent fonctionner Ă des tensions bien plus faibles que les transistors actuels tout en ayant un courant de fuite très faible ; de mĂŞme, les transistors Ă spin consomment peu d’Ă©nergie (ils stockent l’information dans le spin d’Ă©lectrons) et seraient très adaptĂ©s au stockage non volatil.
Avantages de la construction 3D
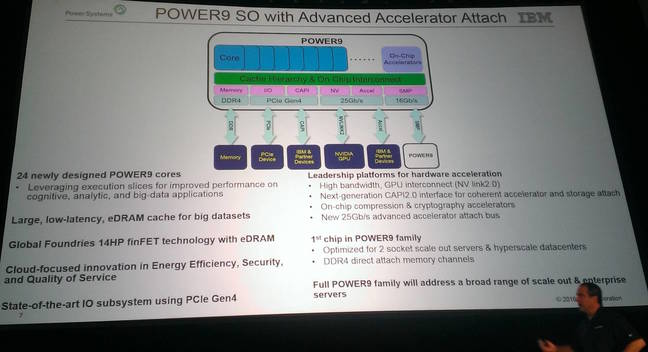
Actuellement, cette technique de construction en 3D est nommĂ©e 3D power scaling par les industriels. Une version proche est dĂ©jĂ sur le marchĂ© : plusieurs couches de silicium sont empilĂ©es et connectĂ©es verticalement par des TSV, mais chaque couche garde sa logique CMOS. Ces TSV sont Ă l’origine de la mĂ©moire HBM ou HMC, oĂą les principales difficultĂ©s d’assemblage viennent de l’alignement parfait requis entre les diffĂ©rentes couches. 3DPS Ă©viterait ce problème, puisque les transistors seraient construits aussi Ă la verticale dans un seul processus intĂ©grĂ©.
La mĂ©moire NAND (utilisĂ©e pour les cartes mĂ©moires et les SSD) utilise dĂ©jĂ des procĂ©dĂ©s de type 3DPS, avec trente-deux Ă soixante-quatre couches (notamment chez Samsung). Les industriels estiment que l’avenir des semiconducteurs en gĂ©nĂ©ral est dans ces puces multicouches, y compris pour les processeurs, voire pour l’Ă©lectronique de puissance. Le plus gros problème est la dissipation de l’Ă©nergie consommĂ©e : la chaleur serait alors bien plus concentrĂ©e, la recherche de transistors bien moins Ă©nergivores est un prĂ©requis indispensable Ă un dĂ©ploiement Ă plus grande Ă©chelle des processus 3D ; peut-ĂŞtre faudrait-il alors penser Ă refroidir les puces de l’intĂ©rieur.
Cette nouvelle manière de penser l’organisation des puces aurait d’autres avantages, notamment celui de pouvoir intĂ©grer bien d’autres composants directement sur la mĂŞme puce que le processeur : les registres pourraient ĂŞtre situĂ©s sous les cĹ“urs de calcul, la mĂ©moire Ă quelques niveaux de la partie calcul du processeur, d’autres circuits pourraient aussi ĂŞtre intĂ©grĂ©s. Ainsi, les distances entre toutes ces parties seraient fortement rĂ©duites, ce qui limiterait de facto les dĂ©lais de propagation et pourrait augmenter de manière phĂ©nomĂ©nale la puissance de calcul disponible. Aussi, les canaux de transmission auraient une section utile bien plus importante qu’actuellement, ce qui limiterait l’impact du bruit.
La recherche est toujours en cours au niveau des transistors adaptĂ©s Ă ces nouvelles directions, mais les industriels ont bon espoir et estiment qu’ils devraient arriver en production dans la prochaine dĂ©cennie. Bien qu’ils Ă©vitent toute annonce au niveau des gains en performance ou des coĂ»ts, ils estiment que, grâce Ă ces technologies, la loi de Moore pourrait mĂŞme ĂŞtre dĂ©passĂ©e.
Source : Next-Generation 3D Transistors Could Rejuvenate Moore’s Law.
Voir aussi : rapport ITRS 2015 (chapitre 9).