Datastage fait partie de la suite WebSphere d’IBM ( maintenant Infosphere ), il fait partie des principaux ETL adoptés chez les grands comptes. Il possède son propre moteur de traitement ( Engine-based ), ainsi que son propre référentiel.
La version max que je connais est la 7.5.2
Un exemple de job :
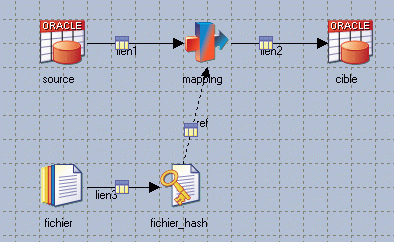
( Alimentation d’une table Oracle Ă partir d’une autre table Oracle en effectuant une jointure avec un fichier texte en rĂ©fĂ©rence )
Les + :
- graphiquement attractif – de jolis dessins en 3d
- on voit le cheminement/flux de la donnée ( sources/cibles, les différents traitements : tri, agrégation )
- pas besoin de connaitre le SGBD ( fonctions sql, procédures )
- les fichiers hash pour dédoublonner en ne gardant que le dernier enregistrement
- les variables dans les transformer pour comparer avec les valeurs de la ligne précédente
Les – :
- boĂ®te noire – on ne sait pas trop comment il fonctionne
- un nouveau langage Ă apprendre mĂŞme s’il est estampillĂ© basic …
- les performances sont vite dégradées sur de grosses volumétries, car il fonctionne en mode curseur ( ligne par ligne )
- analyse d’impact peu poussĂ©e
- limites du basic
Le plus gros point faible pour moi concerne les performances. En effet on est vite amenés à tout coder en sql notamment pour les tris, les agrégations et les jointures. On se retrouve alors avec des jobs assez simples ( 3 stages : une source avec un sql complexe, un mapping et une cible )
Pour l’analyse d’impact, le lien avec les mĂ©tadonnĂ©es est perdu lors du dĂ©veloppement. Par exemple, on importe la structure d’une table T dans le rĂ©fĂ©rentiel, on crĂ©e un job et en source on prend la table T dont on importe la structure depuis le rĂ©fĂ©rentiel. Mais il n’y a pas de lien entre le job et la mĂ©tadonnĂ©e dans le rĂ©fĂ©rentiel, si on change la structure de T dans les mĂ©tadonnĂ©es il n’y a pas d’alerte sur le job qu’on a crĂ©Ă© !!!
L’analyse d’impact se fait alors principalement par mot clĂ©, ce qui pose problème avec des mots clĂ©s bateau qu’on retrouve partout !!!
Pour le basic, d’accord on est indĂ©pendant du SGBD mais on a un nouveau langage avec toutes ses subtilitĂ©s.
Par exemple, pour extraire une chaine :
toto[4] = les 4 derniers caractère du champ toto
pour avoir la date système au format DD/MM/YYYY HH24:MI:SS d’Oracle :
OCONV(Date(),"D-YMD[4,2,2]"):" ":Oconv(time(), "MTS")
D’autre part, certaines fonctions/opĂ©rateurs très pratiques ne sont pas Ă©crites comme le NVL, BETWEEN, IN …
C’est dommage, car certains aspects du BASIC Datastage sont sĂ©duisants, comme l’utilisation indiffĂ©rente des » ou des ‘ pour dĂ©finir une chaĂ®ne de caractères
( on peut Ă©crire "toto", 'toto', "aujourd'hui" ou 'des "guillemets"' )
Pbs courants :
- obligation de trier les colonnes dans un stage Aggregate … sinon plantage …
- pbs de mĂ©moire lorsqu’on utilise le stage de tri …
–> on trie et on somme en sql 
- le fichier hash dĂ©doublonne sans prĂ©venir …
–> alertes non remontĂ©es
Par exemple, on rĂ©cupère les noms Ă partir d’un login, mais on a une Ă©volution en source qui fait qu’on peut avoir diffĂ©rents noms pour 1 login
En utilisant le fichier hash, on rĂ©cupère un des noms … mais pas forcĂ©ment le bon … et ce n’est pas remontĂ© …
En rĂ©cupĂ©rant le nom via une requĂŞte, on aurait des doublons en entrĂ©e –> plantage
Il faut donc toujours mettre une contrainte d’unicitĂ© en base sur les clĂ©s des fichiers hash pour Ă©viter ce pb.
- pas de remontée/warning des lignes non mises à jour
ex : un job traite une volumĂ©trie de 100 000 lignes, mais aucune ligne n’est mise Ă jour
–> il n’y a aucune remontĂ©e, le job semble avoir maj les 100 000 lignes
- pb ETL : il faut ĂŞtre vigilant qu’on fonctionne en mode curseur
–> si on a un traitement qui met Ă jour les dossiers, et en entrĂ©e 10 fois le mĂŞme dossier, on aura 10 mises Ă jour de la mĂŞme ligne, sans remontĂ©e d’alerte !!!
Pbs Ă©nervants :
- renommage colonne en amont –> il faut tout changer en aval
- les messages d’erreur laconiques ( pb des phantom … ), oĂą on passe des heures Ă dĂ©buguer ligne par ligne pour trouver ce qui ne va vraiment pas !
–> notamment sur les routines, quand on a du null en argument …
Quelques conseils :
- rĂ©sister Ă l’envie d’Ă©crire un seul « gros » job qui fait tout ( mĂŞme si c’est possible ). Il vaut mieux Ă©crire des jobs « basiques », avec le minimum de stages – c’est plus simple Ă maintenir et Ă tester
- Ă©viter les stages tri et agrĂ©gat, ils amènenent souvent leurs lots d’erreurs incomprĂ©hensibles
- les stages folder et rowsplitter donnent envie quand on a plusieurs fichiers Ă traiter, mais ils ne sont vraiement pas pratiques Ă dĂ©buguer – pensez Ă votre prochain, rester aux stages simples de fichier …
En conclusion :
Au dĂ©but on trouve l’application gĂ©niale, c’est quand mĂŞme plus sympa que les tristounets scripts sql lancĂ©s en batch… Et on dĂ©chante assez vite devant les performances et les problèmes rencontrĂ©s … Du coup on simplifie les jobs au maximum et on met tous les traitements dans les sql … en se demandant si on n’Ă©crirait pas Ă la place des scripts sql qui seraient plus performants !!!
Pour moi Datastage fait partie des « anciennes » gĂ©nĂ©rations d’ETL qui n’ont pas vraiment su se renouveler.
La montĂ©e en version n’a pas apportĂ© grand chose, Ă part un lifting graphique rĂ©ussi.
La version 8 ne me semble pas plus innovatrice, IBM rĂ©pondant au problème de performance avec du parralĂ©lisme … De plus l’offre devient plus floue, avec 2 versions de Datastage ( PX et Server ) dont celle correspondant Ă l’ancienne qui n’Ă©volue plus !!!
Je lui prĂ©fère SunopsiS/ODI ou Talend pour les raisons que j’expliquerais plus tard dans un autre article ..
