Que faut-il choisir entre Un modèle en étoile ou un modèle en flocons ?
On se pose tous la mĂªme question quand on commence la conception, sans avoir d’Ă©lĂ©ments de rĂ©ponse.
Je vais essayer ici de donner les différences entre les deux types de modélisation, et mon point de vue sur la question.
Mais avant quelques rappels :
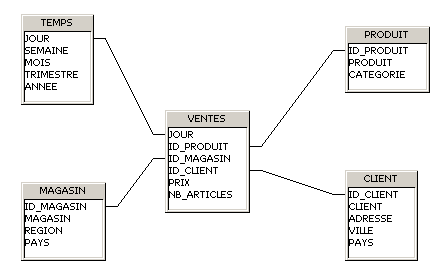
Le schéma en étoile :
Les dimensions sont dĂ©normalisĂ©es afin de concentrer toutes les informations en une seule table. Cela implique qu’on y retrouve certaines colonnes ayant plusieurs fois les mĂªmes valeurs.
Elles sont disposĂ©es autour d’une table de faits, Ă la manière d’une Ă©toile.
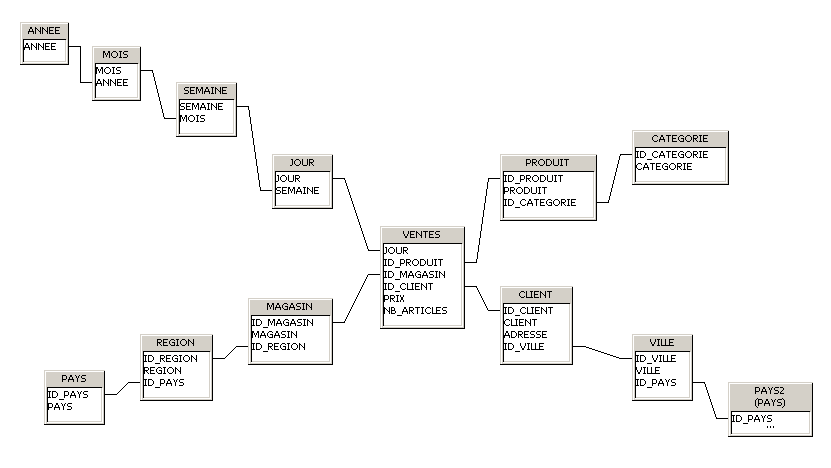
Le schéma en flocons :
Seules les dimensions changent par rapport au modèle en étoile.
Dans le schéma en flocons, elles sont normalisées. Au lieu de tout concentrer en une seule table on a plusieurs tables liées en une arborescence, chaque niveau de la hiérarchie donnant lieu à une table.
>
Les différences :
1/ Performances
Avantage : — Ă©toile ? –
On dit souvent que le modèle en Ă©toile est plus performant. Cela est dĂ» au fait qu’il y a moins de jointures Ă faire que sur un modèle en flocons.
Je dirais que c’Ă©tait vrai il y a quelques annĂ©es, quand les SGBD Ă©taient moins performants.
Mais actuellement la diffĂ©rence est minime, les SGBD gĂ©rant mieux les jointures multiples. De plus les jointures supplĂ©mentaires mettent en oeuvre gĂ©nĂ©ralement des tables Ă faible volumĂ©trie. Cependant il suffit que les stats Oracle soient mal calculĂ©es pour obtenir des plans d’exĂ©cution erronĂ©s et plomber un modèle en flocons.
1bis/ Contre-performance :
Une table de dimension en jointure réflexive dans un modèle en flocons est à proscrire.
Par exemple si on a une table de hierarchie dĂ©crivant la structure de l’entreprise, une colonne « père » permettant de faire le lien sur la mĂªme table
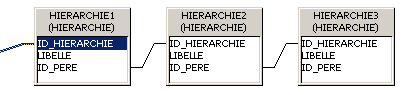
Le SGBD va lire plusieurs fois la mĂªme table, les accès concurrents se faisant sur le mĂªme disque les performances seront très dĂ©gradĂ©es.
Il vaut mieux créer plusieurs tables différentes, chacune représentant un niveau de la hiérarchie.
2/ Volumétries
Avantage : — flocons –
Si la dimension a de nombreux attributs, on a une table qui prend plus d’espace pour le modèle en Ă©toile.
Il vaut mieux choisir un modèle en étoile sur de grosses volumétries quand le ratio devient faible ( 1:50 ), sinon en aplatissant en une seule table les redondances seront trop nombreuses.
3/ Compréhension
Avantage : — flocons –
Certains disent que les modèles en étoile sont plus compréhensibles au premier abord car ils sont plus lisibles, aérés.
Pourtant les hiĂ©rarchies sont plus comprĂ©hensibles par les utilisateurs dans un modèle en flocons, puisqu’elles sont reprĂ©sentĂ©es par les jointures. Alors que dans un modèle en Ă©toile on a plus de mal Ă voir quel attribut est avant l’autre …
4/ Modèles spécifiques
Avantage : — flocons –
Le modèle en flocons est plus adapté pour les relations n n.
Par exemple si on prend la dimension Compte/Client dans le secteur bancaire, 1 compte a 2 clients, et 1 client a plusieurs comptes …
5/ Tables agrégées
Avantage : — flocons –
Le modèle en flocons est adaptĂ© aux tables agrĂ©gĂ©es comme les vues matĂ©rialisĂ©es d’Oracle.
Prenons par exemple une table ventes à volumétrie importante.
Pour des raisons de performance on l’a agrĂ©gĂ©e suivant la semaine, le mois et l’annĂ©e. Ainsi en fonction de la granularitĂ© utilisĂ©e, on utilisera la table Ă la plus faible volumĂ©trie.
Avec le modèle en flocons, les jointures sur les dimensions se font simplement.
Par contre avec le modèle en Ă©toile, avec une seule dimension calendrier ayant le jour en point d’entrĂ©e, il faudra :
– soit crĂ©er des vues sur la table calendrier au niveau semaine, mois et annĂ©e et qui dĂ©doublonneront les lignes ( avec un distinct ) pour ne pas multiplier les rĂ©sultats.
– soit bricoler les jointures dans l’applicatif de restitution ( par exemple lier une table agrĂ©gĂ©e au mois sur le 1er jour du mois )
6/ Attributs partagés
Avantage : — flocons –
On a souvent des niveaux partagés entre plusieurs dimensions comme le pays dans notre exemple.
Dans un modèle en étoile ces niveaux sont dupliqués dans chaque table, ce qui implique de bons process pour synchroniser les données dans toutes les tables.
Dans un modèle en flocons on n’a pas ce problème car on n’a qu’une seule table.
5/ Applicatifs
Avantage : — aucun –
Certaines applications comme Microstrategy DSS nĂ©cessite un modèle en flocons … J’ai vu un modèle en Ă©toile sur lequel on dĂ©finissait des vues pour le transformer en flocons … c’est dommage non ?
6/ SCD
Avantage : — flocons –
On peut scinder une dimension en SCD dans un modèle en flocons, ce qui est idéal pour de grosses volumétries ou une dimension avec de nombreux attributs.
7/ Simplicité
Avantage : — Ă©toiles –
Le modèle en Ă©toile est plus un modèle « de fainĂ©ants » …
Les requĂªtes SQL sont + faciles Ă Ă©crire, puisqu’il y a moins de jointures. De mĂªme la modĂ©lisation est plus simple et plus rapide.
Conclusion
Il est difficile de choisir entre les 2 types de modèles quand il n’y a pas d’applicatifs ou de fonctionnements spĂ©cifiques.
D’expĂ©rience on part souvent sur un modèle en Ă©toile Ă la Kimball qui est rĂ©putĂ© performant et pratque en dĂ©cisionnel. Et puis on revient sur des parties de dimension qui sont partagĂ©es, et qu’on « dĂ©normalise » en parties de modèle en Ă©toiles.
A mon avis c’est surement la meilleure solution, un modèle hybride qui fait du flocon sur des parties spĂ©cifiques ( SCD, niveaux partagĂ©s ) et de l’Ă©toile pour le reste …
