Certains aficionados de PostGreSQL tente de comparer PostGreSQL Ă Oracle, affirmant que PostGreSQL fonctionne presque pareil…
Alors, puisque c’est le cas, renchĂ©rissent leurs Ă©conomes, ne payons plus de licences et migrons que diable !
Pourtant de nombreux spĂ©cialistes des bases de donnĂ©es ayant une importante expĂ©rience dans l’utilisation de divers SGBDR et ayant dĂ» utiliser PostGreSQL en remplacement d’Oracle ou SQL Server s’en sont mordu les doigts…
Voici quelques uns des Ă©cueils qui peuvent vous attendre le jour ou vous passerez d’une base commerciale comme IBM DB2 UDB, Oracle ou SQL Server Ă PostGreSQL.
1 – Aucune gestion des espaces de stockage.
Dans les SGBDR comme Oracle, SQL Server ou IBM DB2, il est possible de gérer les espaces de stockage de manière très précise, et cela afin de savoir précisément ou se trouve une table ou un index, en sus de pouvoir régler la taille et le taux de croissance des espaces de stockage.
Le principe est gĂ©nĂ©ralement le suivant. A une base de donnĂ©es est associĂ© un ou plusieurs espaces de stockage (« storage » dans la littĂ©rature anglo saxonne) que l’on appelle « tablespace » dans Oracle et « filegroup » dans SQL Server. Ces espaces de stockage constitue la destination du stockage des donnĂ©es des tables. A la crĂ©ation d’une table ou d’un index, il suffit de prĂ©ciser le « storage » que l’on souhaite affectĂ© Ă l’objet.
Chaque storage doit comporter au moins un fichier, mais peut en compter plusieurs.
Pour chaque fichier créé on peut généralement préciser la taille minimale, maximale et le pas de croissance.
En fixant une taille minimale, le fichier est directement crĂ©Ă© de la taille prĂ©cisĂ© (ce n’est pas une prĂ© rĂ©servation d’espace comme on le croit trop souvent) et l’algorithme utilisĂ© permet d’aller scruter les disques Ă la recherche du meilleur emplacement possible pour les donnĂ©es. Ce meilleur emplacement sur un disque neuf est constituĂ© par les cylindres extĂ©rieur de tous les plateaux !
Le but de ce système est double :
- permettre de ventiler les entrées/sorties (IO), à condition que chaque fichier soit créé sur un disque physique indépendant (au revoir les VM et attention aux sans avec des LUNs taillées dans la masse, toutes choses qui constituent une plaie pour les DBE).
- Mais aussi diminuer les temps d’accès disque. On voit bien qu’en utilisant les cylindres externes des disques on fait d’une pierre deux coups : on peut lire des donnĂ©es « simultanĂ©ment » sur diffĂ©rents plateaux Ă la fois et le temps d’accès tend vers celui de la vitesse de rotation des disques.
De plus, les SGBDR comme Oracle, SQL Server ou IBM DB2, sont capable de regrouper les pages Ă Ă©crire par contiguĂŻtĂ© gĂ©ographique, afin de minimiser le trajet de la tĂŞte de lecture. C’est loin d’ĂŞtre nĂ©gligeable et Michael Stonebraker qui a mise en Ă©vidence ce problème [1] et rĂ©alisĂ© quelques uns des algorithmes pour ce faire le sait bien… Il est aussi Ă l’origine de postGreQSL ! Encore faut-il que les espaces de stockage aient Ă©tĂ© crĂ©Ă©e en un seul bloc pour Ă©viter toute fragmentation !
Enfin, Oracle et SQL Server permettent de placer les espaces de stockage que l’on souhaite en READ ONLY, ce qui permet d’Ă©viter tout verrouillage.
A lire, en complément sur le sujet : Question sur les fichiers et le stockage
Or PostGreSQL ne dispose d’aucune gestion des espaces de stockage, autre que celle de dĂ©clarer un ou plusieurs rĂ©pertoire en tant que « storage » pour une base.
La notion de tablespace PG ne fait qu’indiquer un rĂ©pertoire.
Voici la syntaxe PG (v9.1.1):
CREATE TABLESPACE tablespace_name [ OWNER user_name ] LOCATION 'directory'
Ce que vous ne pouvez pas faire avec PostGreSQL :
1) vous ne pouvez pas indiquer une taille minimale de l’espace de stockage
2) vous ne pouvez pas indiquer une taille maximale de l’espace de stockage
3) vous ne pouvez pas indiquer un pas de croissance de l’espace de stockage
4) vous ne pouvez pas ajouter un autre répertoire a un tablespace déja créé
5) vous ne pouvez pas placer un espace de stockage en READ ONLY pour des tables statiques afin d’Ă©viter le verrouillage
Toutes ces possibilitĂ©s existent sur Oracle, SQL Server, IBM Db2, Sybase ASE…
2 – Une gestion des transactions « curieuse ».
Une fonction SQL (il n’existe pas de procĂ©dure stockĂ©e dans PostGreSQL) peut encapsuler n’importe quel code SQL du DML (INSERT, SELECT, UPDATE, DELETE) et semble agir comme une procĂ©dure stockĂ©e, Ă une exception près : il est impossible de gĂ©rer une transaction Ă l’intĂ©rieur du code d’une fonction postGreSL. En fait PostGreSQL considère qu’une fonction = une transaction !
Ceci pose de nombreux problèmes…
Le fait qu’une fonction soit en elle mĂŞme une transaction est un choix plus que discutable. En effet que se passe t-il si vous avez lancĂ© une transaction qui lance une procĂ©dure ? (transactions imbriquĂ©es)
Le cas des transactions imbriquées est toujours complexe, mais sans méthode de résolution, il est difficile de savoir ce qui se passe.
En sus ce n’est pas parce que il y a une erreur que l’on doit considĂ©rer automatiquement que la transaction doit ĂŞtre annulĂ©. C’est en principe l’auteur du code et lui seul qui doit dĂ©cider de la règle de gestion et non le SGBDR !
ConsidĂ©rant par exemple, une gestion de stock, on peut essayer de dĂ©stocker du matĂ©riel et partir en erreur dans une table car on dĂ©passe le seuil. Mais on peut alors dĂ©cider en cas d’erreur de lancer une commande. Ce que visiblement PG ne sais pas faire au sein d’une mĂŞme fonction…
On prĂ©sente souvent le langage PLpgSQL comme l’Ă©quivalent du PL/SQL d’Oracle… Il n’est en Ă©videmment rien. Seul quelques Ă©lĂ©ments de syntaxe sont commun…
Quand Ă la rĂ©criture d’une base de donnĂ©es avec de nombreuses transactions effectuĂ©es dans de nombreuses procĂ©dures, c’est un vĂ©ritables cauchemar Ă transposer en PostGreSQL !
Un exemple nous est fournit avec la demande suivante Ă©manent du forum PostGreSQL : « Pouvoir lancer deux fonctions qui utilisent la mĂŞme table ». Ce serait si simple avec une gestion de transactions Ă l’intĂ©rieur de la procĂ©dure !!!
3 – Un partitionnement plus que lĂ©ger
Comme le dit Mladen Gogala « Postgres partitioning is not very robust » ce que confirme diffĂ©rents internautes (voir ce message).
Dans cet article « Partitionner une table. Comparaison PostGreSQL / MS SQL Server » je mentionne l’extrĂŞme complexitĂ© du partitionnement et les risques Ă©normes de se tromper.
Les dĂ©veloppeurs de PostGreSQL conscient du problème ont rĂ©agit. A lire « Table Partitionning » mais hĂ©las ce ne sont que des paroles ! Une nouvelle version du partitionnement devait voir le jour avec la version 9.0. Nous en sommes Ă la 9.1 et toujours rien !
4 – Pas de tag (hint) pour forcer les plans de requĂŞte
L’un des principaux griefs des Oracliens sur PostGreSQL est l’absence de hint (ou tag de requĂŞte) permettant de forcer le plan. Ce peut ĂŞtre par exemple d’indiquer qu’il faut toujours prendre tel index et jamais la table ou que l’algorithme de la jointure doit ĂŞtre celui-ci et non un autre.
L’utilisation des tags de requĂŞte ne doit pas ĂŞtre entrepris Ă la lĂ©gère car il fige un plan qui devrait ĂŞtre rĂ©Ă©valuĂ© Ă chaque modification de la distribution des donnĂ©es comme du volume. Mais il y a des cas ou la science de l’optimiseur est pris en dĂ©faut et d’autre ou l’on souhaite contraindre explicitement, par exemple pour Ă©viter un verrou de table.
Or la philosophe particulièrement croustillante des dĂ©veloppeurs de PG est que c’est très mal de mettre des tags dans les requĂŞtes : « Why PostgreSQL Doesn’t Have Query Hints »
Dans un monde parfait, cela serait absolument gĂ©nial… Mais malheureusement il y a la rĂ©alitĂ©, et lĂ force est de constater que l’optimisation des requĂŞtes par PostGreSQL est loin d’ĂŞtre… optimale !
Voici un exemple calamiteux ou PostGreSQL choisit de lire une table constituée de 50 pages plutôt que de lire un index de 2 pages (testé en version 9.1) :
CREATE TABLE T (NID INT NOT NULL, DATA VARCHAR(8000));
INSERT INTO T SELECT 1, REPEAT('@', 8000);
INSERT INTO T SELECT MAX(NID), REPEAT('@', 8000) FROM T;
--> répétée 50 fois
CREATE INDEX X ON T (NID);
SELECT NID FROM T;
Le plan de requĂŞte de PostGreSQL est le suivant :
Seq Scan on t (cost=0.00..11.40 rows=140 width=4)
On voit que PostGreSQL balaye lamentablement toute la table alors qu’il devrait utiliser l’index qui ne contient que la colonne visĂ©e par le SELECT !
Dans un SGBDR commercial qui commettrait une telle Ă©tourderie, on rajouterais par exemple un tag du style :
SELECT NID FROM T WITH(INDEX(X));
Les seuls paramĂ©trages de PostGreSQL le sont au niveau du serveur ou de la session, ce qui ne permet vraiment pas de corriger les erreur de l’optimiseur pour certaines requĂŞtes…
Mais il existe une alternative… Utiliser une version payante de PostGreSQL, appelĂ©e EnterpriseDB qui, curieusement intègre les tags !.
Ce qui contredit les dĂ©tracteurs du « y’a pas besoin de tag de requĂŞte dans SQL Server, puisque son optimiseur est parfait ! »… Mais alors pourquoi et comment EnterpriseDB arrive-il Ă vendre leur solution (4 495 $ par an, service d’assistance compris) ?
5 – un optimiseur très limitĂ©
Nous venons de voir une erreur de l’optimiseur très grossière… Ce n’est hĂ©las pas la seule. Dans l’article sur le partitionnement nous avons montrĂ© des plans de requĂŞtes particulièrement Ă©pouvantable Ă´tant tout intĂ©rĂŞt au partitionnement
Il n’est qu’a consulter la mailing list consacrĂ© au sujet des performances de PostGreSQL pour constater les difficultĂ©s de certains pour obtenir un plan de requĂŞte efficace.
Une des anomalies les plus frĂ©quente est celle concernant le calcul des statistiques qui permettent Ă l’optimiseur de choisir le bon plan de requĂŞte. Il semble qu’il faille rĂ©gulièrement changer le nombre d’histogramme de l’échantillonnage que PG effectue. Quel est le bon rĂ©glage ? Ă€ priori il semble dĂ©pendre de la dispersion des donnĂ©es et du nombre de lignes… Bref, une partie du travail de l’optimiseur doit ĂŞtre fait au quotidien par le DBA… Pas très pratique !
6 – Une indexation Ă la traine
En matière d’index, PostGreSQL montre certaines lacunes. Par exemple il n’y a toujours pas d’index couvrants (clause INCLUDE), ni d’index XML et la mĂ©thode d’indexation de PostGIS avec les index GIST est loin d’ĂŞtre d’une grande efficacitĂ©. Pour un comparaison, lire « Tout sur l’index »
Il n’existe pas non plus de vues matĂ©rialisĂ©es comme ce qu’offre Oracle ou de vues indexĂ©es Ă la SQL Server. C’est pourtant d’une redoutable efficacitĂ© dès que l’on a des calculs d’agrĂ©gats portant sur de forts volumes de donnĂ©es.
En sus il n’y a pas moyen de savoir quel sont les index manquant comme on le trouve par exemple dans MS SQL Server avec les vues systèmes sys.dm_db_missing_index_details et autres.
Bien qu’il soit possible de savoir comment sont utilisĂ©s les index (vue pg_stat_sys_indexes) les informations ne montrent pas le nombre de mise Ă jour effectuĂ©es sur l’index qu’il faut aller rĂ©cupĂ©rer par approximation au niveau table (pg_stat_all_tables).
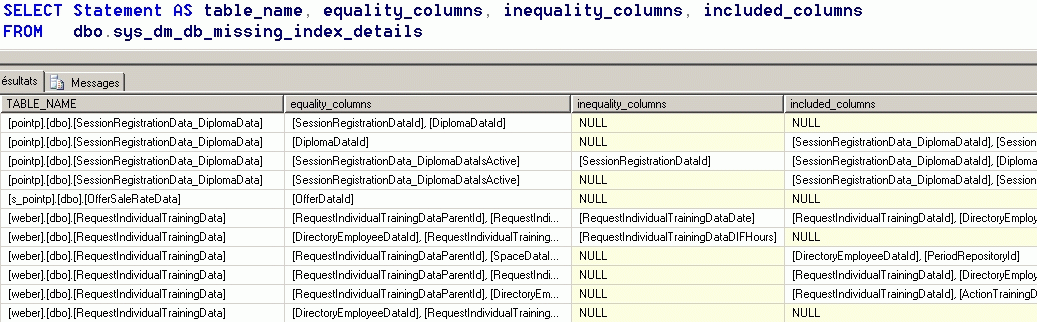
Liste des index manquants (MS SQL Server)
Avec PostGreSQL, il faut donc deviner quel sont les index Ă poser et ceux Ă supprimer, et comme les outils de monitoring sont assez pauvres, la partie est loin d’ĂŞtre gagnĂ©e…
7 – Pas de parallĂ©lisme des requĂŞtes
Lors d’un congrès PG Days organisĂ© par Dalibo, Bull montrait comment les caisses d’allocations familiales avaient migrĂ© un ancien système propriĂ©taire de stockage des donnĂ©es en le remplaçant par PostGreSQL. Discutant avec l’un des responsable du projet, ce dernier me confiait que pour lui le principal manque de PostGreSQL rĂ©sidait dans le fait de l’absence de parallĂ©lisme pour traiter une mĂŞme requĂŞte.
Oracle, SQL Server et DB2 savent faire cela depuis de nombreuses annĂ©es…
Les conséquences de cet absence de parallélisme peuvent être très problématiques sur de grands volumes :
- il augmente considĂ©rablement le temps de rĂ©ponse d’une requĂŞte
- la table Ă©tant verrouillĂ©e plus longtemps la concurrence d’accès diminue
Tout cela ne plaide pas en faveur de l’exploitation de grandes bases de donnĂ©es avec PostGreSQL.
8 – Une administration couteuse
Lorsque l’on compare les outils administration des grands SGBDR par rapport Ă l’offre PostGreSQL le DBA se sent immĂ©diatement frustrĂ© !
Son entreprise ne le sait pas encore mais il va lui falloir passer beaucoup plus de temps, car les outils, de monitoring comme ceux administration sont encore embryonnaires. Nous en avons dĂ©jĂ parlĂ© au niveau des index ou tout doit se faire Ă la main (recherches des index manquants ou inutiles). Un seul exemple nous montrera l’Ă©tendu de l’Ă©cart. SQL Server dispose d’un outil de reniflage de l’activitĂ© du serveur (le profiler SQL) qui permet de lister par exemple toutes les requĂŞtes et procĂ©dures, leurs temps CPU ou intrinsèque, le nombre de lectures ou d’Ă©criture, etc et ce de manière ou dĂ©busquer les optimisation a entreprendre. AssociĂ© Ă RML par exemple il permet de faire des tests comparatif en reproduisant exactement (y compris la concurrence des diffĂ©rentes sessions) la charge d’une base ou d’un serveur sur une autre machine configurĂ©e diffĂ©remment.
En comparaison, PostGreSQL ne propose que des outils frustes, simplistes et rarement « friendely user » : pgfouine / trsung. Il faut aller en chercher quelques uns ailleurs, payant bien sĂ»r. Et trouver la documentation pour savoir s’en servir correctement est une gageure car il n’existe aucune mĂ©thodologie…
Ne parlons pas du merveilleux (?) VACUUM, bonne Ă tout faire de PostGreSQL que la plupart des DBA habituĂ©s Ă des outils prĂ©cis et peu intrusifs exècre… Il bloque et lock Ă mort !
9 – pas de pooling des connexions
La plupart des SGBDR comme Oracle ou SQL Server intègre un pooling de connexions. Pas PostgreSQL. Il faut rajouter un module nommĂ© PG Pool pour ce faire. Le pooling permet d’Ă©viter que trop de connexion Ă©croulent le système, en faisant alterner les connexions et les threads d’exĂ©cution entre les diffĂ©rentes demandes.
10 – Pas de vision d’un plan en cours d’utilisation
L’absence de « shared pool » (cache de procĂ©dure partagĂ©) rend impossible de lire le plan d’une requĂŞte qui vient d’ĂŞtre exĂ©cutĂ©e, contrairement Ă ce que l’on peut faire avec Oracle ou SQL Server
11 – Un processus de sauvegarde peu performant
PostGreSQL n’a pas la possibilitĂ© de parallĂ©liser sa sauvegarde sur plusieurs fichiers simultanĂ©ment, ce qui ne permet pas de diviser par n (n Ă©tant le nombre de support de la sauvegarde) le temps de la sauvegarde.
De mĂŞme PostGreSQL ne permet pas de rĂ©aliser des sauvegardes diffĂ©rentielles, c’est Ă dire des sauvegardes qui ne prennent en compte que les donnĂ©es ayant changĂ©es depuis la dernière sauvegarde.
Ce sont des choses indispensables lorsque l’on commence Ă attaquer des bases de grandes volumĂ©tries.
12 – Pas de compression ni de cryptage des donnĂ©es
PostGreSQL ne permet pas de compresser les donnĂ©es Ă aucun moment et n’intègre aucun mĂ©canisme de cryptage. En comparaison SQL Server intĂ©gre le cryptage depuis la version 2005 et la compression au niveau page ou ligne depuis la version 2008.
13 – Pas de rĂ©plication des donnĂ©es *
Mise Ă Part les contributions externes Slony et Londist (peu performant car basĂ©s sur des triggers), PostGreSQL ne dispose d’aucun mĂ©canisme intĂ©grĂ© de rĂ©plication des donnĂ©es, contrairement Ă ce qui se fait par exemple chez SQL Server ou l’on dispose de 4 modes de rĂ©plications en fonction des besoins, en sus de Service Broker qui peut ĂŞtre utilisĂ© dans ce sens : rĂ©plication transactionnelle, rĂ©plication par clichĂ© (snapshot), rĂ©plication de fusion et rĂ©plication point Ă point.
14 – PostGreSQL reste un bon SGBDR rĂ©ellement libre
Après avoir brossĂ© ce tableau noir, dire de PostGreSQL qu’il reste un bon SGBDR semble utopique… Mais c’est pourtant vrai !
En effet, aucun autre SGBDR dans le libre n’arrive Ă la hauteur de PostGreSQL en terme de fonctionnalitĂ©s, de fiabilitĂ© et de performances, lorsqu’on le maintient dans certaines limites. Il m’arrive de le prĂ©coniser en alternative aux SGBDR des principaux Ă©diteurs lorsque ces derniers veulent ne pas payer de licence. Je leur fait connaĂ®tre les limites de l’outil et leur indique que l’administration risque d’ĂŞtre un peu plus couteuse, notamment par rapport Ă SQL Server.
Il convient donc de cantonner PostGreSQL a ce qu’il sait bien faire. C’est Ă dire comme tout bon outil, lui faire faire ce pourquoi il est fait.
En particulier, les limitations absolues que je considère actuellement Ă l’utilisation de PostGreSQL sont les suivantes :
- Une centaine d’utilisateurs concurrents (il peut y en avoir bien plus de connectĂ©, mais Ă©vitions qu’ils lancent touts au mĂŞme moment leur requĂŞte !)
- Des bases limitĂ©es Ă quelques centaines de Go (pour ma part je ne conseille pas d’aller au delĂ de 250 Go toutes bases confondues sur un mĂŞme serveur). Par exemple en l’absence d’un mĂ©canisme de sauvegarde performant le temps de la sauvegarde peu devenir un rĂ©el handicap.
- Des requêtes limitées à quelques tables en jointures ou sous requêtes.
- Une complexité transactionnelle limitée (découper au maximum par les fonctions PG)
- Pas de dĂ©cisionnel. PostGreSQL ne propose pas de technique de stockage spĂ©cifique pour gĂ©rer des bases de donnĂ©es OLAP comme le non stockage du NULL, la compression des donnĂ©es, le prĂ©calcul d’agrĂ©gat, le stockage des rĂ©sultats de requĂŞte en cache…
En matière de requĂŞte portant sur un fort volume de donnĂ©es, je me suis amusĂ© Ă montrĂ© ce que pouvait impliquer en terme de performance les manques fonctionnels des SGBDR comme PostGreSQL et MySQL. Dans cet article « AgrĂ©gation d’intervalles en SQL : en pratique » on constate que PostGreSQL est Ă terme 10 fois moins rapide que SQL Server…
15 – En conclusion
Vous comprendrez que prĂ©senter PostGreSQL comme une alternative crĂ©dible Ă Oracle ou mĂŞme SQL Server sur des bases Ă forte volumĂ©trie, important trafic ou grande concurrence et est un phantasme de nerd mais est loin d’ĂŞtre une rĂ©alitĂ© !
Soyons modeste pour ne pas avoir de couteuses déconvenues et évitons les dogmes.
Je sais qu’en rĂ©digeant un tel article je vais m’attirer les foudres de nombreux internautes. Je m’y attend et reste serein. J’ai des arguments et une expĂ©rience acquise depuis plus de 20 ans par mon travail avec de nombreux SGBDR…
Mais je sais hĂ©las que, chez certains, la passion du libre l’emporte souvent contre la raison du technique !
NOTE :
* Une rĂ©plication de donnĂ©es consiste Ă prendre certaines donnĂ©es de certaines tables et placer ces informations dans une autre base. Certains confondent rĂ©plication de donnĂ©es et duplication d’une base. Un mĂ©canisme comme la « rĂ©plication streaming » n’est pas Ă proprement parler une rĂ©plication, mais la duplication d’une base, c’est Ă dire un mĂ©canisme de haute disponibilitĂ©. C’est l’Ă©quivalent par exemple du mirroring asynchrone dans SQL Server.
RÉFÉRENCES :
Livre cité
[1] A lire dans « Readings in Database Systems » de Joseph M. Hellerstein et Michael Stonebraker
NON, PostGreSQL n’est pas un clone d’Oracle !
Database preferences and product selection methodolgy
« Oracle vs. Postgres (PostgreSQL) »
Migration
Migration de Oracle vers PostGreSQL
Guide de migration vers PostGreSQL
Manques et problèmes de PostGreSQL
Top 10 Missing PostgreSQL Features
Top Missing PostgreSQL Features
PostgreSQL Gotchas (attention, cela date un peu)
Une discussion animĂ©e sur l’absence des tags : Why PostgreSQL doesn’t have query hints
Modules externes compensatoires :
contribution pg_stat_statements pour surveiller les statistiques d’exĂ©cution de tous les ordres SQL exĂ©cutĂ©s par un serveur.
contribution pgcrypto, propose des fonctions de cryptographie
module pg_statsinfos (stĂ© NTT OSS) rapports statistiques d’activitĂ© du serveur
Fonctionnement interne de PostgreSQL
Postgres Internals Presentations (Bruce Momjian)
A Tour of PostgreSQL Internals (Tom Lane)
Inside the PostgreSQL Shared Buffer Cache (Greg Smith)
Performances PostGreSQL vs SQL Server
Même chez Enterprise DB qui fournit un PostGreSQL Amélioré on est conscient des manques de postGreSQL qui font la différence. Question de crédibilité !
PostgreSQL Performance vs. Microsoft SQL Server
Un des rares benchmark sérieux : Open Source PostgreSQL Trails Oracle In Benchmark, But Not By Much
Une exemple de comparatif inepte :
Oracle vs PostgreSQL
A la lecture de cet Ă©difiant tissus de mensonges et d’âneries on se demande encore pourquoi tant d’entreprise et de collectivitĂ©s continuent d’utiliser Oracle…
Un exemple de comparatif technique très documenté :
Plans de requĂŞtes et tags (hints en anglais)
Why the F&#% Doesn’t Postgres Have Hints?!?!
Le point de vu d’un contributeur PG
DISCUSSIONS…
Mon article ayant fait polĂ©mique, les internautes ont postĂ©s un peu partout. Voici quelques un des liens pour suivre les conversations animĂ©es en cours…
Forum PostGreSQL de developpez.net
Forum francophone de PostGreSQL.fr
Un exemple de la problématique de non existence des sauvegardes différentielles (liste pgsql-general@postgresql.org)
Are file system level differential/incremental backups possible?
****************************
POUR SUIVRE LA DISCUSSION…
****************************
N’hĂ©sitez pas Ă lire les commentaires et en postez vous mĂŞme Ă l’entrĂ©e figurant dans ce lien….
--------
Frédéric Brouard, SQLpro - ARCHITECTE DE DONNÉES, http://sqlpro.developpez.com/
Expert bases de données relationnelles et langage SQL. MVP Microsoft SQL Server
www.sqlspot.com : modélisation, conseil, audit, optimisation, tuning, formation
* * * * * Enseignant CNAM PACA - ISEN Toulon - CESI Aix en Provence * * * * *
![]()
Voici un autre point de vue sur le sujet.
Je suis DBA Oracle et PostgreSQL dans un grand compte et je fais entre autres des migration de Oracle vers PostgreSQL :
1 – Aucune gestion des espaces de stockage.
L’utilisation des file systems permet de n’avoir que les files systems a surveiller pour le stockage plutĂ´t que les tablespaces + les files systems. C’est plutĂ´t agrĂ©able. Quand au placement sur les disques cela fait plus de 10 ans que je ne le fais plus puisque l’on a plus que des volumes plus ou moins virtuels.
2 – Une gestion des transactions « curieuse ».
Une fonction doit s’inscrire dans une transaction, c’est un chois d’implĂ©mentation. Il semblerait que les transactions autonomes arrivent avec la version 10 en 2017.
3 – Un partitionnement plus que léger
Oui, c’Ă©tait l’utilisation de l’hĂ©ritage ( qui n’existe Ă ma connaissance que dans PostgreSQL )
un partitionnement est en cours d’implĂ©mentation et devrait arriver avec la version 10 en 2017.
4 – Pas de tag (hint) pour forcer les plans de requête
L’exemple porte sur la capacitĂ© de faire un index only scan pour ne lire que l’index plutĂ´t que la table. Cette fonctionnalitĂ© Ă Ă©tĂ© ajoutĂ© en 9.2 https://wiki.postgresql.org/wiki/Index-only_scans
Le fait de ne pas utiliser de hint est un choix, pas une lacune.
Le choix est que dans le cas ou un plan d’exĂ©cution est mal choisi par l’optimiseur en fonction des statistiques, alors il faut corriger l’optimiseur. Si vous avez un cas, soumettez le Ă la bonne mailing list pour que l’optimiseur soit amĂ©liorĂ©.
5 – un optimiseur très limité
Que dire des problèmes de binds picking d’oracle ou le plan d’exĂ©cution est dĂ©cidĂ© d’après les valeur du premier a passer la requĂŞte.
Pour les grands nombre de jointure, PostgreSQL a aussi un optimiseur génétique.
L’optimiseur se base sur les statistiques et souvent le problème est que les statistiques ne reflètent pas les donnĂ©es et qu’il faut les amĂ©liorer pour obtenir un meilleur plan, c’est juste logique.
6 – Une indexation à la traine
De ce coté la, il vaut mieux e pas utiliser les hash, mais il y a les btree, gin, gist, sp_gist, brin, bloom.
Oracle n’en a pas autant et sql server non plus.
Ce n’est pas PostgreSQL qui est a la traine.
7 – Pas de parallélisme des requêtes
C’est arrivĂ© avec la version 9.6 et cela va continuer Ă s’amĂ©liorer.
8 – Une administration couteuse
PlutĂ´t moins couteuse, en tout cas par rapport Ă Oracle que je connais bien. cloud control est gratuit … mais pas les packs
Et il faut d’abord se payer les licences Oracle.
Il existe bien d’autres outils listĂ©s sur le site de PostgreSQL https://www.postgresql.org/download/products/1-administrationdevelopment-tools/
9 – pas de pooling des connexions
Je conseille plutĂ´t pgbouncer que Pg Pool II pour le pooling de connexions.
Des solutions existent …. ce n’est pas un problème.
10 – Pas de vision d’un plan en cours d’utilisation
Le fait de gĂ©rer un cache de plan a un coĂ»t, les plans peuvent ĂŞtre listĂ©s avec l’extension auto explain.
Le fait de cacher et réutiliser les plans pose des problèmes de bind picking chez Oracle.
11 – Un processus de sauvegarde peu performant
barman et pgbackrest permettent de faire des backups full incrémentaux et performants.
12 – Pas de compression ni de cryptage des données
En fait si lorsque qu’il y a le mĂ©canisme du TOAST,il y a compression de certaines donnĂ©es.
Les stratĂ©gies sont diffĂ©rentes entre les SGBD/R … Les donnĂ©es peuvent ĂŞtre posĂ©es sur du LVM chiffrĂ©.
C’est le point qui sera Ă suivre dans les versions Ă venir, il y a des discussions sur le sujet.
13 – Pas de réplication des données
Oh que si, synchrone, asynchrone et mixte.
Je trouve les mode mixte très intĂ©ressant, il permet de taguer les transactions qui doivent ĂŞtre rĂ©pliquĂ©es en ode sychrone alors que le reste est asynchrone, ce qui permet de n’ĂŞtre impactĂ© que pour ce qui est important. Bref, le beurre et l’argent du beurre …
il y a aussi pg_logical et j’attends avec impatience BDR sur la version communautaire
14 & 15 .. Conclusion
Je ne parlerais pas de SQL Server, ne le connaissant pas.
Il y a des domaines ou PostgreSQL est en avance par rapport Ă Oracle, par exemple pour le choix des index, l’extension spatiale, le type JSON et d’autres pour lequel Oracle Ă des avantages comme la compression, le chiffrage et une offre intĂ©grĂ©e de cluster matĂ©riel/logiciel avec exadata …
Pour ce qui est de la volumĂ©trie, l’extension citus permet Ă PostgreSQL de faire du sharding avec rĂ©plication et il y a aussi PG-XL.
Notre plus grosse base en production a dĂ©passĂ© la TeraOctet, le fait que Skype et « le bon coin » par exemple fonctionnent avec PostgreSQL rassure quand Ă la possibilitĂ© de gĂ©rer du volume et de la charge, ce qui n’est simple avec aucun SGBD/R.
Les principes sont les mĂŞme pour tous les SGBD, mais les implĂ©mentations sont diffĂ©rentes et les avantages / dĂ©savantages dĂ©pendent fortement du contexte et de l’utilisation.
SQL Server vient de Sybase qui vient de Ingres dont PostgreSQL qui s’applelait Post-Ingres est un reboot pour Ă©liminer des limitations.
Un exemple édifiant, à mon avis, est que Oracle compacte les données dans ses blocs alors que PostgreSQL les aligne par rapport aux registres du processeur.
Le mĂŞme volume de donnĂ©es pendra (gĂ©nĂ©ralement puisque ce n’est pas si simple) moins de place disque avec Oracle qui donc bĂ©nĂ©ficie de cette lecture moindre que les disques pour sa performance.
D’un autre cotĂ©, avec l’amĂ©lioration des vitesses d’accès au stockage avec les SSD et flashs et bientĂ´t 3D Xpoint, le choix de PostgreSQL sera un avantage puisqu’il n’a pas a dĂ©compacter les donnĂ©es (Ce choix Ă dĂ©jĂ Ă©tĂ© fait pour de la performance).
3D Xpoint :
http://www.zdnet.fr/actualites/comment-3d-xpoint-d-intel-transformera-les-serveurs-et-le-stockage-39839122.htm
Ce que vous appelez choix ne sont en fait que des limitations montrant bien l’incapacitĂ© de PostGreSQL Ă effectuer ceci ou cela. Par exemple, pour le stockage, toujours pas capable de faire des espaces de stockage « read only » et plus dramatique, la possibilitĂ© de supprimer un fichier de la base sans que jamais une erreur ne soit remontĂ©e aux clients connectĂ©s ! Autre exemple, sur les transactions, impossible de faire des transactions « partielles » ou « imbriquĂ©es »… Et votre commentaire sur l’absence de tag de requĂŞtes est parfaitement malhonnĂŞte, car cela existe bien dans la version payante. Ainsi lorsque vous ĂŞtes piĂ©gĂ©s par l’optimiseur (qui dĂ©conne sĂ©rieusement dès que l’on dĂ©passe les 12 jointures – limite geqo) il vous faut passer Ă la version payante Entreprise DB qui coĂ»te un bras ! (seriez vous sponsorisĂ©s par ces derniers ?
Sur l’indexation, les index GIN et GIST sont assez mauvais comparĂ©es aux autres solutions mises en Ĺ“uvre dans les autres SGBDR… Et pour ne citer que SQL Server nous avons les index suivants : Btree simple, clustered et couvrant (include), columnstore simples et clustered, index spatiaux, index XML, soit 7 types d’index…
Il est vrai que le parallĂ©lisme vient d’arriver, mais c’est tellement embryonnaire, qu’aucune des requĂŞtes que j’ai en production chez les clients qui ont migrĂ© n’en ont encore bĂ©nĂ©ficiĂ© !
Le coĂ»t des outils d’administration est une chose. Le coĂ»t de l’administration elle-mĂŞme en est une autre. Lorsqu’il faut passer trois heures sur une requĂŞte PostGreSQL parce que l’outil n’existe pas (par exemple le diagnostic automatique d’indexation) c’est beaucoup de temps perdu et le temps c’est de l’argent…
Pourvoir savoir quelles sont les requĂŞtes en cours est indispensable dans certaines cas, notamment lorsque le serveur est trop chargĂ© afin de diagnostiquer en live les causes de blocage, attentes, etc. Et de pouvoir tuer l’une des sessions afin de libĂ©rer les autres, plutĂ´t que de devoir arrĂŞter le serveurs et par le fait de tuer toutes les sessions !
Le fait de faire des sauvegardes est une chose, les faire vite et bien est une autre chose. PostGreSQL est très très lent comparativement à Oracle ou SQL Server !
TOAST ne compresse que les LOBs ce qui n’offre que peu d’intĂ©rĂŞt. La compression des donnĂ©es relationnelles comme celle des index est fondamentale notamment pour la dataWarehousing !
Vous confondez rĂ©plication de donnĂ©es (c’est Ă dire la facultĂ© de propager certaines donnĂ©es de certaines lignes de certaines tables d’une base Ă une autre) et haute disponibilitĂ© qui est la rĂ©plication de l’intĂ©gralitĂ© de la base. Et mĂŞme dans ce dernier cas PostGreSQL est assez mauvais, car par exemple il ne sait pas propager certaines donnĂ©es afin d’Ă©viter des divergences de donnĂ©es ! L’exemple typique est l’UUID (ou GUID) ou l’horodatation. En effet au lieu de rĂ©pliquer la donnĂ©, PostGreSQL rĂ©plique souvent la commande, produisant une divergence des donnĂ©es dans les bases, rendant fonctionnellement inexploitable les rĂ©plicas !
Enfin, vos exemples avec Skype et Le bon coin me font doucement marrer… Il y a belle lurette que Skype a abandonnĂ© PostGreSQL avant mĂŞme son rachat par Microsoft ! Quand au bon coin, il utilise plus de 100 serveurs PostGreSQL pour partager la base car elle est trop grosse pour tenir sur un seul et il faut arrĂŞter la nuit tous les serveurs pour la maintenance ! Bref, un coĂ»t exorbitant, lĂ ou un seul serveur Oracle ou SQL Server aurait suffit !
Bonjour
Qu’en est t’il en 2016 des lacunes de POSTGRES par rapport Ă ORACLE ?
Merci de vos réponses
Voici quels sont les points depuis la version 9.6 de PostGreSQL :
point 1 Ă 5 toujours valables
Point 6, il existe une solution embryonnaire de vues matérialisées
Point 7, le parallélisme des requêtes est arrivé avec la version 9.6 il est cependant très rudimentaire.
Il faut prĂ©ciser Ă la main le degrĂ© de parallĂ©lisme (set max_parallel_degree) et certaines conditions empĂŞchent un plan parallèle (requĂŞtes d’Ă©criture INSERT, UPDATE ou DELETE, requĂŞtes de curseur, transaction serializable, dynamic_shared_memory_type mis Ă « none »…) de plus la parallĂ©lisation ne concerne que certaines Ă©tapes du plan essentiellement les « scans » de tables et limitĂ©s par certaines conditions;
La conclusion est qu’il faudra rĂ© Ă©crire les requĂŞtes pour en tirer partie en indiquant, avant de lancer la requĂŞte, le degrĂ© de parallĂ©lisme souhaitable, lĂ ou Oracle ou SQL Server le font de manière automatique sans devoir rĂ©crire les requĂŞtes !
Il ne concerne pas, bien entendu et hélas, les outils de maintenance tels que VACUMM ou CLUSTER ce qui est bien dommage car permettrais de restreindre les temps de traitement des tâches de maintenance
Point 8 Ă 11 : toujours valables
Point 12 : il existe un module externe de chiffrement nommĂ© pg_crypto peu sĂ©curisĂ© : pas de salage automatique, clĂ© devant ĂŞtre prĂ©sente suer le serveur sous forme de fichier….
Point 13 : toujours valable
Les lacunes sont t’elles encore justifiĂ©es en 2016 avec les dernieres versions de POSTGRE ?
Bonjour
Ou en sommes nous en 2016, avec la version 9.5.4 de POSTGRES ? Ces laqunes persiste t’elles ?
Merci
Enfin du constructif !
Bonjour,
Dimitri Fontaine SEO de 2ndQuadrant, SociètĂ© spĂ©cialisĂ© dans les outils PostgreSQL, nous propose un droit de rĂ©ponse Ă l’article de FrĂ©dĂ©ric Brouard.
Droit de RĂ©ponse : http://expert-postgresql.fr/blog/news/migrer-a-postgresql/
En vous remerciant tous de cet Ă©change constructif.
MaitrePylos.
Super article. Bravo.
Ci joint les commentaires de scheu postĂ©s Ă l’origine dans ce message
Quelques retours d’expĂ©rience personnels qui peuvent Ă©ventuellement complĂ©ter ton article si tu les juges utiles :
Paragraphe 4 (hints)
Effectivement le fait que les hints soient intĂ©grĂ©s dans la version payante laisse Ă penser que jamais la version communautaire gratuite de Postgresql ne les intègrera jamais, au grand regret des DBA …
La seule marge de manoeuvre quand un plan d’exĂ©cution est mauvais se situe au niveau des paramètres du serveur (enable_mergejoin, enable_nestloop, enable_seqscan, …) que l’on peut modifier dans le SQL, ou par login Postgresql.
Par exemple si une requĂŞte fait un nested loop alors que c’est contre-performant comparĂ© Ă un hash join, on peut faire avant la requĂŞte un « set enable_nestloop to off »
Bien que parfois mĂŞme en modifiant ces paramètres ça n’empĂŞche pas tel ou tel type d’opĂ©ration …
Mais ça doit rester exceptionnel, car ça devient vite une usine à gaz si on modifie ces paramètres spécifiquement pour chaque requête
== Citation SQLpro ==
Or la philosophe particulièrement croustillante des dĂ©veloppeurs de PG est que c’est très mal de mettre des tags dans les requĂŞtes : « Why PostgreSQL Doesn’t Have Query Hints »
Dans un monde parfait, cela serait absolument gĂ©nial… Mais malheureusement il y a la rĂ©alitĂ©, et lĂ force est de constater que l’optimisation des requĂŞtes par PostGreSQL est loin d’ĂŞtre… optimale !
== fin citation ==
Tout-Ă -fait d’accord avec toi
Autant sur des applications dĂ©veloppĂ©es « maison » on peut Ă©ventuellement chercher Ă modifier le SQL pour optimiser (et encore, ce n’est pas toujours simple), autant quand on a Ă faire Ă un progiciel dont nous n’avons pas la main pour modifier les requĂŞtes, c’est impossible.
Et quand un plan d’exĂ©cution pourri arrive du jour au lendemain en production et qu’on demande au DBA de trouver une « rustine » rapide, c’est souvent mission impossible et on regrette de ne pas ĂŞtre sur Oracle ou SQL Server
Paragraphe 5 (optimiseur)
Ca arrive encore trop souvent que les plans d’exĂ©cution soient pourris sur Postgresql (mĂŞme avec des stats Ă jour et des indexes bien placĂ©s) dès qu’on a des requĂŞtes un peu complexes (jointure entre 6-7 tables, auto-jointures, sous-jointures, …), ou comportant trop de colonnes filtrĂ©es sur les tables
Le principal dĂ©faut est qu’il sous-estime trop souvent les cardinalitĂ©s (nombre de lignes retournĂ©es Ă chaque Ă©tape du plan), ce qui conduit au bout d’un moment :
– soit Ă lui faire choisir des « nested loop » au lieu de « hash join » en cas de jointure
– soit Ă des « index range scan » trop coĂ»teux alors qu’un full scan de la table serait au final meilleur
Je pense que ce problème est lié au fait que Postgresql sait très mal évaluer les nombres de lignes retournés pour des filtres qui comportent plusieurs colonnes
Là où Oracle ou SQL Server, sur un index (col1,col2,col3), sait faire des stats dessus et savoir estimer, pour chaque valeur du triplet, le nombre de lignes dans la table, Postgresql ne sait le faire que dans de très rares cas, les histogrammes se limitant sur des colonnes uniques et pas des t-uples
Paragraphe 10 (plans d’exĂ©cution)
Oui, tu ne peux que les voir une fois que la requĂŞte est exĂ©cutĂ©e, et encore ce n’est pas en natif, il faut utiliser pour cela la contrib « auto_explain » qui permet de les rĂ©cupĂ©rer dans la trace du serveur Postgresql, mĂŞme si ce n’est pas toujours lisible facilement et qu’il faut souvent reformater le fichier Ă la main
Autre (spécificité Oracle)
Concernant la migration de Oracle vers PG (je ne connais pas suffisamment bien SQL Server pour comparer) : tu pourrais aussi éventuellement rajouter un paragraphe sur les principales différences de comportement entre Oracle et Postgresql quand on fait une migration en laissant les paramètres par défaut des 2 côtés, notamment :
– mode « autocommit » par dĂ©faut sur Postgresql
– gestion des NULL diffĂ©rentes (sous Oracle, NULL = chaĂ®ne de caractères vide, mais pas sous PG, donc diffĂ©rences de comportement d’une mĂŞme requĂŞte)
– conversions de type implicites qui passent sous Oracle mais pas sous PG (test des requĂŞtes d’une appli et rĂ©Ă©criture Ă©ventuelle Ă prĂ©voir)
– syntaxe des jointures ouvertes (+) spĂ©cifique Ă Oracle
– sous PG, mot clĂ© « AS » obligatoire pour renommer les colonnes dans une requĂŞte SQL
– pas de synonymes ni de packages sous PG
– type « date » de Oracle = type « timestamp » de Postgresql
– ordre de tri diffĂ©rente selon la casse
– PG sensible Ă la casse sur les noms d’objets
== Citation SQLpro ==
Vous comprendrez que prĂ©senter PostGreSQL comme une alternative crĂ©dible Ă Oracle ou mĂŞme SQL Server sur des bases Ă forte volumĂ©trie, important trafic ou grande concurrence et est un phantasme de nerd mais est loin d’ĂŞtre une rĂ©alitĂ© !
Soyons modeste pour ne pas avoir de couteuses déconvenues et évitons les dogmes.
Je sais qu’en rĂ©digeant un tel article je vais m’attirer les foudres de nombreux internautes. Je m’y attend et reste serein. J’ai des arguments et une expĂ©rience acquise depuis plus de 20 ans par mon travail avec de nombreux SGBDR…
Mais je sais hĂ©las que, chez certains, la passion du libre l’emporte souvent contre la raison du technique !
== Fin citation ==
Je suis assez d’accord avec toi.
Postgresql a depuis quelques versions de nombreuses fonctionnalitĂ©s qui se rapprochent des besoins des entreprises (hot standby, sauvegarde Ă chaud en continu, fonctions analytiques, …)
Au jour d’aujourd’hui Postgresql peut faire l’affaire pour des petites applications non critiques, Ă faible volumĂ©trie (quelques dizaines de Go) et Ă faible complexitĂ© (pas de grosses requĂŞtes faisant des jointures sur plus de 5-6 tables)
Mais dès qu’on arrive dans des environnements complexes, volumineux ou critiques, Postgresql montre quand-mĂŞme ses limites, et ça peut vite devenir critique quand par exemple (c’est du vĂ©cu) un problème de mauvais plan d’exĂ©cution survient en production, la requĂŞte vous mange 100% de CPU et dure 15 heures, et qu’aucune rustine rapide n’est envisageable
C’est toujours le compromis Ă trouver entre budget et risque pour une entreprise …
Oohhh FrĂ©dĂ©ric, tu as encore « commis » un article polĂ©mique… bon courage pour les comentaires :-p