Dans le cadre d’un hĂŠritage de donnĂŠes ayant de multiples enfants aux caractĂŠristiques très diverses, est-il prĂŠfĂŠrable de concevoir un modèle de donnĂŠes gĂŠnĂŠrique ou un modèle de donnĂŠes spĂŠcifique ? De nombreux jeunes dĂŠveloppeurs pensent naĂŻvement qu’un modèle gĂŠnĂŠrique est plus facile… Mais c’est souvent une erreur qu’il faudra payer au prix fort une fois l’application fonctionnelle. DĂŠmonstration…
Je suis partit initialement de ce post :
Avis sur l’architecture de ma base de donnĂŠes (choix de l’option)
La demande ĂŠtant la suivante :
J’ai 30 familles de critères. Chaque famille comporte un nombre variable de critères pour un total d’environ 600 critères.
Chaque critère appartient à une seule famille de sorte que les 600 sont à rÊpartir dans les 30 familles.
Ma question:
– devrais-je crĂŠer une table par famille et insĂŠrer dans chaque table les critères qui lui appartiennent; (solution 1)
ou alors:
– crĂŠer une table contenant les 30 familles et une autre contenant les 600 critères. Ensuite, crĂŠer les relations qui lient chaque famille Ă ses critères et/ou inversement. (solution 2)
et ma rĂŠponse :
Pour qu’une base rĂŠponde bien en terme de performances, on doit tout faire pour minimiser les IO.
– Dans votre solution 1, les performances seront bonne si la plupart des requĂŞtes portent sur plusieurs critères d’une mĂŞme famille
– Dans votre solution 2, les performances seront bonne si la plupart des requĂŞtes portent sur un seul critère.
Cependant un jeune internaute peu avisĂŠ, affirmait avec force que :
pour moi la solution 2 est la + simple Ă mettre en place.
et le nombre d’enregistrements ne justifie pas la solution 1..
tout dĂŠpend de votre SGBD (pas prĂŠcisĂŠ..), mais dans tous les cas, il suffit de mettre des ID numĂŠrique pour que les requĂŞtes soient optimisĂŠes. CrĂŠez vos tables avec des id uniques (sous Oracle on peux utiliser les sĂŠquences) et vous aurez des traitements optimisĂŠes au mieux… mais bon, je vous rassure, sous Oracle, mĂŞme avec des clefs en Varchar, pour 600 enregistrements, y a aucun pb..
si je vois bien, vous aurez donc 3 tables avec les clef suivante :
– FAMILLE (Pk : ID_FAMILLE)
– FAMILLE_CRITERE (Pk : ID_FAMILLE, ID_CRITERE)
– CRITERE (Pk : ID_CRITERE)
Relations :
¤ Famille –> FAMILLE_CRITERES <— CRITERE
famille_critere ne contenant que le couple ID_FAMILLE, ID_CRITERE (on parle de table intermĂŠdiaire)
Ce Ă quoi je rĂŠpondais :
La solution 2 est correcte si vous ne requĂŞtez JAMAIS plus d’un critère Ă la fois. Elle est dĂŠjĂ moins performante Ă lâinsertion/la mise Ă jour des donnĂŠes…
La solution 2 est imbĂŠcile, complexe et peu performantes si vous avez plusieurs critères a rechercher…
En sus, elle ne permet pas facilement de typer les informations, donc, vous aurez beaucoup de problĂŠmatique de contrĂ´le de qualitĂŠ… et des performances catastrophiques
DĂMONSTRATION
Partons d’une table d’animaux :
(ANM_ID INT PRIMARY KEY,
ANM_DATA CHAR(8000) NOT NULL);
GO
INSERT INTO T_ANIMAL_ANM VALUES (1, 'Mytilus Edulis')
â â â 1ere solution : une seule table pour toute une mĂŞme famille :
(ANM_ID INT PRIMARY KEY REFERENCES T_ANIMAL_ANM (ANM_ID),
MSQ_CARAPACE VARCHAR(32),
MSQ_SYMETRIE VARCHAR(32),
MSQ_COULEUR VARCHAR(32),
MSQ_DIAMETRE_MM FLOAT);
â â â 2e solution (pour toutes familles), des tables « gĂŠnĂŠriques » :
(CRT_ID INT PRIMARY KEY,
CRT_LIBELLE VARCHAR(256));
(ANM_ID INT NOT NULL REFERENCES T_ANIMAL_ANM (ANM_ID),
CRT_ID INT NOT NULL REFERENCES T_CARATERISTIQUE_CRT(CRT_ID),
VLR_VALEUR VARCHAR(256),
PRIMARY KEY (ANM_ID, CRT_ID));
Ajoutons les caractĂŠristiques identiques Ă celle de la solution 1
INSERT INTO T_CARATERISTIQUE_CRT VALUES (222, 'SymĂŠtrie');
INSERT INTO T_CARATERISTIQUE_CRT VALUES (333, 'Couleur');
INSERT INTO T_CARATERISTIQUE_CRT VALUES (444, 'Diamètre mm');
â â â Voici maintenant les insertions :
Pour la solution 1 :
VALUES (1, 'Creatine', 'Mono', 'Bleu', '82.5')
Notez que nous n’avons fait qu’une seule requĂŞte d’insertion avec correspondance caractĂŠristique / valeur et typage des donnĂŠes
Pour la solution 2 :
SELECT 1, CRT_ID, 'Creatine' FROM T_CARATERISTIQUE_CRT
WHERE CRT_LIBELLE = 'Carapace';
INSERT INTO T_VALEUR_VLR
SELECT 1, CRT_ID, 'Mono' FROM T_CARATERISTIQUE_CRT
WHERE CRT_LIBELLE = 'SymĂŠtrie';
INSERT INTO T_VALEUR_VLR
SELECT 1, CRT_ID, 'Bleu' FROM T_CARATERISTIQUE_CRT
WHERE CRT_LIBELLE = 'Couleur';
INSERT INTO T_VALEUR_VLR
SELECT 1, CRT_ID, '82,5' FROM T_CARATERISTIQUE_CRT
WHERE CRT_LIBELLE = 'Diamètre mm';
Pour stocker les mĂŞmes informations, nous avons fait 4 requĂŞtes au lieu d’une seule….
â Comparons maintenant le coĂťt des 2 solutions au niveau de l’insertion :
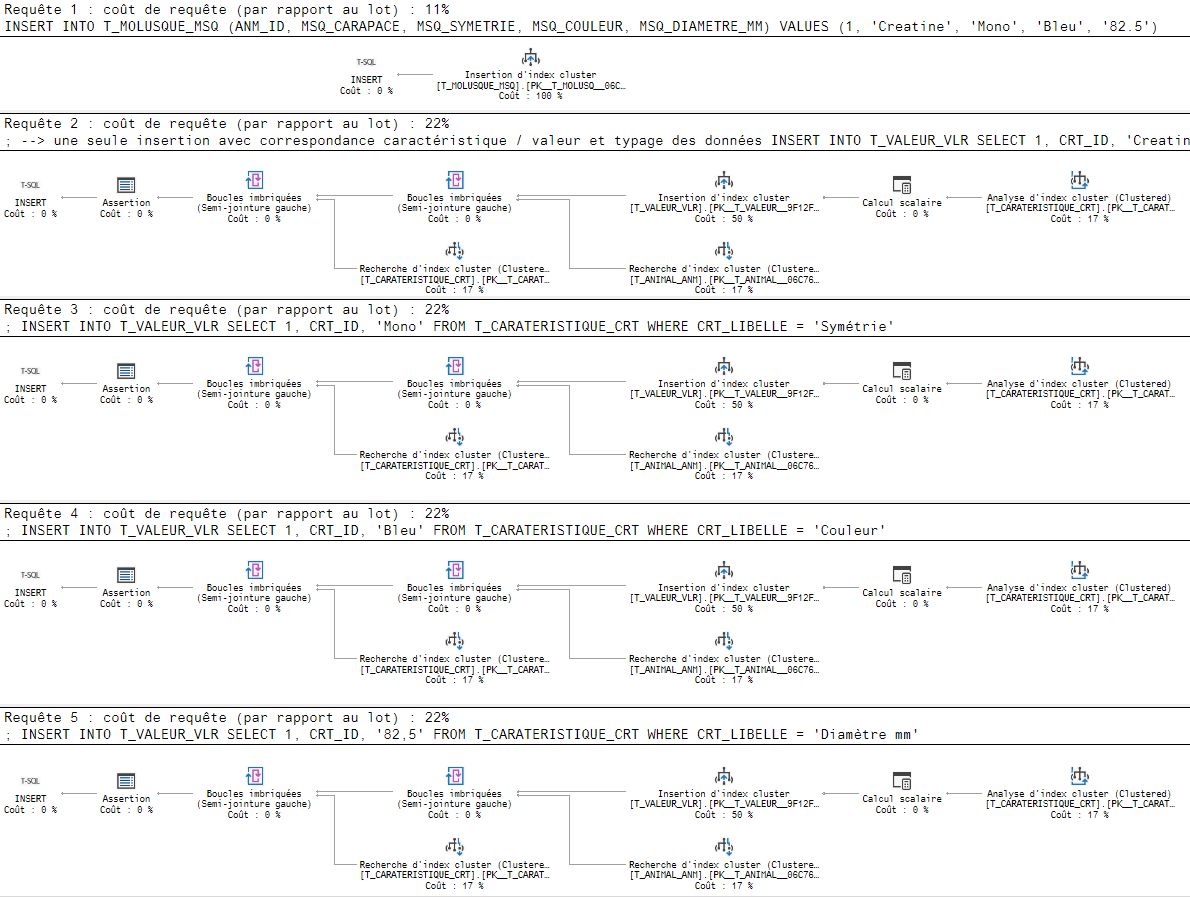
Y’a pas Ă tortiller 4 requĂŞtes coutant deux fois plus cher qu’une seule et unique requĂŞte cela est donc 8 fois plus couteux…
â â â Voyons maintenant la facilitĂŠ de requĂŞtage :
interrogation multicritères ET avec solution 1
FROM T_ANIMAL_ANM AS A
JOIN T_MOLUSQUE_MSQ AS M
ON A.ANM_ID = M.ANM_ID
WHERE MSQ_CARAPACE = 'Creatine'
AND MSQ_SYMETRIE IN ('Mono', 'Double')
AND MSQ_COULEUR LIKE 'Bleu%' --> peut ĂŞtre Bleue, Bleu-marine...
AND MSQ_DIAMETRE_MM BETWEEN 75 AND 92;
la requĂŞte fait 8 lignes et 1 jointure. Elle en fera une de plus pour chaque critère supplĂŠmentaire avec juste quelques chose Ă rajouter Ă la clause WHERE…
interrogation multicritères ET avec solution 2
FROM T_ANIMAL_ANM AS A
JOIN T_VALEUR_VLR AS V1
ON A.ANM_ID = V1.ANM_ID
JOIN T_CARATERISTIQUE_CRT AS C1
ON V1.CRT_ID = C1.CRT_ID
JOIN T_VALEUR_VLR AS V2
ON A.ANM_ID = V2.ANM_ID
JOIN T_CARATERISTIQUE_CRT AS C2
ON V2.CRT_ID = C2.CRT_ID
JOIN T_VALEUR_VLR AS V3
ON A.ANM_ID = V3.ANM_ID
JOIN T_CARATERISTIQUE_CRT AS C3
ON V3.CRT_ID = C3.CRT_ID
JOIN T_VALEUR_VLR AS V4
ON A.ANM_ID = V4.ANM_ID
JOIN T_CARATERISTIQUE_CRT AS C4
ON V4.CRT_ID = C4.CRT_ID
WHERE C1.CRT_LIBELLE = 'Carapace'
AND V1.VLR_VALEUR = 'Creatine'
AND C2.CRT_LIBELLE = 'SymĂŠtrie'
AND V2.VLR_VALEUR IN ('Mono', 'Double')
AND C3.CRT_LIBELLE = 'Couleur'
AND V3.VLR_VALEUR LIKE 'Bleu%'
AND C4.CRT_LIBELLE = 'Diamètre mm'
AND V4.VLR_VALEUR BETWEEN '75' AND '92'
La requĂŞte fait 26 lignes avec 8 jointures… Il faudra rajouter 6 lignes Ă chaque critère supplĂŠmentaire, dont 4 dans la clause FROM et 2 dans le WHERE, et encore, on ne sait pas dans la clause SELECT Ă quelle caractĂŠristique se rĂŠfère chacune des valeurs… Il faudrait aussi customiser la clause SELECT…
Y’a pas Ă tortiller la solution 1 est bien plus simple en matière dâĂŠcriture…
â Quelles sont les performances des requĂŞtes de recherches des deux solutions ?

Ăvidemment la première solution est 4,5 fois moins couteuse…
Mais il y a pire… J’ai du mettre des chiffres en chaine de caractères pour le diamètre (AND V4.VLR_VALEUR BETWEEN ’75’ AND ’92’). Si je tente de les typer en entier ou rĂŠel (AND V4.VLR_VALEUR BETWEEN 75 AND 92), cela provoque une erreur d’exĂŠcution (SQL Server) :
Msg*245, Niveau*16, Ătat*1, Ligne*75
Ăchec de la conversion de la valeur varchar ‘Creatine’ en type de donnĂŠes int.
Logique car pour effectuer une comparaison avec une valeur numÊrique, il faut convertir la colonne en numÊrique, mais comme il y a autres chose que de purs nombres (chaines de caractères) cela se passe mal.
Bref certaines requĂŞtes seront impossible Ă faire !
Plus catastrophique encore… mettre des index ne servira quasiment Ă rien ! En effet un index sur une chaine de caractères nâordonne pas les valeurs de la mĂŞme façon que s’il s’agissait de nombre…
En sus rien n’interdira Ă quelquâun de saisir 8,2 au lieu de 8.2 (une virgule au lieu d’une point) comme diamètre, dans ce modèle inepte, alors qu’avec le bon modèle les types sont respectĂŠs…. Si tel ĂŠtait le cas, la valeur ne pourra pas ĂŞtre retrouvĂŠe !!! Il existe bien ĂŠvidemment une solution pour contourner, un tout petit peu, ce modèle pourri, pour le typage. Il consiste Ă rajouter autant de tables de valeurs que de type… Mais il n’est pas possible de rajouter des contraintes spĂŠcifique Ă chaque type (par exemple vĂŠrifier qu’une pourcentage est bien entre 0 et 100 – notion de domaine SQL), ni, bien entendu, de rajouter des contraintes multicritères (une valeur dĂŠpendant d’une autre) comme c’est le cas par exemple de la chronologie des temporels de type « dĂŠbut » et « fin ».
Et dans tous les cas, les requĂŞtes seront encore plus complexes Ă ĂŠlaborer et les performances encore plus lamentables…
En guise de conclusion
Nous vous avons dĂŠmontrĂŠ les performances lamentable et la complexitĂŠ horrifiante d’un tel modèle….
Mais comment se fait-il que des internautes osent affirmer de pareilles stupiditĂŠs ?
Il est amusant de voir que certains dĂŠveloppeur incultes affirment n’importe quoi, par ignorance, ou par bĂŞtise, ne prenant mĂŞme pas la peine de tester ce qu’ils disent… Ensuite ces mĂŞmes dĂŠveloppeurs, sans aucune expĂŠrience, iront vous raconter que les SGBDR c’est pas performant… Ils vous vendrons alors du NoSQL, ce qui, dans beaucoup de cas, sera pire encore !
Comme disent les amĂŠricains : « garbage in, garbage out » qui peut se traduire si tu fais de la merde en entrĂŠe, tu auras de la merde en sortie ! Autrement dit, si le modèle de donnĂŠes est inepte, la qualitĂŠ des donnĂŠes sera pourrie et les performances lamentables…
DĂŠcortiquons d’ailleurs les affirmations de l’internate que nous avons citĂŠ :
« tout dĂŠpend de votre SGBD (pas prĂŠcisĂŠ..), mais dans tous les cas, il suffit de mettre des ID numĂŠrique pour que les requĂŞtes soient optimisĂŠes. CrĂŠez vos tables avec des id uniques (sous Oracle on peux utiliser les sĂŠquences) et vous aurez des traitements optimisĂŠes au mieux… mais bon, je vous rassure, sous Oracle, mĂŞme avec des clefs en Varchar, pour 600 enregistrements, y a aucun pb.. »
Première affirmation stupide : « tout dĂŠpend de votre SGBD (pas prĂŠcisĂŠ..) »
Comme nous sommes dans un forum sur les SGBDR, sachez cher monsieur, que tout les SGBDR fonctionnent de la mĂŞme façon. Certains allant plus vite que d’autre (une Ferrari va gĂŠnĂŠralement plus vite qu’une Peugeot), certains avec plus de qualitĂŠ que d’autres (une Rolls-Royce est gĂŠnĂŠralement de meilleure qualitĂŠ qu’une Dacia).
Seconde affirmation stupide : « il suffit de mettre des ID numĂŠrique pour que les requĂŞtes soient optimisĂŠes »
Si c’ĂŠtait le cas alors, pas besoin d’index ni de contraintes… On se demande donc pourquoi les ĂŠditeurs de SGBDR font de tels effort en R&D pour trouver de nouvelles formes d’index toujours plus performant… Et la plupart des informaticiens ignorent que les contraintes permettent de mieux optimiser les plans de requĂŞte… HĂŠlas ceci est très rarement enseignĂŠ par les professeurs des universitĂŠs et encore moins ceux des ĂŠcoles d’ingĂŠnieurs… (je le sais pertinemment puisque j’en ĂŠtais un…).
Troisième affirmation stupide : « mais bon, je vous rassure, sous Oracle, mĂŞme avec des clefs en Varchar »
Et bien, non, plus une clef est longue en nombre d’octets, plus ses performances dĂŠcroissent. Pour avoir la mĂŞme longueur qu’un entier auto incrĂŠmentĂŠ il faudrait se limiter Ă 4 caractères… En sus certaines phĂŠnomènes apparaissent avec des clefs non numĂŠriques et en particulier pour des clefs littĂŠrales :
Quatrième affirmation stupide : « sous Oracle, mĂŞme avec des clefs en Varchar, pour 600 enregistrements, y a aucun pb.. »
Nous avons dĂŠjĂ dit prĂŠcĂŠdemment que les clef littĂŠrales (VARCHAR) ĂŠtaient une plaie… Mais ce qui ne va pas dans cette phrase est le terme « enregistrement« … Cet internaute sait-il au moins que les SGBDR ne travaillent pas avec des « enregistrement » propre aux bases de donnĂŠes de type « fichier » comme c’ĂŠtait las cas dans les annĂŠes 50 Ă 70 ? Les SGBDR structurent les lignes des tables dans des pages qui sont modifiĂŠes en mĂŠmoire et non pas directement sur le disque (notion physique d’enregistrement). Les pages ĂŠtant physiquement ĂŠcrites de temps Ă autres quand il y en a suffisamment Ă ĂŠcrire par un processus asynchrone travaillant en tâche de fond.
Bref voici q’un internaute ne connaissant ni la modĂŠlisation des donnĂŠes ni les technologies des SGDB, vient donner des conseils stupides hĂŠlas parfois repris dans certaines applications….
CQFD
Expert S.G.B.D relationnelles et langage S.Q.L
Moste Valuable Professionnal Microsoft SQL Server
SociĂŠtĂŠ SQLspot : modĂŠlisation, conseil, formation,
optimisation, audit, tuning, administration SGBDR
Enseignant: CNAM PACA, ISEN Toulon, CESI Aix en Prov.
L’entreprise SQL Spot
Le site web sur le SQL et les SGBDR
![]()
Bonjour,
Est-ce que dans ce genre de situations l’hĂŠritage de table (disponible dans PostgreSQL) ne rend pas encore plus simple la mise en place d’un modèle spĂŠcifique ?
Bien Cordialement
Bonjour,
Merci pour ce billet.
Cependant je trouve que certains aspect ne sont pas couvert par celui-ci. En consĂŠquence de quoi, il ne peux ĂŞtre une rĂŠponse absolue Ă cette problĂŠmatique de modĂŠlisation / conception.
Je m’explique, la solution prĂŠconisĂŠe ici prĂŠsuppose un modèle figĂŠ dans le temps, sans ajout de critère, ce qui peut poser un problème d’usage de l’outil qui s’appuiera sur un tel modèle. Vous me direz qu’il est tout Ă fait possible d’ajouter une colonne Ă la table cible par le biais de ce mĂŞme outils, mais nous crĂŠons alors un problème de qualification de la donnĂŠes en dĂŠlĂŠguant Ă l’utilisateur final une opĂŠration dont il ne maĂŽtrise pas, Ă priori, les tenants et aboutissants.
En sommes, la solution n’est pas aussi simple que vous semblez le dĂŠcrire en restant essentiellement sur la thĂŠorie des modèles, lĂ oĂš ce que vous appelez, avec peu de courtoisie, dĂŠveloppeur incultes affirmant nâimporte quoi, par ignorance, ou par bĂŞtise, sont confrontĂŠ Ă la vie concrète, et que les entreprises essentiellement TPE / PME n’ont pas les moyens d’avoir un informaticien Ă demeure.
Pour conclure, je pense que le constat est bon que la rĂŠponse apportĂŠ est bien sur valable pour ce cas prĂŠcis et dans la thĂŠorie des modèles, mais qu’il n’apporte pas une rĂŠponse complète Ă la problĂŠmatique qu’il prĂŠtend rĂŠsoudre.
Dans l’attente de vous lire,
Cordialement
Belle dĂŠmonstration Fred, avec le style qu’on te connait
Je ne peux que plussoyer, je suis d’ailleurs intervenu chez un client pourtant très connu (une banque très cĂŠlèbre) dont l’outil fraĂŽchement dĂŠveloppĂŠ par une SSII a fonctionnĂŠ… 10 jours avant que les performances (plusieurs dizaine de secondes, voir plus d’une minute) dramatiques nĂŠcessite mon intervention…
Et pourtant la base ne faisait en tout et pour tout que… 60 mo!
C’est article rĂŠsonne comme un WARNING contre lâimprovisation. La diffĂŠrence dĂŠmontrĂŠe entre les 2 solutions est un cris d’alarme, une puce Ă l’oreille dans l’oreille d’entrepreneurs qui nĂŠcessitent d’applications Ă dĂŠvelopper. En simple analyse le choix entre les deux solutions peut sembler ĂŠquivalent. L’article dĂŠmontre bien le contraire. Une des solutions constitue une grave erreur de conception Ă ĂŠviter. Combien de pièges sont-ils parsemĂŠs sur le cheminement de la conception d’une base de donnĂŠes? J’imagine que la remĂŠdiation de la contre-performance d’une architecture de base de donnĂŠes provoque un coĂťt rĂŠcurrent qui peut ĂŞtre soit prĂŠvenu (consultation spĂŠcialisĂŠe) soit stoppĂŠ (analyse du cas).