La plupart des d├®veloppeurs sont persuad├®s que mettre toutes les informations dans une m├¬me table rendra leur base de donn├®es plus rapide… Et l’on voit appara├«tre dans la base de nombreuses tables de plusieurs dizaines de colonnes. C’est une vue ├Ā court terme, car d├©s que la base de donn├®es commence ├Ā croitre ou que le nombre d’utilisateur augmente, les performances deviennent vite catastrophique… Cet article explique pourquoi…
├Ć chaque audit que je fais, et cela depuis maintenant plus de 15 ans, on trouve r├®guli├©rement la m├¬me erreur : des tables avec un nombre effrayant de colonnes. Par exemple une table des personnes, dans laquelle on trouve des adresses, des t├®l├®phones, des mails, … bref tout un tas d’information relatif ├Ā une personne, mais qui ne constitue aucunement des attributs directs de la personne. Et chaque fois que l’on fait remarquer cela aux d├®veloppeurs, la r├®ponse est la m├¬me :
- « on m’a dit que les jointures c’├®tait mal »
- « les jointures c’est pas performants, c’est connu »
- « Je mets tout dans la m├¬me table, ├¦a ira plus vite »
…
Bien ├®videmment, c’est tout le contraire, mais pour le comprendre il faut revenir ├Ā ce qu’est une base de donn├®es relationnelle, comment fonctionne les SGBDR client/serveur et ce qu’est la normalisation d’un mod├©le de donn├®es, c’est ├Ā dire son d├®coupage en de multiples tables, chacune ├®tant bien sp├®cialis├® et concentr├® sur l’objet qu’elle mod├®lise.
Types de donn├®es et forme normale
Le choix des types de donn├®es, la ma├«trise de la qualit├® des donn├®es et le respect des formes normales repr├®sente, lorsqu’on ne les met pas en ┼ōuvre, plus de 70% des probl├©mes de performance. Mais l├Ā o├╣ c’est pervers, c’est que le d├®veloppeur ne s’en rendra compte que trop tard, lorsque apr├©s plusieurs mois, voire plusieurs ann├®es de production, le volume de la base de donn├®es d├®passant largement celui de la RAM du serveur, les performances deviennent catastrophiques…
J’ai vu plusieurs ├®diteurs en situation de quasi faillite apr├©s avoir vendu leur logiciel avec une base mal mod├®lis├®e ├Ā leur premier gros client. Le sc├®nario est g├®n├®ralement le suivant : apr├©s plusieurs semaines d’exploitation, les temps de r├®ponses ├®tant d├®j├Ā mauvais, le client intime ├Ā l’├®diteur de trouver une solution. Comme il n’y a pas de silver boulette (comme disent nos amis am├®ricains) et que tout red├®velopper est g├®n├®ralement inenvisageable, on patch quelques petits ├®l├®ments ├Ā droite ├Ā gauche pour gagner du temps… Au bout de quelques mois, le client s’impatiente et menace de ne pas payer… Et finalement c’est ce qu’il fait car rien ne vient !
Normaliser une base de donn├®es
La normalisation d’une base de donn├®es (c’est-├Ā-dire le respect des r├©gles de mod├®lisation) n’est pas une figure de style. C’est, avant tout, une question de performance !
Par exemple le viol de la notion d’atomicit├® (premi├©re forme normale), c’est ├Ā dire mettre plusieurs informations dans une m├¬me colonne est une erreur aux cons├®quences lourdes. Elle conduira t├┤t ou tard ├Ā des tables ob├©ses et des acrobaties pour ├®crire des requ├¬tes qui ne pourront jamais ├¬tre optimis├®es.
Je donne souvent les exemples suivants :
« mod├®lisez moi une adresse IP, mod├®lisez moi un n┬░ de s├®curit├® sociale » (bien entendu ces demandes sont « noy├®es » dans un exercice plus g├®n├®ral de mod├®lisation)….
La plupart du temps les d├®veloppeurs mod├®lisent une adresse IP sous la forme d’une chaine de caract├©res de longueur maximale 15.
L├Ā je leur demande de saisir quelques adresses IP et je leur demande d’├®crire la requ├¬te suivante :
« Trouvez-moi les ordinateurs aff├®rent au masque de sous r├®seau de classe C »
Et l├Ā c’est la panique… Lorsque la requ├¬te est ├®crite (ce qui est rarement arriv├®e…) elle est catastrophiquement lente du fait de multiples fonctions. C’est ├Ā ce moment que le d├®veloppeur me dit que cela aurait ├®t├® mieux s’il avait mod├®lis├® cette adresse IP avec 4 entiers.
Parfait lui dis-je…
├Ć ce moment-l├Ā, je lui demande de me dire comment traiter les adresses IP V6 !
Pour le num├®ro de s├®curit├® sociale, c’est le m├¬me tabac. La plupart du temps les d├®veloppeurs me mettent deux zones de saisie : une de 13 caract├©res et l’autre de 2 pour la clef.
Maintenant je leur demande de me dire comment ils vont contr├┤ler la saisie sachant que le premier caract├©res doit ├¬tre un 1 ou 2 , les 2 second de 00 ├Ā 99, les 2 d’apr├©s de 01 ├Ā 12, etc.
Puis je leur demande de m’├®crire une requ├¬te pour trouver toutes les personnes du sexe masculin n├®e dans les ann├®es 60 en r├®gion parisienne…
Bien entendu je leur montre la solution finale qui consiste ├Ā d├®couper le n┬░ de s├®curit├® sociale en au moins 5 groupes : sexe, mois, ann├®e, commune et rang.
De la m├¬me fa├¦on je leur donne une table contenant des informations de personnes ou l’on trouve outre le nom et le pr├®nom une adresse un mail et 3 zone de saisie de t├®l├®phones (fixe, fax et GSM), et l├Ā je leur demande de me retrouver le nom d’une personne dont le n┬░ est 06 11 44 78 95…
├ēvidemment la table contient ce genre de choses :
TEL FAX GSM
---------------- ------------------ ------------------
01 47 58 42 23 +33 5 21 56 89 45 06 11 49 56 12
0645145874
01-22-44-25-36 04-87-56-23-21 09 48 41 25 14
0645184953
+33 6 52418552 06 12457825 06 78 41 56 23
06 11 22 55 87 01.22.44.12.52
Alors qu’il est si simple de cr├®er une table des t├®l├®phones avec une seule colonne pour tous les num├®ros en les typant et en maitrisant la saisie.
Le non respect des formes normales, conduit syst├®matiquement ├Ā d├®crochage des performances d├©s que le volume des donn├®es de la base d├®passe la quantit├® de RAM.
L’application du processus de normalisation, conduit ├Ā un grand nombre de tables avec tr├©s peu de colonnes (en moyenne moins d’une dizaine) et de nombreuses jointures doivent ├¬tre r├®alis├®es pour retrouver les donn├®es. Les jointures, tout particuli├©rement lorsqu’elles portent sur des « petites » clefs (comme un entier avec un auto incr├®ment de type SEQUENCE ou IDENTITY) sont des processus d’une extr├¬me rapidit├® (c’est l’op├®ration la plus courante dans un SGBDR, donc la plus optimis├®e). Par exemple, avec deux tables de 100 millions de lignes, une jointure qui au final renvoie une ligne ne coutera que la lecture de 6 pages, ce qui est tr├©s peu. Et joindre 30 tables de 100 millions de lignes de ce type ne coute que 180 lectures, ce qui n’est rien pour un SGBDR qui g├®n├®ralement lit 8 pages d’un seul coup !
Diff├®rences entre des petites tables et une grosse table pour les op├®rations de mises ├Ā jour (├®criture) :
- Dans une grosse table contenant un grand nombre de colonnes, chaque ├®criture (INSERT, UPDATE or DELETE) pose un verrou exclusif tant est si bien que personne d’autre ne peut l’utiliser.
- Dans un jeu de plusieurs petites tables repr├®sentant une seule et m├¬me grosse table, les op├®rations d’├®criture se succ├®derons s├®quentiellement et tandis que l’un est mis a jour avec un verrou exclusive, les autres peuvent ├¬tre utilis├®s en lecture comme en ├®criture.
Finalement plus d’utilisateurs peuvent travailler simultan├®ment sans ├¬tre victimes de temps d’attente importants dans une base constitu├®e de nombreuses petites tables.
Diff├®rences entre des petites tables et une grosse table pour les op├®rations de lecture :
- Dans une table, qu’elle soit petite ou grande, une seule m├®thode doit ├¬tre choisie pour acc├®der aux donn├®es :
- – balayage de toutes les lignes de la table;
- – balayage de toutes les lignes d’un index;
- – recherche dans un index;
- Une fois qu’une grande table a ├®t├® morcel├®e en plusieurs petites tables, l’optimiseur peut choisir la meilleure m├®thode d’acc├©s entre balayage et recherche pour chacune des tables de la requ├¬te, en pr├®f├®rant la recherche aussi souvent que possible.
- S’il existe plusieurs pr├®dicats de recherches ou plusieurs conditions dans le pr├®dicat, la seule mani├©re d’op├®rer dans une grande table est de balayer toute la table.
Bien entendu les recherches sont incommensurablement plus rapides que les balayages parce que leur co├╗t est logarithmique.
Finalement et malgr├® le co├╗t des jointures, une requ├¬te avec plusieurs pr├®dicats ou conditions s’ex├®cutera beaucoup plus rapidement d├©s que le volume de donn├®es commence ├Ā peser d’un poids important. Et plus les requ├¬tes « roulent » vite, plus un grand nombre d’utilisateurs peuvent utiliser simultan├®ment le syst├©meŌĆ”
Toutes les op├®rations relationnelles dans une base de donn├®es sont faites exclusivement en m├®moire.
Aussi quelque soit la m├®thode d’acc├©s aux donn├®es, toutes les donn├®es n├®cessaires ├Ā la requ├¬te doivent ├¬tre plac├®es en RAM avant d’├¬tre lues.
- Avec un balayage, toutes les lignes de la table doivent ├¬tre plac├®es en m├®moire
- Avec une recherche, tr├©s peu de pages doivent ├¬tre plac├®es en m├®moire, parce qu’un index est un arbre et qu’il suffit d’y placer la page racine, les pages de navigation et la page feuille contenant les donn├®es finales.
Bien entendu un balayage place un grand nombre de page en m├®moire, tandis qu’une recherch├® en place tr├©s peu.
Indexation
Un moyen de r├®duire drastiquement les temps d’acc├©s est d’indexer la table. Cependant, nous allons d├®couvrir qu’indexer une table ob├©se g├®n├©re trois probl├©mes suppl├®mentaire :
– un accroissement important du volume globale de la base,
– une forte diminution de la concurrence en lecture comme en ├®criture,
– une optimisation notablement moins efficace…
├ētudions un cas th├®orique simplifi├® afin de comprendre pourquoi ces effets vont se faire sentir dans une table ob├©se.
Soit la table suivante :
CREATE TABLE Contact
(ID_personne INT PRIMARY KEY,
telephone CHAR(20),
email VARCHAR(256),
skype VARCHAR(128));
Nous supposons que les colonnes telephone, email et adresse ne sont pas toujours renseign├®e et dans ce cas une mod├®lisation respectant ├Ā la lettre les principes, aurait conduit ├Ā s├®parer en 4 tables, ces donn├®es ├Ā savoir :
CREATE TABLE Contact
(ID_personne INT PRIMARY KEY)
CREATE TABLE Contact_TEL
(ID_personne INT PRIMARY KEY,
telephone CHAR(20) NOT NULL)
CREATE TABLE Contact_EML
(ID_personne INT PRIMARY KEY,
email VARCHAR(256));
CREATE TABLE Contact_SKP
(ID_personne INT PRIMARY KEY,
skype VARCHAR(128));
1) quelle est la version du mod├©le, pr├®sentant le plus fort volume ?
Si nous comptons les donn├®es des tables, la base 1 (monotabulaire) compte au plus 408 octets par ligne (le INT comptant pour 4 octets).
La base 2 fait :
TABLE Contact : 4
TABLE Contact_TEL : 24
TABLE Contact_MEL : 260
TABLE Contact_SKP : 132
Total base 2 : 420 octets.
La diff├®rence est minime et s’il y a des NULL, leur absence de stockage dans la base 2 penchera en faveur de cette solution… Mais raisonnons par l’absurde et consid├®rons un taux de NULL de z├®ro…
Ajoutons maintenant les index… ├Ć nouveau, consid├®rons l’absurde et tentons d’indexer les 2 bases pour optimiser toutes les requ├¬tes possibles.
Dans la base monotable, les index ├Ā poser, pour optimiser tous les cas de requ├¬tes, sont les suivants :
telephone email skype CLEF D'INDEX
------------- --------- ------- ----------------------------------------------
X1 1 (telephone)
X2 1 (email)
X3 1 (skype)
X4 1 2 (telephone, email)
X5 1 2 (telephone, skype)
X6 1 2 (email, skype)
X7 1 2 3 (telephone, email, skype)
Cependant ces index ne suffisent pas ├Ā couvrir tous les cas de figure. En effet, les informations d’un index ├®tant vectoris├®es (tri de la premi├©re colonne de le clef d’index, puis tri relatif de la seconde, pour les donn├®es identiques dans la premi├©re) certaines requ├¬tes ne peuvent b├®n├®ficier des index ci dessus.
Par exemple la clause WHERE suivante :
WHERE telephone = '0123456789' AND email LIKE 'dupont%'
pourra pleinement utiliser l’index X4, tandis que cette nouvelle clause WHERE ne le peut :
WHERE telephone = '012345%' AND email = 'dupont@ibm.com'
Il faut des index compl├®mentaires avec des clefs invers├®es !
telephone email skype CLEF D'INDEX
------------- --------- ------- ----------------------------------------------
X8 2 1 (email, telephone)
X9 2 1 (skype, telephone)
X10 2 1 (skype, email)
X11 1 3 2 (telephone, skype, email)
X12 2 1 3 (email, telephone, skype)
X13 2 3 1 (skype, telephone, email)
X14 3 1 2 (email, skype, telephone)
X15 3 2 1 (skype, email, telephone)
Le volume th├®orique des index est alors le suivant :
X1 : 20
X2 : 256
X3 : 128
X4 : 276
X5 : 148
X6 : 384
X7 : 404
X8 : 276
X9 : 148
X10 : 384
X11 : 404
X12 : 404
X13 : 404
X14 : 404
X15 : 404
TOTAL indexation base monotable : 4 444 octets (+ 404 octets de ligne).
Indexation base multi tabulaire :
X1 sur table Contact_TEL (telephone) =: 20
X2 sur table Contact_MEL (email) =: 256
X3 sur table Contact_SKP (skype) =: 128
TOTA indexation base multitable : 404 (+ 420 octets)
Diff├®rence de volume des deux bases : 4848 / 824 = 5,88. Autrement dit la base monotabulaire serait pr├©s de 6 fois plus grosse que la base multitabulaire !
Comme il y a moins de chance que le plan soit optimal (voir ci apr├©s), cela conduit ├Ā des balayages de tables ou d’index plus fr├®quent, ce qui prends plus de place en cache… Au d├®triment d’autres donn├®es (le cache n’├®tant pas ├®lastique ! – car c’est la RAM…)
En ce qui concerne les mises ├Ā jour et compte tenu des verrous ├Ā poser, dans la base monotabulaire, toute mise ├Ā jour d’une seul information, bloque le ligne de la table. Plus personne ne peut acc├®der aux autres rubriques. Dans la base multitabulaire, la mise ├Ā jour d’une information ne bloque pas les autres rubrique pour la m├¬me personne. La base multitabulaire est donc 3 fois plus fluide statistiquement que la base monotabulaire…
Confront├® ├Ā un choix d’index, l’optimiseur doit d├®cider lequel prendre. Plus il y en a, et plus le travail est complexe, ardu et prends du temps. Comme les optimiseurs ont un temps impartis pour calculer le meilleur plan il est possible que, devant la combinatoire, le temps impartit soit ├®coul├® avant que le plan optimal soit trouv├®… Cons├®quence, plus il y a d’index en g├®n├®ral et sur une m├¬me table en particulier dans toute la base, et plus il y a de chance que le plan de requ├¬te soit finalement moins bon !
Enfin, pour les SGBDR qui savent travailler en parall├©le, l’acc├©s aux donn├®es sur plusieurs tables et souvent plus rapide, car fait en parall├©le,que sur une seule table plus grosse plus longue, plus grande !!!
Autre argument : la compacit├® des donn├®es
Un autre argument peut ├¬tre invoqu├® pour faire des petites tables….
Les SGBDR stockent leur donn├®es dans des pages qui font une certaine taille. Pour SQL Server comme pour PostGreSQL, cette taille est de 8 Ko.
Le principe est qu’une ligne d’une table doit imp├®rativement tenir int├®gralement dans une page. Il n’est donc pas possible de d├®passer une certains taille de ligne qui est de 8060 octets dans SQL Server et 8136 dans PostGreSQL. Si vous construisez des tables avec de nombreuses colonnes il est probable que vous vous rapprocherez vite de la limite. Mais en ├®tant un peu au dessus de la moiti├® de cette taille des probl├©mes irr├®fragables commencent. En effet si vous construisez une table avec une taille de ligne moyenne de 4500 octets, alors vous n’aurez jamais plus d’une ligne par page et perdrez par cons├®quent plus de 3500 octets qui seront inutilis├®s. De plus votre table sera vu comme fragment├®e de plus de 40% et toutes tentative de d├®fragmentation sera vaine. Enfin, vous augmentez artificiellement le volume globale de votre table de plus de 40% ! Bref, l├Ā encore les performances vont chuter….
Conclusion :
Voici un graphique montrant le temps de r├®ponse en fonction de l’augmentation du volume de la base.
Performance d’une base de donn├®es avec des tables ob├©ses
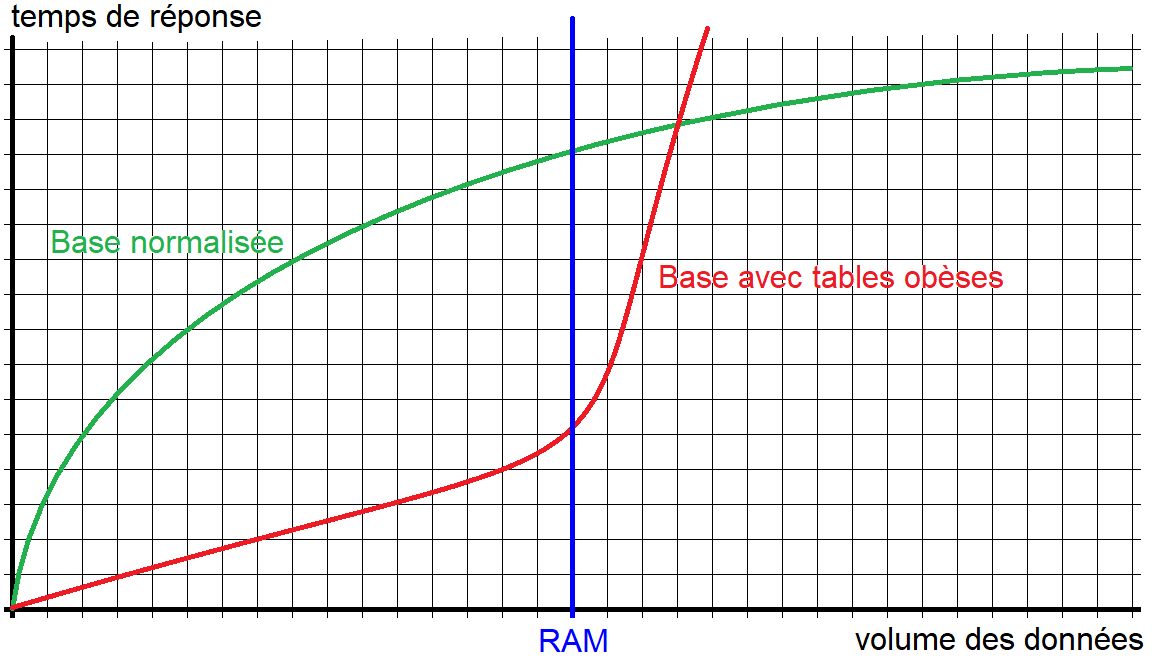
Performance d’une base de donn├®es avec des tables ob├©ses
On y voit clairement que tant que le volume des donn├®es est faible, l’avantage est ├Ā la supertable. Cependant d├©s que le volume des donn├®es devient important, alors la base normalis├®es, constitu├® de petites tables prend l’avantage, et plus la base grossira, plus l’├®cart sera important.
Dans une base de donn├®es relationnelle bien mod├®lis├®e on trouve de tr├©s nombreuses petites tables d├®passant rarement la dizaine de colonnes (hors clef ├®trang├©res). Les performances restent stables quelque soit le volume des donn├®es, car lŌĆÖoptimiseur trouvera toujours un index dont le but est faire passer le co├╗t dŌĆÖacc├©s de lin├®aire ├Ā logarithmique.
Dans une base ayant des tables ob├©ses, lŌĆÖacc├©s aux donn├®es se fait essentiellement par balayage. Les index sont rarement utilis├®s. Tant que les tables peuvent ├¬tre mise en cache dans la RAM, les temps dŌĆÖacc├©s semblent corrects. D├©s que la volum├®trie des tables d├®passe la quantit├® de RAM, les performances chutent drastiquement et les temps de r├®ponse sŌĆÖenvolent.
Dans une base mal mod├®lis├®e, le r├®sultat est une consommation anormale de RAM du fait de la structure de la table et de nombreux balayage (peu d’utilisation d’index). Dans un tel cas, la solution consiste ├Ā avoir une RAM sur le serveur ├®gal ├Ā la taille de la base ou bien de restructurer la base !
Le probl├©me est que restructurer la base n├®cessite une refonte compl├©te du d├®veloppement, si les d├®veloppeurs n’ont pas pr├®vu au d├®part d’utiliser des vuesŌĆ”
Bref, pour ne pas avoir respecter l’art de la mod├®lisation des donn├®es, les performances deviendront t├┤t ou tard un cauchemar !
--------
Fr├®d├®ric Brouard, SQLpro - ARCHITECTE DE DONN├ēES, http://sqlpro.developpez.com/
Expert bases de donn├®es relationnelles et langage SQL. MVP Microsoft SQL Server
www.sqlspot.com : mod├®lisation, conseil, audit, optimisation, tuning, formation
* * * * * Enseignant CNAM PACA - ISEN Toulon - CESI Aix en Provence * * * * *
![]()
Bonjour,
J’ai lu avec grand int├®r├¬t cet article.
Je fais un site qui permet d’├®diter des cours en ligne, et permet aux ├®l├©ves de consulter ces cours.
Un cours est structur├® en s├®quence, s├®ance puis activit├®. Chacun de ces ├®l├®ments peut avoir un diaporama, un qcm, etc. Et tous ces ├®l├®ments, disposant d’une table diff├®rente selon leur type, sont inclus les uns dans les autres selon une arborescence limit├®e (on peut mettre une image dans un diaporama mais pas le contraire !) :
s├®quence 2 enfants
-> s├®ance 1 2 enfants
-> activit├® 1.1 1 enfant
-> diaporama 3 enfants
-> photo 1
-> photo 2
-> photo 3
-> activit├® 1.2 1 enfant
-> exercice 3 enfants
-> qcm 1
-> qcm 2
-> qcm 3
-> fichier PDF
-> s├®ance 2 1 enfant
-> activit├® 2.1
De plus, je ne recherche jamais (ou presque) un enregistrement par des crit├©res divers mais uniquement par son type, qui renvoit ├Ā une table, et son identifiant qui sont tout deux connus.
Inversement, je ne connais jamais ni le nombre ni le type des enfants d’un ├®l├®ment. Le bon sens peut limiter ├Ā un maximum de 20 photos par diaporama, et ├Ā 8 enfants pour les autres ├®l├®ments.
Pour chaque ├®l├®ment pouvant avoir des enfants, une colonne enfs code le type d’enfant et son identifiant dans une chaine du type B1324 B3443 C3423 I43554 etc,
1 lettre pour d├®finir la table de l’enfant, 8 chiffres pour l’ identifiant et un s├®parateur entre chaque enfant.
Ceci correspond ├Ā la version 1 de la BDD.
Pour la version 2 de la BDD, j’ai fais avec une table de liaison mais alors, il me fallait pr├®ciser l’ordre des ├®l├®ments enfant dans son parent (version 2) :
type_parent id_parent type_enfant id_enfant ordre
C(sequence) 23345 B(s├®ance) 1324 1
C(sequence) 23345 B(s├®ance) 3443 2
C(sequence) 23345 C(s├®ance) 3423 3
C(sequence) 23345 I(s├®ance) 43554 4
Et chacun des ├®l├®ments en ligne ci-dessus pouvait ├Ā son tour avoir d’autres enfants… Et d├®finitive, cette table peut vite compter des milliards de ligne et devrait ├¬tre lue 12 fois pour l’arborescence pr├®sent├®e ci-dessus.
J’ai fait un test des deux structures de base de donn├® avec 200 000 lignes parent ou enfants et une table de liaison de 400 000 lignes.
La version 1 ├®tait presque deux fois plus rapide que la version 2 sur serveur en ligne.
Je pr├®cise aussi qu’un seul utilisateur (le prof) peut modifier un enregistrement et qu’au maximum, 400 ├®l├©ves consulteront un m├¬me cours.
Cette base est donc particuli├©re car certains ├®l├®ments comme le contenu du cours exige une colonne de 4000 octets et qu’avec 10000 profs, il peut y avoir 10 millions de lignes avec ce type de contenu.
Mon inqui├®tude est dans le risque de lenteur pour un prof ou un ├®l├©ve.
Pour y pallier, le serveur n’envoie hormis le texte du contenu, que des informations cod├®es avec un minimum de html, le javascript s’occupe de l’affichage.
Avez-vous un avis sur cette base et si cela est mauvais, des pistes d’am├®lioration ?
Cordialement
Bonjour ├Ā vous,
J’ai lu avec grande attention ce que vous avez ├®crit car c’est pr├®cis├®ment ma probl├®matique du moment.
En effet, j’envisage un portage de la base que je d├®veloppe sous PostgreSQL en partant du SGBD 4D. Hors, j’ai d├®velopp├® la base avec d’autres personnes et il a fallu dans le pass├®, arbitrer une redondance de cl├®s ├®trang├©res, selon le m├¬me principe que ce que j’ai vu plus bas :
Si on va de t1 ├Ā t5, autant avoir une cl├® ├®trang├©re vers t5 dans t1 pour aller plus vite (au lieu de t1->t2->t3->t4->t5).
Deux mauvais arguments pour ├¦a :
– c’est plus simple en support
– ce sera plus rapide
Maintenant, avec PostgreSQL, je m’imagine affranchi de ce probl├©me. Surtout quand je lis « jointure 30 tables, 10^8 donn├®es : 1ms ».
Mais dans l’exemple que vous donnez, c’est 10^8 donn├®es dans chacune des 30 tables ?
Autre point non ├®voqu├® ici mais tr├©s en rapport avec ce que vous ├®crivez :
– j’ai eu maille ├Ā partir avec un « cador » chez l’├®diteur 4D, pour qui le futur ne se dessine qu’├Ā l’aide de cl├®s primaires GUID
– j’ai d├®fendu mon point de vue qui est l’utilisation d’INT, puis vu votre intervention ici : http://www.developpez.net/forums/d717802/bases-donnees/langage-sql/id-auto-incremente-guid/
Ma question sur ce point : avez vous changez de point de vue o├╣ est-ce pour vous toujours une h├®r├®sie de n’utiliser que des cl├®s primaires GUID. Je pense que la r├®ponse est « oui, c’est une h├®r├®sie ». Mais comme j’ai ├®t├® mis ├Ā rude ├®preuve et ramen├® au rang de personne ne savant pas vivre ├Ā son ├®poque, je pr├®f├©re faire preuve de doute et me remettre en cause. Ceci ├®tant dit, nul doute que les 30 jointures en question iraient moins vites….
Merci d’avance pour vos lumi├©res !
Int├®ressant article, on vous remercie pour votre effort.
Sinon j’ai un gros souci sur base de donn├®es disant qu’elle contient 4 tables, y’a une seule table qui contient actuellement 20 millions de lignes et elle contiendra beaucoup plus que ├¦a, le temps de r├®ponse actuel d’une requ├¬te de recherche est de 3min.
La requete est :
SELECT (CASE WHEN (SELECT COUNT(j.JobID) FROM job j WHERE j.ParentJobID=jb.JobID )=0 THEN 0 ELSE 1 END) as ‘ExitSousJob’,jb.JobID as ‘JobID’ ,
jb.JobID as ‘DownFileIn’ , jb.JobID as ‘DownFileOut’,jb.JobID as ‘DownFileAll’ , jb.ParentJobID as ‘JobPereID’ , jb.StartDate as ‘DateDebut’ ,
(CASE WHEN jb.Duration IS NULL THEN ‘-‘ ELSE (CASE WHEN jb.Duration 0 THEN jb.Duration/1000 ELSE jb.Duration END) END ) as ‘Duree’ ,
Lab.Fr as ‘Statut’ ,
(CASE WHEN jbt.LabelID IS NULL THEN jbt.Alias ELSE (SELECT Fr FROM label l WHERE l.LabelID= jbt.LabelID) END) as ‘Type’ ,
(CASE WHEN jb.Description IS NULL THEN ‘-‘ ELSE jb.Description END ) as ‘Description’,
st.StatusTypeID as ‘IdStat’
FROM Job jb
INNER JOIN jobtype jbt on jb.JobTypeID=jbt.JobTypeID
INNER JOIN statustype st on st.StatusTypeID=jb.StatusTypeID
LEFT JOIN label lab on lab.LabelID = st.LabelID
WHERE jb.EnvID IN ( 1,40,41,22,37,25,26,39,38,42,43 ) AND jb.JobTypeID = 1 AND jb.StatusTypeID = 0
ORDER BY StartDate DESC LIMIT 500
Structure de la table Job : CREATE TABLE IF NOT EXISTS `job` (
`JobID` int(10) unsigned NOT NULL,
`StartDate` datetime NOT NULL,
`EndDate` datetime DEFAULT NULL,
`Duration` int(10) unsigned DEFAULT NULL,
`ParentJobID` int(10) unsigned DEFAULT NULL,
`SessionJobID` int(10) unsigned DEFAULT NULL,
`JobTypeID` smallint(5) unsigned NOT NULL,
`StatusTypeID` mediumint(8) unsigned NOT NULL,
`Visible` tinyint(1) NOT NULL,
`EnvID` int(5) unsigned NOT NULL,
`Description` text,
PRIMARY KEY (`JobID`),
KEY `ParentJobID` (`ParentJobID`),
KEY `SessionJobID` (`SessionJobID`),
KEY `JobTypeID` (`JobTypeID`),
KEY `EnvID` (`EnvID`),
KEY `StatusTypeID` (`StatusTypeID`),
KEY `StartDate` (`StartDate`),
KEY `Duration` (`Duration`)
)
Merci d’avance.
Cet article est tr├©s int├®ressant et me donne envie de r├®fl├®chir sur l’architecture actuelle de notre base de donn├®e.
Nous enregistrons 1000 valeurs tous les X secondes et notre table ressemble ├Ā cela.
Date | Valeur1 | Valeur2 | Valeur3 … Valeur1000
X | 5.3666 | 4.1223 | 7.8888 … 5.757
X+1 | 5.3666 | 4.1223 | 7.8888 … 5.757
X+2 | 5.3666 | 4.1223 | 7.8888 … 5.757
Quelle pourrait ├¬tre la forme normal de cette table dans une base de donn├®e relationnelle ?
Nous avons un probl├©me avec le nombre max de colonne qui est limit├® ├Ā ce que peut faire SQL Server (1024) et nous aimerions am├®liorer les performances d’├®criture.
Nos tables contiennent plusieurs millions de points (en moyenne 1 ligne par secondes donc au bout d’un an ├¦a fait 31.536.000 de lignes de 1000 valeurs).
Auriez vous une piste d’am├®lioration ?
Bonjour,
Votre table devrait ressembler
(
ChampDate datetime NOT NULL, // conserve la valeur de datetime
Numvaleur int NOT NULL, // conserve le num├®ro de valeur (index de ta colonne)
Valeur float(53) NOT NULL // conserve la valeur
) ON [PRIMARY]
(j’ai ├®lud├® la probl├®matique des indexs)
tu pourras facilement faire des op├®rations de sommes, de moyennes et autres stats ├Ā vitesse grand V sur n’importe quelle plage de temps.
ta table ne fera pas 31Millions de ligne mais 31 milliards (bon courage!) => peut ├¬tre penser ├Ā optimiser les types de valeurs car le moindre octet de gagn├® entra├«nera 31Go de data sur le disque en moins).
tu ne seras plus limit├® par le nombre de valeur par ligne
Ajouter 1000 lignes par seconde ne devrait pas ├¬tre un soucis (si c’est un soucis, contactez moi)
Pour info, nous avons une table de 2 milliards de points de mesure ainsi form├®e pour le concentrateur de donn├®es de surveillance des crues du grand delta du rh├┤ne. Cela ne pose aucun probl├©me de performances (et m├¬me avec un serveur n’ayant que 4 Go de ram !!!), dŌĆÖautant que c’est associ├® ├Ā des vues index├®es.
A +
Ping : La normalisation | Module base de donn├®es ├Ā l'ICOF – BTS SIO
Bonjour,
J’aurais une question concernant l’atomicit├® (enfin je crois que c’est ├Ā cela que ├¦a se rapporte).
Dans le cadre d’une base de donn├®e servant ├Ā g├®rer les privil├©ges d’acc├©s des utilisateurs ├Ā certaines applications propre ├Ā l’entreprise, il existerait la table suivante :
CREATE TABLE DBO.tbl_UM_Demand_UMD(
ID INT IDENTITY(1,1) NOT NULL,
USER_ID INT NOT NULL,
APP_ID INT NOT NULL,
RIGHT_ID INT NOT NULL,
ASK_DATE DATETIME NOT NULL CONSTRAINT DF_tbl_UM_Demande_UMD_ASK_DATE DAFAULT (getdate()),
VALIDATED BIT NOT NULL CONSTRAINT DF_tbl_UM_Demande_UMD_VALIDATED DAFAULT (‘false’),
VALIDATION_DATE DATETIME NULL
)
Dans cette table, les colonnes USER_ID, APP_ID et RIGHT_ID sont bien s├╗r des clefs ├®trang├©res vers les tables ad├®quates.
Ma question porte sur les colonnes VALIDATED et VALIDATION_DATE.
├Ć partir du moment o├╣ une date de validation est pr├®sente, on peut en d├®duire ├Ā 100% que la demande est bien valid├®e. De ce fait, la colonne VALIDATED est-elle n├®cessaire ? Est-ce une « grave » faute de conception ou cela peut-il ├¬tre envisag├® dans certains cas ?
Griftou.
Ping : Optimiser les tables de sa base de donn├ā┬®es | liens-geeks.com
Eric190 : Merci pour la mention du travail fait par la DSI de la Pr├®fecture de Police (mon nouveau service :-))…
SQLpro : Merci ├Ā la PP pour utiliser quelques uns des mes algo comme PHONEX… Mais pour eux la marchandise est humaine !
Super billet, comme ├Ā ton habitude… continue comme ├¦a.
Merci pour la mention du travail fait par la DSI de la Pr├®fecture de Police (mon nouveau service :-))…
@+
Eric POMMEREAU
ec : l’atomicit├® … […] doit ├¬tre adapt├®e aux objectifs de l’application
SQLpro : c’est parfaitement exact, mais cela n’emp├¬che pas de le faire un minimum. Votre exemple est celui que je prend pour mes cours dans les ├®coles d’ing├®nieurs. Et notamment c’est tr├©s important pour les sites web marchand, car il existe des entreprises qui valident les adresses ├Ā condition que l’on ait dissoci├® le type de voie, le nom de la voie et le n┬░.
R├®cemment dans un colloque sur les SIG dans PostGreSQL, la Pr├®fecture de Police montrait une application de validation d’adresse bas├® sur cette m├¬me atomisation. le but de la validation des adresses est d’├®viter des retours de marchandise tr├©s couteux. Les premiers sites Web marchand en ont fait les frais et certains ont d├╗ d├®poser le bilan ├Ā cause d’un taux de retour trop ├®lev├®, mangeant la marge (affaire P├©re Noel .com par exemple).
ec : Enfin la d├®-normalisation, si elle est parfois plus pratique, est facile ├Ā obtenir par des requ├¬tes qui rassemblent les informations de plusieurs tables parfaitement normalis├®es
SQLpro : c’est le but des vues !
seb : Faire une jointure est toujours plus lent que de mettre les donn├®es dans la m├¬me table.
SQLpro : visiblement vous n’avez rien compris…. Une jointure n’est pas couteuse lorsqu’elle est faites sur de bonnes clefs (colonne unique index├®es de type entier de part et d’autre du pr├®dicats de jointure) car le SGBDR fait un tri fusion (MERGE). Bref, pour joindre deux tables de 100 millions de lignes et retrouver une ligne il faut lire 3 pages de part et d’autre… C’est presque rien.
Alors que dans votre grosse table comme il faudra sans arr├¬t la mettre ├Ā jour elle sera verrouill├® de mani├©re exclusive bien plus fr├®quemment que si vous aviez fait de multiples tables, ce qui emp├¬chera la mont├®e en charge concurrentielle et par cons├®quent ralentira globalement le service des donn├®es de mani├©re rapide.
En gros, avec une bonne normalisation, le temps de r├®ponse lors de la mont├®e en charge est lin├®aire, tandis que que sans elle est exponentielle.
Bien entendu vous avez finalement raison, de dire que « faire une jointure est toujours plus lent que de mettre les donn├®es dans la m├¬me table » s’il n’y a jamais qu’un seul utilisateur dans votre base !
Et avec un tel raisonnement ├Ā courte vue, pourquoi ne pas faire une seule table dans la base ? Ceal ira encore plus vite… non ?
Voici un bel article th├®orique sans exp├®rience …
La normalisation d’une base de donn├®es est li├®e aux besoins et non une doctrine.
Faire une jointure est toujours plus lent que de mettre les donn├®es dans la m├¬me table.
Les SGBD g├©rent facilement des gigas de donn├®es alors rien ne sert d’├®viter les duplications de donn├®es.
Les benchs globaux sont idiots : on utilise pas toutes les requ├¬tes de la m├¬me mani├©re.
Normaliser une BD est li├® au besoin fonctionnel : quelles filtres devrons nous mettre en place ?
Excellent article !
Mais… si l’atomicit├® est un excellent principe de conception… elle doit ├¬tre adapt├®e aux objectifs de l’application.
Exemple : la plupart du temps on met le N┬░ de rue, le type de rue et le nom de rue dans une seul champ « xyzAdresseRue ». Et cela ne pose g├®n├®ralement aucun probl├©me.
Mais si un organisme a recours ├Ā ses propres porteurs pour distribuer des courriers, il est n├®cessaire de pouvoir trier les nom de rues et donc d’isoler dans un champ ces noms de rues et de mettre dans d’autres champs les num├®ros et les type de rues. Il peut m├¬me ├¬tre utile de regrouper les rues d’un m├¬me quartier et donc d’ajouter ce type de pr├®cision dans un champs de la table.
L’exigence d’atomicit├® est donc relative aux besoins de l’organisme.
Il est clair qu’il convient d’anticiper ces besoins au moment de la conception. Mais quelle utilit├® de dicotomiser les adresses pour une entreprise qui confierait tout ├Ā la Poste ?
Enfin la d├®-normalisation, si elle est parfois plus pratique, est facile ├Ā obtenir par des requ├¬tes qui rassemblent les informations de plusieurs tables parfaitement normalis├®es et parfois m├¬me en rassemblant plusieurs champs dans un seul champs … par exemple des requ├¬tes pour des mailings : en fin de course la secr├®taire appr├®ciera de n’avoir qu’un champs « xyzAdresseRue » ├Ā manipuler… de m├¬me que civilit├®-pr├®nom-nom rassembl├®s par exemple ou s’il faut remettre sur une m├¬me ligne tous les num├®ros de t├®l├®phones, mobiles et fax qui auraient ├®t├® typ├®s avec deux champs (type et num├®ro) comme ├®voqu├® dans l’article.
Max34 : Si j’ai un requ├¬te qui n├®cessite 30 jointures suis je toujours gagnant ?
SQLpro : Oui, en d├®mo avec mes ├®leves je demande quel est le cout de 30 jointures sur des tables de 100 millions de lignes dont la clef est un INT… La r├®ponse est 180 pages ├Ā lire soit moins de 1 ms sur un serveur bas de gamme !
SamSam69 : Il est plus judicieux de mettre une jointure entre ma table t1 et t5 afin de r├®duire les jointures de 4 ├Ā 1
SQLpro : NON ! Car vous oubliez toujours la m├¬me chose : vous allez gagner pour cette requ├¬te, mais comme vous allez augmenter la volume des donn├®es, vous allez perdre GLOBALEMENT pour toutes les autres requ├¬tes !
Avez vous fait des bench globaux avant de pr├®coniser cette solution ???
Bonjour
Il est plus facile de « d├®normaliser » que l’inverse.
Un projet devrait commencer avec des tables normalis├®es et, ensuite, on d├®normalise si le besoin se fait sentir.
actuellement, nos DBA voient des trucs assez ahurissants, par ex du num├®rique stock├® dans du char parceque les reports sont plus faciles ├Ā produire. Sur une table interrog├®e plusieurs milliers de fois par heure, le cout des conversions CHAR==>NUM est si important que les chefs ont d├®marr├® un projet de remise en forme des donn├®es.
Le soucis vient surtout du manque d’importance accord├®e ├Ā la normalisation et aux performances. les dev ont appris des trucs ├Ā l’├®cole, mais ├Ā quoi ca sert?
Et je ne parle pas de normalisation « extr├©me », mais des trucs tout bete ├Ā respecter.
Bon article de best pratice
Je rejoins l’avis de plusieurs personnes en commentaire, la normalisation n’est pas toujours adapt├®e. Dans un SID, il me semble plus interessant d’avoir une structure denormalis├®e.
Bonjour
Merci SQLpro pour cet article, ├¦a me rappelle la formation que tu as faites ├Ā mes coll├©gues et moi il y a 4 ans sur Nice. Et c’├®tait joyeux une base de donn├®es de plus d’une centaine de tables sans aucune clef ├®trang├©re ni index ni vue et ├®norm├®ment de donn├®es dupliqu├®es et redontantes pour ├®viter les jointures.
@SamSam69 : comme le disait mon formateur : l’efficacit├® d’une d├®normalisation ne se suppose pas, elle se prouve. Donc oui on peut d├®normaliser mais il faut bien le faire.
On peut d├®couper chaque champs lettre par lettre ou apprendre ├Ā se servir correctement des index et utiliser un SGBD performant.
Vous poussez le principe d’atomicit├® un peu trop loin ├Ā mon go├╗t. Est-ce que sous pr├®texte de faire des recherches alphab├®tiques sur des noms, il faudrait cr├®er un champs sp├®cifique pour leurs premi├©res lettres ?
Je comprends que les consultants aient besoin de justifier leurs tarifs mais l├Ā c’est soit trop abusif, soit expliqu├® avec de mauvais exemples.
Tr├©s bon article!
Cependant la normalisation a ses limites car ├Ā force de normaliser on perd en performance. C’est la o├╣ l’on choisi une architecture OLAP.
Voici un exemple :
Imaginons que j’ai besoin de filtrer des informations de ma table t1 par rapport ├Ā un champ qui se trouve dans une table t5 (GROUP BY) en amont (├Ā un t1 correspond un seul t2 et ainsi de suite) :
exemple : t1 -> t2 -> t3 -> t4 -> t5.monChampDAgregation
Il est plus judicieux de mettre une jointure entre ma table t1 et t5 afin de r├®duire les jointures de 4 ├Ā 1 tout en limitant le poids de ma table t1 car un id est en g├®n├®ral un simple entier donc tr├©s peu gourmand en terme de ressources.
Pour conclure il faut normaliser au maximum puis d├®normaliser un peu pour optimiser les performances.
PS: Dans mon exemple t1 est une tr├©s grosse table. Si toutes les tables contenaient peu de lignes les performances seraient largement correctes m├¬me en la laissant normalis├®e (avec les indexes qui vont bien ├®videmment).
Bonjour,
Et merci pour cette mise au point. Cependant je voulais savoir jusqu’├Ā quel point on peut multiplier les tables, normaliser les donn├®es? Si j’ai un requ├¬te qui n├®cessite 30 jointures suis je toujours gagnant?
Max
Zinzineti : La formation, car l’ignorance tue !
H├®las tu pr├¬che un convertis… J’enseigne dans diff├®rentes ├®coles d’ing├®. 32 h de cours sur 5 ans pour faire :
1) la mod├®lisation des donn├®es
2) le SQL et les transactions
3) le d├®cisionnel
4) l’admin de SGBDR !
Inutile de te dire que lorsque l’on arrive ├Ā peu pr├©s ├Ā faire 1 et 2 je suis content !
A +
Voil├Ā un condens├® de best pratices pour tous ceux qui travaillent directement ou indirectement avec les bases de donn├®es.
132 ! 132 c’est le nombre de colonnes d’une table que j’ai identifi├® lors d’une op├®ration « pompier » sur une application qui met ├Ā genou le serveur de base de donn├®es et renvoie les t├®l├®conseillers d’un centre d’appel en cong├®s forc├®s…
Ce qui est navrant c’est quand ces erreurs de conception proviennent de « grand » ├®diteur de logiciel.
Comment en arrive-t-on l├Ā ?
Pourquoi ces erreurs ne sont pas identifi├®es lors des tests de mont├®e de charge ?
Pourquoi ces erreurs de conception ne sont pas identif├®es avant la sortie officelle du logiciel ?
Le d├®veloppeur est-il le seul responsable dans cette affaire ?
Pour ma petite esp├®rience je pense que le mot d├®veloppeur est un fourre-tout !
un fourre-tout parce que Monsieur le d├®veloppeur doit avoir des comp├®tences larges et var├®es.
Qu’attend les managers d’├®quipe ou chefs de projet d’un d├®veloppeur ?
Pour eux le d├®veloppeur doit :
┬ż pisser des lignes de code : du bon code (.NET ou Java ou …)
┬ż savoir d├®ployer ces applications quelque soit l’environnement du client final …
┬ż ├¬tre bon en syst├©me et r├®seaux (pour ne pas tout le temps d├®ranger les ing├®nieurs syst├©mes,…)
┬ż avoir l’aptitude de travailler non seulement sur WINDOWS mais aussi sur Linux pour ├®crire de temps en temps des scripts shell
┬ż avoir de bonne aptitude ├Ā produire des documents de tests, de recette, d’exploitation,…
Et les base de donn├®es ?
Le d├®veloppeur doit :
┬ż ma├«triser la mod├®lisation/conception des bases de donn├®es (SQL SERVER ET ORACLE ET SYBASE ET …)
┬ż ma├«triser les principaux t├óches de maintenance des serveurs de base de donn├®es (SQL SERVER ET ORACLE ET SYBASE ET …)
┬ż ma├«triser l’├®criture de requ├¬tes SQL : pas des SELECT * Non ! mais des requ├¬tes optim├®es bref il doit ├¬tre expert en TUNING de requ├¬tes SQL
┬ż ma├«triser la conception, la cr├®ation et d├®ploiement des rapports (reporting) sur SSAS ET sur BO ET sur COGNOS ET sur ….
Honn├¬tement, est ce possible qu’un d├®veloppeur ait toutes ces comp├®tences ?
Les bases de donn├®es sont complexes, et il faut du temps et du travail pour avoir un niveau de ma├«trise acceptable sur UN SGBD !
Mais est ce que les managers d’├®puipe, les chefs de projet sont-ils sensibilis├®s sur l’importance d’une bonne conception des bases de donn├®es ?
Pas s├╗r …
Et cal├Ā complique tout ! sur les analyses, sur les d├®cisions et les actions ├Ā mener : Notamment la formation !
La formation, car l’ignorance tue !