Comme nous l’avons dit dans ce billet (Partitionner vos tables pour améliorer les performances) le réel intérêt du partitionnement réside dans le gestion des espaces de stockage des différentes partitions. Bien que le partitionnement de table soit disponible dans PostGreSQL depuis quelques versions, il est loin d’être aussi intéressant que ce que propose Oracle ou MS SQL Server… Cet article à pour but de comparer la mise en Å“uvre des différentes solutions que proposent PostGreSQL et MS SQL Server.
NOTA : les SGBDR testés sont PostGreSQL version 9.1 et MS SQL Server version 2008 R2 Enterprise (le partitionnement n’étant disponible qu’à partir de l’édition Enterprise).
1 – LE PRINCIPE DU PARTITIONNEMENT
L’idée du partitionnement est basé sur le principe de divide et impera c’est à dire diviser pour régner, dans le sens ou il est plus facile de manipuler un plus faible volume de données lorsque c’est possible. Autrement dit, le partitionnement revient à saucissonner une table en plusieurs partitions afin que la majeur partie des requêtes sur cette table ne concerne et ne manipule qu’une seule partition. Il est encore plus intéressant si chaque partition est stockée sur un disque indépendant (ou une LUN d’un SAN alignée sur des disques physiques indépendant) permettant ainsi des opérations d’écriture et de lecture physique en parallèle.
Si le principe est très intéressant, son implémentation réserve de multiples surprises que nous allons découvrir à travers cette comparaison…
2 – L’EXEMPLE
Une table très simple nous servira de cobaye. Soit une table enregistrant des mesures à des dates précises. Nous voulons partitionner cette tables par années.
Voici la description de cette table en « pur » SQL :
CREATE TABLE T_MESURE_MSR
(
MSR_ID INT NOT NULL,
MSR_DATE DATE NOT NULL,
MSR_MESURE FLOAT NOT NULL
)
Pour laquelle nous désirons partitionner par années, sachant que nous bornes sont :
- le premier janvier 2008
- le premier janvier 2009
- le premier janvier 2010
- le premier janvier 2011.
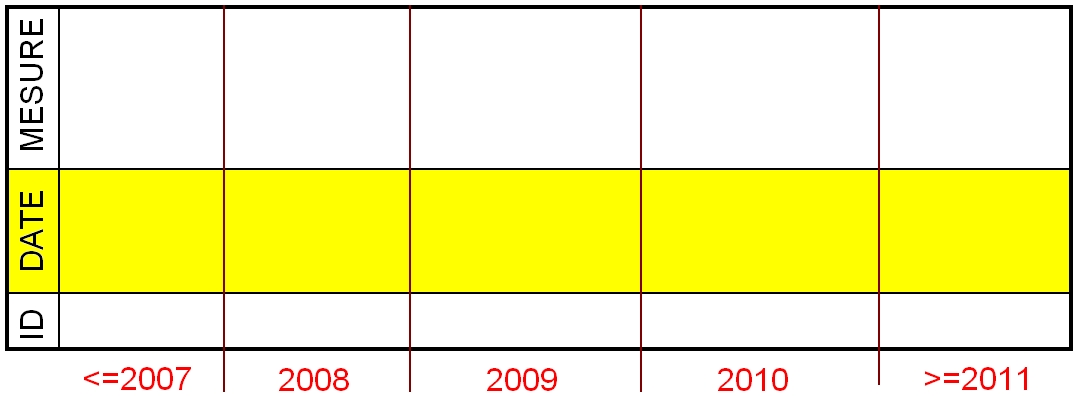
Première surprise : la règle des piquets et des intervalles…
Si nous voulons partitionner en n valeurs pivot (dites « piquets« ) il nous faudra n+1 intervalles ! Sinon, nous ne pourrons prendre en compte toutes les valeurs.
Par exemple dans une table partitionnée par date, si nous voulons partitionner pour les années de 2008 à 2011, il faudra 5 partitions :
- toutes les lignes de 2007 et avant
- les lignes de l’année 2008
- les lignes de l’année 2009
- les lignes de l’année 2010
- toutes les lignes de 2011 et après
3 – TECHNIQUE DU PARTITIONNEMENT
Pour PostGreSQL, la méthode se déroule en 6 temps :
- créer une table mère
- créer les espaces de stockage des partitions (ici 5)
- créer autant de tables filles qu’il existe de partitions (ici 5) avec une contrainte CHECK vérifiant que les données valident les bornes de la partition;
- greffer sur la table mère ou la vue autant de règles pour chacun des ordres SQL de mise à jour de données qu’il existe de table fille (5 « rules » INSERT + 5 « rules » UPDATE + 5 « rules » DELETE).
- rajouter un déclencheur pour interdire à la table mère de recevoir des lignes (2 commandes SQL)
Avec 4 valeurs pivots, soit 5 partitions, PostGreSQL nécessite donc de lancer 28 commandes SQL, mais nous allons voir que les règles UPDATE multiplient encore cette complexité par le nombre de partition. Au final nous arrivons à un nombre global de 58 requêtes SQL !
A noter : il n’existe pas d’IHM pour créer un partitionnement avec PostGreSQL.
Pour SQL Server, la méthode se déroule en 4 temps :
- créer autant d’espaces de stockage que de partitions (FILEGROUP + FILE = 10 commandes)
- créer une fonction de partition avec les valeurs pivot
- créer un schéma de répartition des données faisant appel à la fonction de partition
- créer la table sur le schéma de partition
Avec 4 valeurs pivots, soit 5 partitions, MS SQL Server nécessite donc de lancer 13 ordres SQL.
L’outil SSMS propose outre des IHM pour le partitionnement, un assistant.
Assistant de partitionnement dans SSMS pour SQL Server :
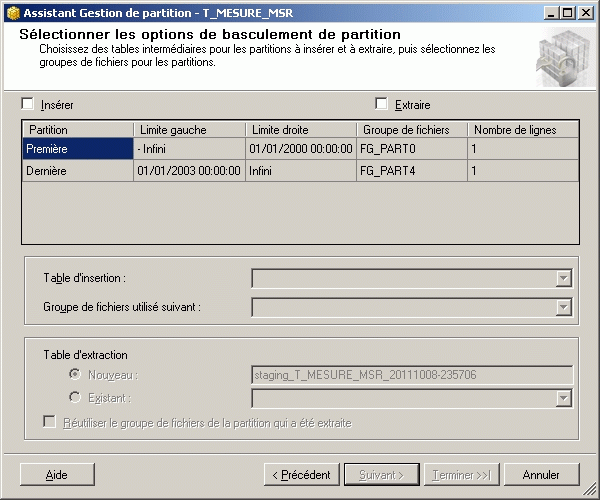
Bonne idée, mais hélas l’assistant est bugué !
NOTA : la différence est déjà significative en terme de nombre de commande et donc de complexité de mise en œuvre :
pour PostGreSQL il faut ((n+1) * 5) + 3 commandes SQL si l’on partitionne avec gestion des espaces de stockage, tandis que que pour SQL Server il faut ((n+1) * 2) + 3 commandes SQL, soit un gain d’environ 2,5 fois en faveur de MS SQL Server.
De plus, si l’on ne gère pas les espaces de stockage, la différence devient infinie ! En effet, SQL Server n’a besoin que de 3 commandes quelque soit le nombre de partitions, tandis que PostGreSQL à besoin de ((n+1) * 4) + 2 commandes…
Voyons maintenant le mise en Å“uvre dans les deux SGBDR…
3 – LA SOLUTION POSTGRESQL
3.1 – mise en Å“uvre
3.1.1 Рcr̩ation de la table m̬re :
CREATE TABLE T_MESURE_MSR
(
MSR_ID INT NOT NULL,
MSR_DATE DATE NOT NULL,
MSR_MESURE FLOAT NOT NULL
);
3.1.2 Рcr̩ation des espaces de stockage :
Les répertoires visés doivent préalablement exister.
LOCATION 'E:\SQLDATA\PARTMSR0\';
CREATE TABLESPACE TS_PART1
LOCATION 'F:\SQLDATA\PARTMSR1\';
CREATE TABLESPACE TS_PART2
LOCATION 'G:\SQLDATA\PARTMSR2\';
CREATE TABLESPACE TS_PART3
LOCATION 'H:\SQLDATA\PARTMSR3\';
CREATE TABLESPACE TS_PART4
LOCATION 'I:\SQLDATA\PARTMSR4\';
3.1.3 Рcr̩ation des 5 tables filles de partitionnement :
CREATE TABLE T_MESURE_AVANT2008_MSR
(
CHECK ( MSR_DATE < DATE '2008-01-01')
) INHERITS (T_MESURE_MSR) TABLESPACE TS_PART0;
CREATE TABLE T_MESURE_AN2008_MSR
(
CHECK ( MSR_DATE >= DATE '2008-01-01' AND MSR_DATE < DATE '2009-01-01')
) INHERITS (T_MESURE_MSR) TABLESPACE TS_PART1;
CREATE TABLE T_MESURE_AN2009_MSR
(
CHECK ( MSR_DATE >= DATE '2009-01-01' AND MSR_DATE < DATE '2010-01-01')
) INHERITS (T_MESURE_MSR) TABLESPACE TS_PART2;
CREATE TABLE T_MESURE_AN2010_MSR
(
CHECK ( MSR_DATE >= DATE '2010-01-01' AND MSR_DATE < DATE '2011-01-01')
) INHERITS (T_MESURE_MSR) TABLESPACE TS_PART3;
CREATE TABLE T_MESURE_APRES2010_MSR
(
CHECK ( MSR_DATE >= DATE '2011-01-01')
) INHERITS (T_MESURE_MSR) TABLESPACE TS_PART4;
Notez qu’à ce stade il n’existe aucun moyen de contrôle de ne pas faire d’erreur, par exemple en créant deux tables filles dont les contraintes de domaine se superposent ou crée un « vide »…
3.1.4 – création des 15 règles de reroutage de mise à jour
Reroutage des INSERTs :
INSERT avant 2008 :
CREATE RULE R_I_MSR_AVANT2008
AS
ON INSERT TO T_MESURE_MSR
WHERE ( MSR_DATE < DATE '2008-01-01' )
DO INSTEAD
INSERT INTO T_MESURE_AVANT2008_MSR
VALUES ( NEW.MSR_ID,
NEW.MSR_DATE,
NEW.MSR_MESURE );
INSERT de 2008 :
CREATE RULE R_I_MSR_AN2008 AS
ON INSERT TO T_MESURE_MSR
WHERE ( MSR_DATE >= DATE '2008-01-01'
AND MSR_DATE < DATE '2009-01-01' )
DO INSTEAD
INSERT INTO T_MESURE_AN2008_MSR
VALUES ( NEW.MSR_ID,
NEW.MSR_DATE,
NEW.MSR_MESURE );
INSERT de 2009 :
CREATE RULE R_I_MSR_AN2009 AS
ON INSERT TO T_MESURE_MSR
WHERE ( MSR_DATE >= DATE '2009-01-01'
AND MSR_DATE < DATE '2010-01-01' )
DO INSTEAD
INSERT INTO T_MESURE_AN2009_MSR
VALUES ( NEW.MSR_ID,
NEW.MSR_DATE,
NEW.MSR_MESURE );
INSERT de 2010 :
CREATE RULE R_I_MSR_AN2010 AS
ON INSERT TO T_MESURE_MSR
WHERE ( MSR_DATE >= DATE '2010-01-01'
AND MSR_DATE < DATE '2011-01-01' )
DO INSTEAD
INSERT INTO T_MESURE_AN2010_MSR
VALUES ( NEW.MSR_ID,
NEW.MSR_DATE,
NEW.MSR_MESURE );
INSERT après 2010 :
CREATE RULE R_I_MSR_APRES2010 AS
ON INSERT TO T_MESURE_MSR
WHERE ( MSR_DATE >= DATE '2011-01-01' )
DO INSTEAD
INSERT INTO T_MESURE_APRES2010_MSR
VALUES ( NEW.MSR_ID,
NEW.MSR_DATE,
NEW.MSR_MESURE );
Reroutage des UPDATEs :
UPDATE avant 2008 :
CREATE RULE R_U_MSR_AVANT2008
AS
ON UPDATE TO T_MESURE_MSR
WHERE ( NEW.MSR_DATE < DATE '2008-01-01' )
DO INSTEAD
(
-- lignes ne changeant pas de partition
UPDATE T_MESURE_AVANT2008_MSR
SET MSR_ID = NEW.MSR_ID,
MSR_DATE = NEW.MSR_DATE,
MSR_MESURE = NEW.MSR_MESURE
WHERE ( OLD.MSR_DATE < DATE '2008-01-01' );
-- lignes migrant d'une partition à l'autre
-- on insére d'abord les lignes ayant migrées
INSERT INTO T_MESURE_AVANT2008_MSR
SELECT NEW.MSR_ID,
NEW.MSR_DATE,
NEW.MSR_MESURE
WHERE NOT ( OLD.MSR_DATE < DATE '2008-01-01' ) ;
-- puis supprime les lignes en migration dans chacune des partitions
-- d'abord dans la table de l'an 2008
DELETE FROM T_MESURE_AN2008_MSR
WHERE MSR_ID = OLD.MSR_ID
AND MSR_DATE = OLD.MSR_DATE
AND MSR_MESURE = OLD.MSR_MESURE
AND OLD.MSR_DATE >= '2008-01-01'
AND OLD.MSR_DATE < '2009-01-01';
-- ensuite dans la table de l'an 2009
DELETE FROM T_MESURE_AN2009_MSR
WHERE MSR_ID = OLD.MSR_ID
AND MSR_DATE = OLD.MSR_DATE
AND MSR_MESURE = OLD.MSR_MESURE
AND OLD.MSR_DATE >= '2009-01-01'
AND OLD.MSR_DATE < '2010-01-01';
-- ensuite dans la table de l'an 2010
DELETE FROM T_MESURE_AN2010_MSR
WHERE MSR_ID = OLD.MSR_ID
AND MSR_DATE = OLD.MSR_DATE
AND MSR_MESURE = OLD.MSR_MESURE
AND OLD.MSR_DATE >= '2010-01-01'
AND OLD.MSR_DATE < '2011-01-01';
-- et enfin dans la table d'après 2010
DELETE FROM T_MESURE_APRES2010_MSR
WHERE MSR_ID = OLD.MSR_ID
AND MSR_DATE = OLD.MSR_DATE
AND MSR_MESURE = OLD.MSR_MESURE
AND OLD.MSR_DATE >= '2011-01-01';
);
UPDATE de 2008 :
CREATE RULE R_U_MSR_AN2008
AS
ON UPDATE TO T_MESURE_MSR
WHERE ( NEW.MSR_DATE >= DATE '2008-01-01'
AND NEW.MSR_DATE < DATE '2009-01-01' )
DO INSTEAD
(
-- lignes ne changeant pas de partition
UPDATE T_MESURE_AN2008_MSR
SET MSR_ID = NEW.MSR_ID,
MSR_DATE = NEW.MSR_DATE,
MSR_MESURE = NEW.MSR_MESURE
WHERE ( OLD.MSR_DATE >= DATE '2008-01-01'
AND OLD.MSR_DATE < DATE '2009-01-01' );
-- lignes migrant d'une partition à l'autre
-- on insére d'abord les lignes ayant migrées
INSERT INTO T_MESURE_AN2008_MSR
SELECT NEW.MSR_ID,
NEW.MSR_DATE,
NEW.MSR_MESURE
WHERE NOT ( OLD.MSR_DATE >= DATE '2008-01-01'
AND OLD.MSR_DATE < DATE '2009-01-01' );
-- puis on supprime les lignes en migration dans chacune des partitions
-- d'abord dans la table d'avant l'an 2008
DELETE FROM T_MESURE_AVANT2008_MSR
WHERE MSR_ID = OLD.MSR_ID
AND MSR_DATE = OLD.MSR_DATE
AND MSR_MESURE = OLD.MSR_MESURE
AND OLD.MSR_DATE < '2008-01-01';
-- ensuite dans la table de l'an 2009
DELETE FROM T_MESURE_AN2009_MSR
WHERE MSR_ID = OLD.MSR_ID
AND MSR_DATE = OLD.MSR_DATE
AND MSR_MESURE = OLD.MSR_MESURE
AND OLD.MSR_DATE >= '2009-01-01'
AND OLD.MSR_DATE < '2010-01-01';
-- ensuite dans la table de l'an 2010
DELETE FROM T_MESURE_AN2010_MSR
WHERE MSR_ID = OLD.MSR_ID
AND MSR_DATE = OLD.MSR_DATE
AND MSR_MESURE = OLD.MSR_MESURE
AND OLD.MSR_DATE >= '2010-01-01'
AND OLD.MSR_DATE < '2011-01-01';
-- et enfin dans la table d'après 2010
DELETE FROM T_MESURE_APRES2010_MSR
WHERE MSR_ID = OLD.MSR_ID
AND MSR_DATE = OLD.MSR_DATE
AND MSR_MESURE = OLD.MSR_MESURE
AND OLD.MSR_DATE >= '2011-01-01';
);
UPDATE de 2009 :
CREATE RULE R_U_MSR_AN2009
AS
ON UPDATE TO T_MESURE_MSR
WHERE ( NEW.MSR_DATE >= DATE '2009-01-01'
AND NEW.MSR_DATE < DATE '2010-01-01' )
DO INSTEAD
(
-- lignes ne changeant pas de partition
UPDATE T_MESURE_AN2009_MSR
SET MSR_ID = NEW.MSR_ID,
MSR_DATE = NEW.MSR_DATE,
MSR_MESURE = NEW.MSR_MESURE
WHERE ( OLD.MSR_DATE >= DATE '2009-01-01'
AND OLD.MSR_DATE < DATE '2010-01-01' );
-- lignes migrant d'une partition à l'autre
-- on insére d'abord les lignes ayant migrées
INSERT INTO T_MESURE_AN2009_MSR
SELECT NEW.MSR_ID,
NEW.MSR_DATE,
NEW.MSR_MESURE
WHERE NOT ( OLD.MSR_DATE >= DATE '2009-01-01'
AND OLD.MSR_DATE < DATE '2010-01-01' );
-- puis on supprime les lignes en migration dans chacune des partitions
-- d'abord dans la table d'avant l'an 2008
DELETE FROM T_MESURE_AVANT2008_MSR
WHERE MSR_ID = OLD.MSR_ID
AND MSR_DATE = OLD.MSR_DATE
AND MSR_MESURE = OLD.MSR_MESURE
AND OLD.MSR_DATE < '2008-01-01';
-- d'abord dans la table de l'an 2008
DELETE FROM T_MESURE_AN2008_MSR
WHERE MSR_ID = OLD.MSR_ID
AND MSR_DATE = OLD.MSR_DATE
AND MSR_MESURE = OLD.MSR_MESURE
AND OLD.MSR_DATE >= '2008-01-01'
AND OLD.MSR_DATE < '2009-01-01';
-- ensuite dans la table de l'an 2010
DELETE FROM T_MESURE_AN2010_MSR
WHERE MSR_ID = OLD.MSR_ID
AND MSR_DATE = OLD.MSR_DATE
AND MSR_MESURE = OLD.MSR_MESURE
AND OLD.MSR_DATE >= '2010-01-01'
AND OLD.MSR_DATE < '2011-01-01';
-- et enfin dans la table d'après 2010
DELETE FROM T_MESURE_APRES2010_MSR
WHERE MSR_ID = OLD.MSR_ID
AND MSR_DATE = OLD.MSR_DATE
AND MSR_MESURE = OLD.MSR_MESURE
AND OLD.MSR_DATE >= '2011-01-01';
);
UPDATE de 2010 :
CREATE RULE R_U_MSR_AN2010
AS
ON UPDATE TO T_MESURE_MSR
WHERE ( NEW.MSR_DATE >= DATE '2010-01-01'
AND NEW.MSR_DATE < DATE '2011-01-01' )
DO INSTEAD
(
-- lignes ne changeant pas de partition
UPDATE T_MESURE_AN2010_MSR
SET MSR_ID = NEW.MSR_ID,
MSR_DATE = NEW.MSR_DATE,
MSR_MESURE = NEW.MSR_MESURE
WHERE ( OLD.MSR_DATE >= DATE '2010-01-01'
AND OLD.MSR_DATE < DATE '2011-01-01' );
-- lignes migrant d'une partition à l'autre
-- on insére d'abord les lignes ayant migrées
INSERT INTO T_MESURE_AN2010_MSR
SELECT NEW.MSR_ID,
NEW.MSR_DATE,
NEW.MSR_MESURE
WHERE NOT ( OLD.MSR_DATE >= DATE '2010-01-01'
AND OLD.MSR_DATE < DATE '2011-01-01' );
-- puis on supprime les lignes en migration dans chacune des partitions
-- d'abord dans la table d'avant l'an 2008
DELETE FROM T_MESURE_AVANT2008_MSR
WHERE MSR_ID = OLD.MSR_ID
AND MSR_DATE = OLD.MSR_DATE
AND MSR_MESURE = OLD.MSR_MESURE
AND OLD.MSR_DATE < '2008-01-01';
-- d'abord dans la table de l'an 2008
DELETE FROM T_MESURE_AN2008_MSR
WHERE MSR_ID = OLD.MSR_ID
AND MSR_DATE = OLD.MSR_DATE
AND MSR_MESURE = OLD.MSR_MESURE
AND OLD.MSR_DATE >= '2008-01-01'
AND OLD.MSR_DATE < '2009-01-01';
-- ensuite dans la table de l'an 2009
DELETE FROM T_MESURE_AN2009_MSR
WHERE MSR_ID = OLD.MSR_ID
AND MSR_DATE = OLD.MSR_DATE
AND MSR_MESURE = OLD.MSR_MESURE
AND OLD.MSR_DATE >= '2009-01-01'
AND OLD.MSR_DATE < '2010-01-01';
-- et enfin dans la table d'après 2010
DELETE FROM T_MESURE_APRES2010_MSR
WHERE MSR_ID = OLD.MSR_ID
AND MSR_DATE = OLD.MSR_DATE
AND MSR_MESURE = OLD.MSR_MESURE
AND OLD.MSR_DATE >= '2011-01-01';
);
UPDATE après 2010 :
REATE RULE R_U_MSR_APRES2010
AS
ON UPDATE TO T_MESURE_MSR
WHERE ( NEW.MSR_DATE >= DATE '2011-01-01' )
DO INSTEAD
(
-- lignes ne changeant pas de partition
UPDATE T_MESURE_APRES2010_MSR
SET MSR_ID = NEW.MSR_ID,
MSR_DATE = NEW.MSR_DATE,
MSR_MESURE = NEW.MSR_MESURE
WHERE ( OLD.MSR_DATE >= DATE '2011-01-01' );
-- lignes migrant d'une partition à l'autre
-- on insére d'abord les lignes ayant migrées
INSERT INTO T_MESURE_APRES2010_MSR
SELECT NEW.MSR_ID,
NEW.MSR_DATE,
NEW.MSR_MESURE
WHERE NOT ( OLD.MSR_DATE < DATE '2011-01-01' );
-- puis supprime les lignes en migration dans chacune des partitions
-- d'abord dans la table d'avant l'an 2008
DELETE FROM T_MESURE_AVANT2008_MSR
WHERE MSR_ID = OLD.MSR_ID
AND MSR_DATE = OLD.MSR_DATE
AND MSR_MESURE = OLD.MSR_MESURE
AND OLD.MSR_DATE < '2008-01-01';
-- d'abord dans la table de l'an 2008
DELETE FROM T_MESURE_AN2008_MSR
WHERE MSR_ID = OLD.MSR_ID
AND MSR_DATE = OLD.MSR_DATE
AND MSR_MESURE = OLD.MSR_MESURE
AND OLD.MSR_DATE >= '2008-01-01'
AND OLD.MSR_DATE < '2009-01-01';
-- ensuite dans la table de l'an 2009
DELETE FROM T_MESURE_AN2009_MSR
WHERE MSR_ID = OLD.MSR_ID
AND MSR_DATE = OLD.MSR_DATE
AND MSR_MESURE = OLD.MSR_MESURE
AND OLD.MSR_DATE >= '2009-01-01'
AND OLD.MSR_DATE < '2010-01-01';
-- et enfin dans la table de l'an 2010
DELETE FROM T_MESURE_AN2010_MSR
WHERE MSR_ID = OLD.MSR_ID
AND MSR_DATE = OLD.MSR_DATE
AND MSR_MESURE = OLD.MSR_MESURE
AND OLD.MSR_DATE >= '2010-01-01'
AND OLD.MSR_DATE < '2011-01-01';
);
A ce stade force est de constater l’extrême complexité des règles dans le cas d’une possible migration de lignes d’une partition à l’autre… En effet le nombre d’ordre SQL dans chaque règle UPDATE est multiplié par le nombre de partitions… Pour 5 partitions, chacune des règles UPDATE doit inclure 7 commandes SQL… Bref, c’est l’explosion cartésienne. Ainsi avec 100 partitions, le nombre d’ordre SQL dans l’ensemble des règles à créer est de 104 x 100 = 10 400 ! Impensable…
De plus, comme PostGreSQL ne gère pas correctement les contraintes d’unicité (PRIMARY KEY, FOREIGN KEY) dans les mises à jour (pas de contraintes ensemblistes sauf à déroger en contraintes déferrée prévues dans une version future) il est hasardeux de partitionner sur une colonne susceptible de changer de valeur (en particulier erreur de saisie).
Reroutage des DELETEs :
DELETE avant 2008 :
CREATE RULE R_D_MSR_AVANT2008
AS
ON DELETE TO T_MESURE_MSR
WHERE ( OLD.MSR_DATE < DATE '2008-01-01' )
DO INSTEAD
DELETE FROM T_MESURE_AVANT2008_MSR
WHERE MSR_ID = OLD.MSR_ID
AND MSR_DATE = OLD.MSR_DATE
AND MSR_MESURE = OLD.MSR_MESURE ;
DELETE de 2008 :
CREATE RULE R_D_MSR_AN2008
AS
ON DELETE TO T_MESURE_MSR
WHERE ( OLD.MSR_DATE >= DATE '2008-01-01'
AND OLD.MSR_DATE < DATE '2009-01-01' )
DO INSTEAD
DELETE FROM T_MESURE_AN2008_MSR
WHERE MSR_ID = OLD.MSR_ID
AND MSR_DATE = OLD.MSR_DATE
AND MSR_MESURE = OLD.MSR_MESURE ;
DELETE de 2009 :
CREATE RULE R_D_MSR_AN2009
AS
ON DELETE TO T_MESURE_MSR
WHERE ( OLD.MSR_DATE >= DATE '2009-01-01'
AND OLD.MSR_DATE < DATE '2010-01-01' )
DO INSTEAD
DELETE FROM T_MESURE_AN2009_MSR
WHERE MSR_ID = OLD.MSR_ID
AND MSR_DATE = OLD.MSR_DATE
AND MSR_MESURE = OLD.MSR_MESURE ;
DELETE de 2010 :
CREATE RULE R_D_MSR_AN2010
AS
ON DELETE TO T_MESURE_MSR
WHERE ( OLD.MSR_DATE >= DATE '2010-01-01'
AND OLD.MSR_DATE < DATE '2011-01-01' )
DO INSTEAD
DELETE FROM T_MESURE_AN2010_MSR
WHERE MSR_ID = OLD.MSR_ID
AND MSR_DATE = OLD.MSR_DATE
AND MSR_MESURE = OLD.MSR_MESURE ;
DELETE après 2010 :
CREATE RULE R_D_MSR_APRES2010
AS
ON DELETE TO T_MESURE_MSR
WHERE ( OLD.MSR_DATE >= DATE '2011-01-01' )
DO INSTEAD
DELETE FROM T_MESURE_APRES2010_MSR
WHERE MSR_ID = OLD.MSR_ID
AND MSR_DATE = OLD.MSR_DATE
AND MSR_MESURE = OLD.MSR_MESURE ;
A ce stade tout semble parfait, sauf que si nous essayons d’insérer des données dans la table maître, alors nous sommes immédiatement informé d’une erreur particulièrement perverse… Par exemple avec l’insertion suivante :
INSERT INTO T_MESURE_MSR
VALUES (1, '2007-01-01', 33),
(2, '2007-03-01', 22),
(3, '2007-04-01', 44),
(4, '2008-02-01', 55),
(5, '2008-06-01', 66),
(6, '2008-10-01', 77),
(7, '2009-01-01', 99),
(8, '2009-06-01', 11),
(9, '2010-01-01', 88),
(10, '2010-06-01', 0);
PostGreSQL retourne l’erreur suivante :
ERREUR: récursion infinie détectée dans les règles de la relation « t_mesure_an2008_msr »
Que se passe t-il ?
En fait dans chaque règle, PostGreSQL, lorsqu’il ne sait pas quoi faire des lignes, tente de les insérer dans la table mère. Tant est si bien que chaque ligne qui n’est pas insérée par la règle dans les tables filles est renvoyée à la table mère, relançant ainsi l’insertion dans les tables fille par le biais des règles ad infinitum !
Il faut donc en sus interdire à la table mère de recevoir une quelconque ligne et cela ne peut se faire par une contrainte CHECK, car ce type de contrainte se propage dans les filles. Seule solution : rajouter un trigger dans la table mère !
3.1.5 – création de la fonction trigger et du trigger pour empêcher la récursion de l’insertion parasite
RETURNS TRIGGER AS
'
BEGIN
RAISE EXCEPTION ''Aucune ligne insérée dans la table mère'';
RETURN NULL;
END;
'
LANGUAGE 'plpgsql';
CREATE TRIGGER E_I_MSR
AFTER INSERT
ON T_MESURE_MSR
FOR EACH ROW EXECUTE PROCEDURE P_E_I_MSR ();
PARTITIONNEMENT DE TABLE version PostGreSQL – PREMIÈRE CONCLUSION
Comme on le voit, il faut répéter les prédicats de filtrage qui ont déjà été mis en place au niveau des contraintes CHECK.
Au niveau des règles pour update, la complexité est telle qu’aucun exemple sur le web ne m’a permis d’avancer sur le sujet et il m’a fallut une journée de tatonnerment après de multiples posts dans les forums restés sans réponse pour entrevoir une solution aucunement documentée.
Par conséquent, là aussi, le risque de se tromper est extrémement élevé, d’autant que le nombre de commandes et leur complexité est gigantesque et le code verbeux. Inutile de dire à quel point il est difficilement pensable de faire de nombreuses partitions avec la solution proposée par PostGreSQL.
En sus, il n’y a toujours aucun moyen de vérifier que les valeurs de partitionnement sont non recouvrantes (donc redondante) et ne laisse aucune valeur exclue.
Enfin, la réentrance des règles et l’obligation d’un trigger sur la table mère, pénalise fortement le traitement des mises à jour de données a tel point qu’on est en droit de se demander si il existe réellement un gain global quelconque dans le partitionnement toutes commandes SQL confondues (INSERT, UPDATE, DELETE, SELECT)…
4 – LA SOLUTION MS SQL SERVER
Nous avons laissé dans l’ombre le nom de la base SQL et sa création au niveau de PostGreSQL. Voici ce qu’il faut faire dans MS SQL Server, pour créer une base et se placer dans son contexte :
GO
USE DB_PART;
GO
4.1 РCr̩ation des espaces de stockage
4.1.1 Рcr̩ation des FILEGROUPs :
ALTER DATABASE DB_PART ADD FILEGROUP FG_PART1;
ALTER DATABASE DB_PART ADD FILEGROUP FG_PART2;
ALTER DATABASE DB_PART ADD FILEGROUP FG_PART3;
ALTER DATABASE DB_PART ADD FILEGROUP FG_PART4;
4.1.2 Рcr̩ation des fichiers de stockage, dans les espaces pr̩alablement cr̩̩es :
ALTER DATABASE DB_PART
ADD FILE (NAME = 'F_PART0',
FILENAME = 'E:\SQLDATA\PARTMSR0\F_DB_PART_0.ndf',
SIZE = 1 GB,
FILEGROWTH = 50 MB)
TO FILEGROUP FG_PART0;
ALTER DATABASE DB_PART
ADD FILE (NAME = 'F_PART1',
FILENAME = 'F:\SQLDATA\PARTMSR1\F_DB_PART_1.ndf',
SIZE = 1 GB,
FILEGROWTH = 50 MB)
TO FILEGROUP FG_PART1;
ALTER DATABASE DB_PART
ADD FILE (NAME = 'F_PART2',
FILENAME = 'G:\SQLDATA\PARTMSR2\F_DB_PART_2.ndf',
SIZE = 1 GB,
FILEGROWTH = 50 MB)
TO FILEGROUP FG_PART2;
ALTER DATABASE DB_PART
ADD FILE (NAME = 'F_PART3',
FILENAME = 'H:\SQLDATA\PARTMSR3\F_DB_PART_3.ndf',
SIZE = 1 GB,
FILEGROWTH = 50 MB)
TO FILEGROUP FG_PART3;
ALTER DATABASE DB_PART
ADD FILE (NAME = 'F_PART4',
FILENAME = 'I:\SQLDATA\PARTMSR4\F_DB_PART_4.ndf',
SIZE = 1 GB,
FILEGROWTH = 50 MB)
TO FILEGROUP FG_PART4;
4.2 Рcr̩ation de la fonction de partitionnement :
C’est celle qui fixe les piquets….
CREATE PARTITION FUNCTION F_P_MSR_DATE (date)
AS RANGE LEFT
FOR VALUES ('2008-01-01', '2009-01-01', '2010-01-01', '2011-01-01');
La fonction intègre 4 valeurs pivot et nécessitera donc 5 espaces de stockage pour les données de -∞ à +∞
Son paramètre est un type de données et non une variable. La variables sera la colonne de partitionnement de la table.
Notez que les valeurs piquet seront stockées à gauche (RANGE LEFT) dans chacun des intervalles.
4.3 Рcr̩ation du sch̩ma de partitionnement
C’est celle qui fixe les espaces de stockage pour chacun des intervalles de valeurs.
Le schéma de partitionnement fait référence à la fonction de partitionnment définie ci avant et indique les espaces de stockage :
CREATE PARTITION SCHEME F_S_MSR_DATE
AS PARTITION F_P_MSR_DATE
TO (FG_PART0, FG_PART1, FG_PART2, FG_PART3, FG_PART4);
4.4 РCr̩ation de la table partitionn̩e
CREATE TABLE T_MESURE_MSR
(
MSR_ID INT not null,
MSR_DATE date not null,
MSR_MESURE int
) ON F_S_MSR_DATE (MSR_DATE);
La table est créée en indiquant dans quoi elle réside (ON) et cette résidence est un ensemble de partitions déterminées par la fonction de partitionnement (F_P_MSR_DATE) associé au schéma de partitionnement (F_S_MSR_DATE) appliqué à la colonne MSR_DATE.
PARTITIONNEMENT DE TABLE version MS SQL Server – PREMIÈRE CONCLUSION
Comme on le voit, la solution de mise en Å“uvre sous MS SQL Server est d’une grande simplicité et ne laisse aucune zone d’ombre. Il est impossible de faire des partitions trouées ou se chevauchant et le code à mettre en oeuvre est on ne peut plus laconique.
Aucune requête ni trigger ni règles d’aucune sorte n’est à coder, car tout est fait en interne par le moteur SQL.
Seule différence notable, la gestion des espaces de stockage, plus complexe car beaucoup plus précise (réservation d’espace, méthode de croisssance…) que sous PostGreSQL ou elle est embryonnaire, mais là encore nous avons voulu être exhaustif en supposant que l’intérêt du partitionnement réside grandement dans la ventilation des IO sur différents espaces de stockage. Si tel n’était pas l’intérêt de notre utilisateur, alors la partie 4.1 du code est à supprimer et la création du schéma de partitionnement peut se résumer à :
AS PARTITION F_P_MSR_DATE
ALL TO (PRIMARY);
Ou PRIMARY est le nom de l’espace de stockage par défaut, mais on peut spécifier tout autre espace.
5 – MANIPULER LES DONNÉES D’UNE TABLE PARTITIONNÉE
Ce n’est pas tout de créer une table partitionnée, encore faut-il qu’elle vive. Nous allons donc étudier différentes opérations sur une telle table et leur conséquence sur la table.
5.1 – les insertions
INSERT INTO T_MESURE_MSR
VALUES (1, '2007-01-01', 33),
(2, '2007-03-01', 22),
(3, '2007-04-01', 44),
(4, '2008-02-01', 55),
(5, '2008-06-01', 66),
(6, '2008-10-01', 77),
(7, '2009-01-01', 99),
(8, '2009-06-01', 11),
(9, '2010-01-01', 88),
(10, '2010-06-01', 0);
Dans PostGreSQL, les lignes sont bien ventilées dans les tables filles, mais elle apparaissent aussi dans la table mère sans qu’il soit possible de dire si ces lignes sont physiquement présente dans la table mère ou si elles n’existent réellement que dans les filles.
Seul le plan de requête d’un SELECT * FROM T_MESURE_MSR nous indique ce que fait réellement PG, c’est à dire une collecte des lignes de toutes les tables filles :
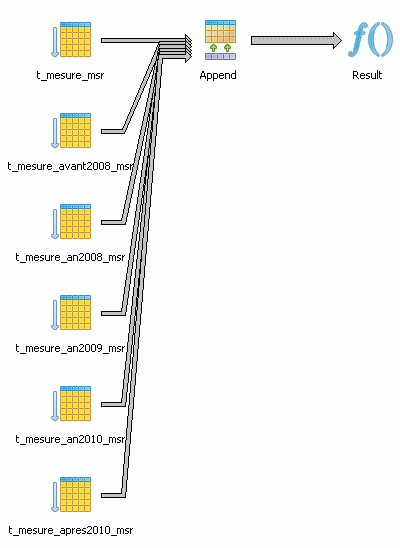
Si les lignes étaient aussi stockées dans la table mère nous verrions une redondance de ces lignes, ce qui n’est pas le cas.
Dans SQL Server, les lignes sont bien ventilées dans les différentes partitions, et il est possible directement dans la requête SQL de savoir à l’aide d’un appel particulier à la fonction de partitionnement de savoir ou chacune des lignes figurent :
SELECT *,
$PARTITION.F_P_MSR_DATE(MSR_DATE) AS NUMERO_PARTITION
FROM T_MESURE_MSR
Pour ce faire on apelle la fonction de partition sur la colonne de partitionnement depuis un schéma virtuel de nom $PARTITION.
MSR_ID MSR_DATE MSR_MESURE NUMERO_PARTITION
----------- ---------- ----------- ----------------
1 2007-01-01 33 1
2 2007-03-01 22 1
3 2007-04-01 44 1
4 2008-02-01 55 2
5 2008-06-01 66 2
6 2008-10-01 77 2
7 2009-01-01 99 2
8 2009-06-01 11 3
9 2010-01-01 88 3
10 2010-06-01 0 4
5.2 – Les extractions
5.1.1 – Recherche de ligne unique
C’est le cas de la requête retrouvant une ligne précisée sur le critère de partitionnement.
C’est par exemple la requête suivante :
SELECT *
FROM T_MESURE_MSR
WHERE MSR_DATE = '2009-06-01'
Que le SGBDR doit retrouver dans la bonne partition.
Pour SQL Server le plan de requête indique bien qu’il cherche dans une seule partition.
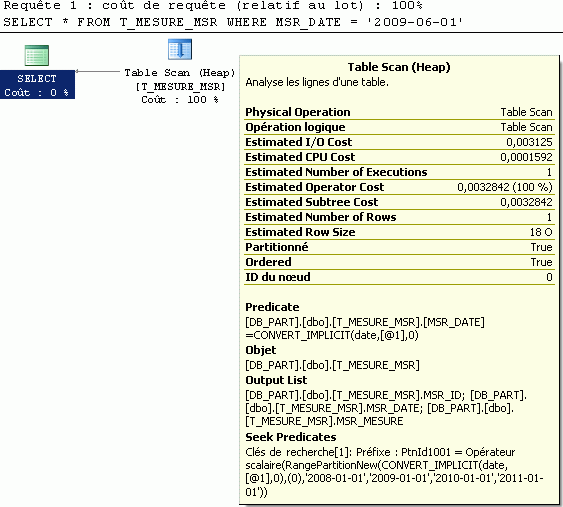
PtnId1001 = Opérateur scalaire(RangePartitionNew(… signifie qu’il cherche la valeur dans une partition.
Pour postGreSQL et à condition qu’il soit correctement paramétré (à défaut depuis la version 8.4), le plan montre que PostGreSQL va scruter deux éléments : la bonne partition, mais aussi la table mère…
Dans le cas ou le paramétrage est incorrect :
SET CONSTRAINT_EXCLUSION = OFF;
L’optimiseur est incapable de trouver directement la partition adéquate…
Bien entendu la recherche d’une ligne unique sur autre chose que le critère de partitionnement nécessite le parcours de toutes les partitions, que ce soit avec PostGreSQL ou MS SQL Server.
5.1.2 – Recherche de plusieurs lignes
C’est le cas d’une requête indiquant une plage de valeur, par exemple avec un IN ou un BETWEEN.
Par exemple, la requête suivante :
SELECT *
FROM T_MESURE_MSR
WHERE MSR_DATE BETWEEN '2008-02-01' AND '2009-06-01'
Le plan de requête PostGreSQL prend bien en compte les deux partitions, mais y ajoute toujours inutilement la table mère :
Rappelons pour information que cette table ne peut contenir aucune ligne puisqu’un trigger l’y empêche. La scrutation de cette table est donc parfaitement inutile et fait perdre du temps de traitement !
La plan de requête MS SQL Server est plus direct, ne s’intéressant qu’aux partitions de l’intervalle :

C’est plus explicite sur le détail du plan de requête fournit en XML (On l’obtient en cliquant droit sur le plan graphique et en choisissant « afficher le fichier XML du plan d’exécution »)
5.3 – Les suppressions
Avec la simple requête suivante :
DELETE FROM T_MESURE_MSR WHERE MSR_DATE = '2008-02-01'
PostGreSQL semble perdu. Le plan graphique est incompréhensible :
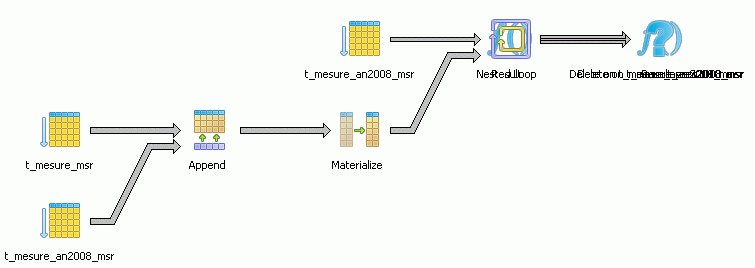
Et sa version textuelle, montre un comportement vraiment bizarre :
Delete on t_mesure_an2008_msr (cost=0.00..114.40 rows=1 width=16)
-> Nested Loop (cost=0.00..114.40 rows=1 width=16)
Join Filter: ((t_mesure_an2008_msr.msr_id = public.t_mesure_msr.msr_id) AND (t_mesure_an2008_msr.msr_mesure = public.t_mesure_msr.msr_mesure))
-> Seq Scan on t_mesure_an2008_msr (cost=0.00..32.13 rows=9 width=22)
Filter: (msr_date = '2008-02-01'::date)
-> Materialize (cost=0.00..81.96 rows=2 width=26)
-> Append (cost=0.00..81.95 rows=2 width=26)
-> Seq Scan on t_mesure_msr (cost=0.00..40.98 rows=1 width=26)
Filter: ((msr_date >= '2008-01-01'::date) AND (msr_date < '2009-01-01'::date) AND (msr_date = '2008-02-01'::date))
-> Seq Scan on t_mesure_an2008_msr t_mesure_msr (cost=0.00..40.98 rows=1 width=26)
Filter: ((msr_date >= '2008-01-01'::date) AND (msr_date < '2009-01-01'::date) AND (msr_date = '2008-02-01'::date))
Delete on t_mesure_an2009_msr (cost=0.00..0.01 rows=1 width=0)
-> Result (cost=0.00..0.01 rows=1 width=0)
One-Time Filter: false
Delete on t_mesure_an2010_msr (cost=0.00..0.01 rows=1 width=0)
-> Result (cost=0.00..0.01 rows=1 width=0)
One-Time Filter: false
Delete on t_mesure_apres2010_msr (cost=0.00..0.01 rows=1 width=0)
-> Result (cost=0.00..0.01 rows=1 width=0)
One-Time Filter: false
Delete on t_mesure_avant2008_msr (cost=0.00..0.01 rows=1 width=0)
-> Result (cost=0.00..0.01 rows=1 width=0)
One-Time Filter: false
Result (cost=0.00..0.01 rows=1 width=0)
One-Time Filter: false
En fait on s’aperçoit que le plan scrute toutes les partitions… Dès lors quel est le gain d’un DELETE ?
Le plan de requête de MS SQL Server est plus conforme à ce à quoi nous nous atendions puisqu’il ne scrute qu’une seule partition. Le voici sous forme textuelle :
StmtText
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
|--Table Delete(OBJECT:([DB_PART].[dbo].[T_MESURE_MSR]))
|--Top(ROWCOUNT est 0)
|--Table Scan(OBJECT:([DB_PART].[dbo].[T_MESURE_MSR]), SEEK:([PtnId1001]=RangePartitionNew(CONVERT_IMPLICIT(date,[@1],0),(0),'2008-01-01','2009-01-01','2010-01-01','2011-01-01')), WHERE:([DB_PART].[dbo].[T_MESURE_MSR].[MSR_DATE]=CONVERT_IMPLICIT(date,[@1],0)) ORDERED FORWARD)
Et son image graphique :

5.4 – les modifications
Voyons maintenant le cas d’un UPDATE et analysons ce qui se passe sans changement de partitions puis avec.
Premier exemple :
UPDATE T_MESURE_MSR
SET MSR_DATE = '2007-06-20'
WHERE MSR_DATE = '2007-01-01'
À nouveau PostGreSQL semble perdu alors qu’il n’a qu’une seule partition à scruter. Le plan graphique est encore plus immonde :
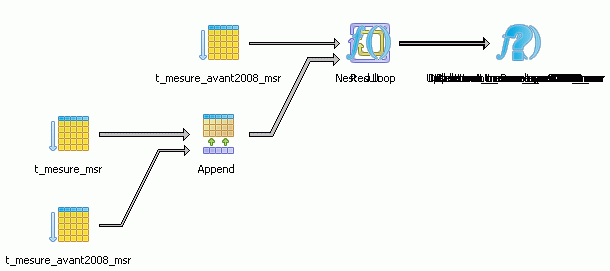
C’est le résultat hélas catastrophique des règles nécessaires à la mise en place du partitionnement. Le plan textuel est monstrueux :
Update on t_mesure_an2008_msr (cost=0.00..0.01 rows=1 width=0)
-> Result (cost=0.00..0.01 rows=1 width=0)
One-Time Filter: false
Insert on t_mesure_an2008_msr (cost=0.00..0.01 rows=1 width=0)
-> Result (cost=0.00..0.01 rows=1 width=0)
One-Time Filter: false
Delete on t_mesure_avant2008_msr (cost=0.00..0.01 rows=1 width=0)
-> Result (cost=0.00..0.01 rows=1 width=0)
One-Time Filter: false
Delete on t_mesure_an2009_msr (cost=0.00..0.01 rows=1 width=0)
-> Result (cost=0.00..0.01 rows=1 width=0)
One-Time Filter: false
Delete on t_mesure_an2010_msr (cost=0.00..0.01 rows=1 width=0)
-> Result (cost=0.00..0.01 rows=1 width=0)
One-Time Filter: false
Delete on t_mesure_apres2010_msr (cost=0.00..0.01 rows=1 width=0)
-> Result (cost=0.00..0.01 rows=1 width=0)
One-Time Filter: false
Update on t_mesure_an2009_msr (cost=0.00..0.01 rows=1 width=0)
-> Result (cost=0.00..0.01 rows=1 width=0)
One-Time Filter: false
Delete on t_mesure_avant2008_msr (cost=0.00..0.01 rows=1 width=0)
-> Result (cost=0.00..0.01 rows=1 width=0)
One-Time Filter: false
Delete on t_mesure_an2008_msr (cost=0.00..0.01 rows=1 width=0)
-> Result (cost=0.00..0.01 rows=1 width=0)
One-Time Filter: false
Delete on t_mesure_an2010_msr (cost=0.00..0.01 rows=1 width=0)
-> Result (cost=0.00..0.01 rows=1 width=0)
One-Time Filter: false
Delete on t_mesure_apres2010_msr (cost=0.00..0.01 rows=1 width=0)
-> Result (cost=0.00..0.01 rows=1 width=0)
One-Time Filter: false
Insert on t_mesure_an2009_msr (cost=0.00..0.01 rows=1 width=0)
-> Result (cost=0.00..0.01 rows=1 width=0)
One-Time Filter: false
Update on t_mesure_an2010_msr (cost=0.00..0.01 rows=1 width=0)
-> Result (cost=0.00..0.01 rows=1 width=0)
One-Time Filter: false
Delete on t_mesure_avant2008_msr (cost=0.00..0.01 rows=1 width=0)
-> Result (cost=0.00..0.01 rows=1 width=0)
One-Time Filter: false
Delete on t_mesure_an2008_msr (cost=0.00..0.01 rows=1 width=0)
-> Result (cost=0.00..0.01 rows=1 width=0)
One-Time Filter: false
Delete on t_mesure_an2009_msr (cost=0.00..0.01 rows=1 width=0)
-> Result (cost=0.00..0.01 rows=1 width=0)
One-Time Filter: false
Delete on t_mesure_apres2010_msr (cost=0.00..0.01 rows=1 width=0)
-> Result (cost=0.00..0.01 rows=1 width=0)
One-Time Filter: false
Insert on t_mesure_an2010_msr (cost=0.00..0.01 rows=1 width=0)
-> Result (cost=0.00..0.01 rows=1 width=0)
One-Time Filter: false
Update on t_mesure_apres2010_msr (cost=0.00..0.01 rows=1 width=0)
-> Result (cost=0.00..0.01 rows=1 width=0)
One-Time Filter: false
Delete on t_mesure_avant2008_msr (cost=0.00..0.01 rows=1 width=0)
-> Result (cost=0.00..0.01 rows=1 width=0)
One-Time Filter: false
Delete on t_mesure_an2008_msr (cost=0.00..0.01 rows=1 width=0)
-> Result (cost=0.00..0.01 rows=1 width=0)
One-Time Filter: false
Delete on t_mesure_an2009_msr (cost=0.00..0.01 rows=1 width=0)
-> Result (cost=0.00..0.01 rows=1 width=0)
One-Time Filter: false
Delete on t_mesure_an2010_msr (cost=0.00..0.01 rows=1 width=0)
-> Result (cost=0.00..0.01 rows=1 width=0)
One-Time Filter: false
Insert on t_mesure_apres2010_msr (cost=0.00..0.01 rows=1 width=0)
-> Result (cost=0.00..0.01 rows=1 width=0)
One-Time Filter: false
Update on t_mesure_avant2008_msr (cost=0.00..38.59 rows=4 width=28)
-> Nested Loop (cost=0.00..38.59 rows=4 width=28)
-> Seq Scan on t_mesure_avant2008_msr (cost=0.00..1.00 rows=1 width=6)
-> Append (cost=0.00..37.55 rows=4 width=22)
-> Seq Scan on t_mesure_msr (cost=0.00..36.55 rows=3 width=22)
Filter: ((msr_date < '2008-01-01'::date) AND (msr_date = '2007-01-01'::date))
-> Seq Scan on t_mesure_avant2008_msr t_mesure_msr (cost=0.00..1.00 rows=1 width=22)
Filter: ((msr_date < '2008-01-01'::date) AND (msr_date = '2007-01-01'::date))
Delete on t_mesure_an2008_msr (cost=0.00..0.01 rows=1 width=0)
-> Result (cost=0.00..0.01 rows=1 width=0)
One-Time Filter: false
Delete on t_mesure_an2009_msr (cost=0.00..0.01 rows=1 width=0)
-> Result (cost=0.00..0.01 rows=1 width=0)
One-Time Filter: false
Delete on t_mesure_an2010_msr (cost=0.00..0.01 rows=1 width=0)
-> Result (cost=0.00..0.01 rows=1 width=0)
One-Time Filter: false
Delete on t_mesure_apres2010_msr (cost=0.00..0.01 rows=1 width=0)
-> Result (cost=0.00..0.01 rows=1 width=0)
One-Time Filter: false
Insert on t_mesure_avant2008_msr (cost=0.00..0.01 rows=1 width=0)
-> Result (cost=0.00..0.01 rows=1 width=0)
One-Time Filter: false
Result (cost=0.00..0.01 rows=1 width=0)
One-Time Filter: false
Tandis que sous MS SQL Server il reste relativement simple :

Deuxième exemple :
UPDATE T_MESURE_MSR
SET MSR_DATE = '2009-06-20'
WHERE MSR_DATE = '2007-01-01'
LÃ il y a changement de partition.
PostGreSQL se complique encore plus…
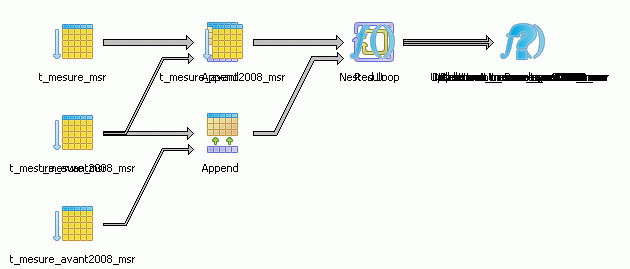
Je vous passerai les détails du plan textuel qui est comparable au précédent avec une instruction de plus…
Tandis que celui de SQL Server ne change pas d’un iota !
6 – LA VIE D’UNE TABLE PARTITIONNÉE
Dans la vraie vie, il arrive qu’une table ne soit pas parfaite du premier coup. Il faut donc en remanier la structure afin de la rendre plus fonctionnelle qu’elle ne l’était auparavant. De telles manipulations sont fréquentes et même les grosses tables partitionnées n’y échappent pas.
Parmi les choses les plus couramment entreprises, il y a :
- l’ajout ou la suppression d’un index
- l’ajout d’une colonne
- l’ajout d’une clef (primaire ou unique)
- l’ajout d’une contrainte de validation
- l’ajout d’une contrainte d’intégrité référentielle.
C’est ce que nous allons maintenant tester…
6.1 – ajouter un index
Dans MS SQL Server on peut avoir une table partitionnée, sans que les index le soit, tout comme on peut choisir d’aligner les index et encore pour certains et pas tous.
Voici le création d’un index non partitionné sur la colonne MSR_MESURE :
CREATE INDEX X_MSR_MSR ON T_MESURE_MSR (MSR_MESURE);
Voici maintenant un index similaire, partitionné (il doit inclure la colonne de partitionnement dans la clause INCLUDE) :
CREATE INDEX X_MSR_MSR_P ON T_MESURE_MSR (MSR_MESURE) INCLUDE (MSR_DATE) ON F_S_MSR_DATE (MSR_DATE);
Pour PostGreSQL, la création d’un index au niveau de la table mère ne propage pas l’index dans les filles.
Pour le voir, il suffit de lister les index des tables à l’aide de la requête suivante :
SELECT S.nspname as TABLE_SCHEMA,
T.relname as TABLE_NAME,
CI.relname as INDEX_NAME
FROM pg_catalog.pg_class AS CI
INNER JOIN pg_catalog.pg_index I
ON I.indexrelid = CI.oid
INNER JOIN pg_catalog.pg_class AS T
ON I.indrelid = T.oid
LEFT OUTER JOIN pg_catalog.pg_namespace AS S
ON S.oid = CI.relnamespace
WHERE S.nspname NOT IN ('pg_catalog', 'pg_toast')
AND pg_catalog.pg_table_is_visible(CI.oid)
ORDER BY 1,2;
Il faut donc créer autant d’index qu’il y a de tables filles…
CREATE INDEX X_MSR2008_MSR_DATE ON T_MESURE_AN2008_MSR (MSR_DATE);
CREATE INDEX X_MSR2009_MSR_DATE ON T_MESURE_AN2009_MSR (MSR_DATE);
CREATE INDEX X_MSR2010_MSR_DATE ON T_MESURE_AN2010_MSR (MSR_DATE);
CREATE INDEX X_MSR2011_MSR_DATE ON T_MESURE_APRES2010_MSR (MSR_DATE);
Encore une fois on multiplie les commandes par le nombre de partitions.
Le seul avantage est qu’il est possible d’indexer une partition et pas l’autre. C’est pratique lorsque l’on a des données anciennes en quantité qui sont rarement scrutées. Mais SQL Server permet de faire la même chose via un index filtré. Par exemple celui-ci :
CREATE INDEX X_MSR_MSR ON T_MESURE_MSR (MSR_MESURE) WHERE ( MSR_DATE > ‘2011-01-01′ );
Et vous noterez que c’est encore plus simple, car il n’y a besoin que de créer toujours qu’un seul index.
6.2 – Ajouter une colonne
ADD COLUMN MSR_HEURE TIME;
Pour PostGreSQL, la nouvelle colonne MSR_TIME, créée au niveau de la mère est propagée dans toutes les tables filles. Mais il en résulte au final 6 exécutions de commandes ALTER.
Pour le voir :
SELECT TABLE_SCHEMA, TABLE_NAME, COLUMN_NAME
FROM INFORMATION_SCHEMA.COLUMNS
WHERE COLUMN_NAME = 'msr_heure'
ORDER BY 1, 2, 3;
Ou encore :
SELECT S.nspname AS TABLE_SCHEMA,
T.relname AS TABLE_NAME,
C.attname AS COLUMN_NAME
FROM pg_catalog.pg_class AS T
INNER JOIN pg_catalog.pg_namespace AS S
ON T.relnamespace = S.oid
INNER JOIN pg_catalog.pg_attribute AS C
ON T.oid = C.attrelid
WHERE relkind = 'r'
AND nspname = 'public'
AND C.attname = 'msr_heure'
Sous SQL Server s’agissant d’une seule table il n’y a aucune ambiguïté et un seul ALTER est déclenché.
6.3 – Ajout d’une clef
ADD CONSTRAINT PK_MSR_ID
PRIMARY KEY (MSR_ID);
L’ajout d’une clef primaire se passe bien dans PostGreSQL, trop bien même… Car cette clef est purement cosmétique. En effet elle est bien créée dans la table mère, mais n’est pas propagée dans les filles !
Et bien entendu elle ne sert à rien….
Exemple :
INSERT INTO T_MESURE_MSR
VALUES (1, '2007-01-01', 33),
(1, '2008-01-01', 22),
(1, '2009-01-01', 11);
Dans SQL Server, la création d’une clef se passe mal :
Msg 1908, Niveau 16, État 1, Ligne 1
‘MSR_DATE’ est une colonne de partition de l’index ‘PK_MSR_ID’. Les colonnes de partition d’un index unique doivent être un sous-ensemble de la clé d’index.
Msg 1750, Niveau 16, État 0, Ligne 1
Impossible de créer la contrainte. Voir les erreurs précédentes.
En fait SQL Server exige que la clef fasse partie du critère de partitionnement. En fait il est même fortement recommandées de faire sa partition sur la clef de la table.
C’est une contrainte lourde dans le sens ou il faut le prendre en compte au moment de la conception de la base…
6.4 – Ajout d’une contrainte de validation
ALTER TABLE T_MESURE_MSR
ADD CONSTRAINT CK_MSR_MSR_POSITIF
CHECK(MSR_MESURE >= 0);
Dans PostGreSQL, la nouvelle contrainte CHECK se propage dans les tables filles. Il en résulte aussi 6 exécutions de commandes ALTER.
Sous SQL Server s’agissant d’une seule table il n’y a aucune ambiguïté et un seul ALTER est déclenché.
6.5 – Ajout d’une contrainte d’intégrité
CREATE TABLE T_UNITE_UNT
(UNT_ID INT PRIMARY KEY,
UNT_LIBELLE VARCHAR(32))
ALTER TABLE T_MESURE_MSR
ADD COLUMN UNT_ID INT
REFERENCES T_UNITE_UNT (UNT_ID);
Sous PostGreSQL, l’ajout complet (colonne et contrainte d’IR) ne se fait qu’au niveau de la table mère. Cependant la colonne est créée dans toutes les tables filles. Il faut donc rajouter la contrainte d’intégrité manuellement à toutes les filles.
ALTER T_MESURE_AVANT2008_MSR
ADD CONSTRAINT FK_MSR_UNTAV8
FOREIGN KEY (UNT_ID)
REFERENCES T_UNITE_UNT (UNT_ID);
ALTER T_MESURE_AN2008_MSR
ADD CONSTRAINT FK_MSR_UNTA8
FOREIGN KEY (UNT_ID)
REFERENCES T_UNITE_UNT (UNT_ID);
ALTER T_MESURE_AN2009_MSR
ADD CONSTRAINT FK_MSR_UNTA9
FOREIGN KEY (UNT_ID)
REFERENCES T_UNITE_UNT (UNT_ID);
ALTER T_MESURE_AN2010_MSR
ADD CONSTRAINT FK_MSR_UNTAN10
FOREIGN KEY (UNT_ID)
REFERENCES T_UNITE_UNT (UNT_ID);
ALTER T_MESURE_APRES2010_MSR
ADD CONSTRAINT FK_MSR_UNTAP10
FOREIGN KEY (UNT_ID)
REFERENCES T_UNITE_UNT (UNT_ID);
Sous SQL Server s’agissant d’une seule table il n’y a aucune ambiguïté et un seul ALTER est déclenché.
7 – PARTITIONNEMENT MULTICOLONNE
La partitionnement sur de multiples colonnes ne pose pas de problème sous PostGreSQL, mais il en résulte des requêtes très complexes à écrire pour les règles de mise à jour, comme pour les filtres de partitionnement, car il faut tenir compte de la vectorisation des informations (cela est facilité par le Row Value Constructor). Il est en revanche un peu plus limité sous MS SQL Server, car il faut créer une colonne calculée persistante, pour « réduire » la composition du critère de partitionnement à une seule valeur.
Voici un exemple, avec un partitionnement sur deux colonnes, l’une de type DATE l’autre de type TIME :
Création de la fonction de partitionnement :
CREATE PARTITION FUNCTION F_P_MSR_DATETIME (datetime)
AS RANGE LEFT
FOR VALUES ('2000-01-01', '2001-01-01', '2002-01-01', '2003-01-01');
Création du schéma de paritionnement, faisant référence à la fonction de partitionnment définie ci avant :
CREATE PARTITION SCHEME F_S_MSR_DATETIME
AS PARTITION F_P_MSR_DATETIME
TO (FG_PART0, FG_PART1, FG_PART2, FG_PART3, FG_PART4);
Création de la table partitionnée :
CREATE TABLE T_MESURE_2_MSR
(
MSR_ID INT not null,
MSR_DATE date not null,
MSR_TIME TIME NOT NULL,
MSR_MESURE int,
MSR_DATETIME AS CAST(MSR_DATE AS DATETIME) + MSR_TIME PERSISTED
) ON F_S_MSR_DATETIME (MSR_DATETIME);
8 – CONCLUSION PARTITIONNEMENT PostGreSQL vs MS SQL Server
Il faut bien constater que la mise en Å“uvre du partitionnement sous PostGreSQL est très complexe et quasi infaisable en production si l’on veut plus d’une dizaine de partitions. En outre, le risque de se tromper dans les très nombreuses requêtes et pire encore par un mauvais découpage des partitions entrainant des chevauchements ou des trous, est extrêmement élevé.
Il semble bien que le partitionnement sur PG n’est encore qu’embryonnaire et brouillon, et tout doit être fait à la main. En effet contrairement aux solutions de SQL Server ou Oracle, chacune des partitions est en fait une table indépendant sur laquelle il faut appliquer certaines commandes DDL sur toutes les partitions, si vous voulez que vos différentes partitions (en fait des tables) aient la même structure (colonnes, contraintes, index…). Avec un grand nombre de partitions, le nombre de commande à passer explose très vite. Nous avons dénombré plus de 10 000 ordres SQL pour la mise en place de 100 partitions !
De plus, du fait des règles, les plans de requête de PostGreSQL, concernant les ordres de mise à jour des données, sont d’une grande complexité et il en résulte fatalement des performances à la baisse alors que c’est l’inverse que l’on cherche dans le partitionnement !
L’oubli de paramétrer le serveur pour qu’il tienne compte des avantages des contraintes de validation pour utiliser les partition, n’est qu’un petit dommage que le DBA réparera bien vite :
SET CONSTRAINT_EXCLUSION = ON (ou PARTITION qui est la valeur par défaut à partir de la version 8.4).
Plus embêtant sont les scrutations inutiles de la table mère alors qu’elle est toujours vides par le fait du trigger;
Le seul point négatif que nous avons relevé chez MS SQL Server, en dehors du bug de l’assistant de mise en place des partitions dans l’interface SSMS (SQL Server Management Studio) est l’incapacité à placer une clef primaire ou unique indépendante du critère de partitionnement. Ce n’est pas un point bloquant, mais mieux vaut le prendre en compte au niveau de la conception de la base qu’après la mise en production.
Nous avons dit que la gestion des espaces de stockage PostGreSQL était encore aussi embryonnaire. C’est bien dommage car un partitionnement sans cela présente en définitive peu d’intérêt. Dans une bonne gestion des espaces de stockage, comme c’est le cas d’Oracle ou SQL Server, il est possible par exemple de pré réserver de l’espace pour stocker les données sur les fichiers de stockage des différentes tables de partitionnement. Cela permet de ventiler les IO et d’éviter les opérations de croissances de fichiers qui sont horriblement couteuses pour les transactions. Ce manque fait que PostGreSQL fera de l’autocroissance, entrainant des délais erratiques pour certaines requêtes de mise à jour en sus de n’être pas folichon du fait de la fragmentation physique des fichiers qui en résultera !
Pour terminer il est extrêmement difficile de gérer les partitions au niveau du stockage sous PostGreSQL. Par exemple pour migrer les données d’une partition d’un espace de stockage à l’autre dans PostGreSQL, il faut :
1) démarrez une transaction au niveau SERIALIZABLE
2) créer une nouvelle table fille dans cet espace de stockage
3) migrer les données par un UPDATE
4) supprimer les données de l’ancienne table
5) ajouter les index
6) ajouter les règles
7) modifier la vue
8) terminez la transaction
Et j’avoue ne pas avoir testé ce qui se passerait si une telle table est une référence d’intégrité…
Bien entendu s’il s’agit de migrer toutes les données, c’est faisable par un seule ALTER TABLE… Mais le cas dont nous parlons est par exemple celui du scindage d’une partition en deux…
En comparaison, sous MS SQL Server toute manipulation du stockage des partitions se fait en une seule commande :
ALTER TABLE … SWITCH PARTITION …
En sus on peut en une seule commande sous MS SQL Server fusionner ou scinder une partition :
ALTER PARTITION … SPLIT RANGE …
ALTER PARTITION … MERGE RANGE …
Et ces commandes agissent à bas niveau en arrière plan, sans que les utilisateurs en soient grandement incommodés, ce qui n’est pas le cas dans PostGreSQL, puisque les lignes devant être physiquement détruites, aucune transaction ni lecture ne peut s’effectuer pendant une telle migration.
Bref, pour ma part je considère que la partitionnement selon PostGreSQL n’est pas loin d’être un fiasco. C’est pour le moins une chose à éviter…
D’ailleurs conscient que la méthode de partitionnement n’est pas des plus aisée et présente de nombreuses failles, PostGreSQL envisage une autre solution plus proche de celle adoptée par SQL Server. À lire : « Table partitioning ». Mais comme le dit cet article « They are hard to fix in 9.0, but should continue to be improved in the future releases.« . En tout cas, cette technique n’est toujours pas présente dans la version 9.1 de PostGreSQL…
Pour information voici les déboires qui arrive en production à qui veut s’aventurer dans le partitionnement sous PG : Partitions and joins lead to index lookups on all partitions. Bref, dans ce cas pratique, le partitionnement conduit à des requêtes 36 fois moins rapide que sans partitionnement, alors que c’est l’effet inverse qui devrait en résulter !
--------
Frédéric Brouard, SQLpro - ARCHITECTE DE DONNÉES, http://sqlpro.developpez.com/
Expert bases de données relationnelles et langage SQL. MVP Microsoft SQL Server
www.sqlspot.com : modélisation, conseil, audit, optimisation, tuning, formation
* * * * * Enseignant CNAM PACA - ISEN Toulon - CESI Aix en Provence *
Ci joint les commentaires de scheu postés à l’origine dans ce message
Le peu que j’avais testé du partitionnement sous Postgresql m’avait amené à la même conclusion que toi : une usine à gaz difficile à maintenir et impensable dans un environnement de production
Pour compléter ton article, tu aurais aussi pu parler des performances en insertion : j’avais fait il y a quelques années un bench entre Oracle 10g et Postgresql 8.2, et pour une boucle d’insert ligne à ligne dans une table partitionnée, c’était 2 fois plus long sous Postgresql (sans doute à cause de tous les triggers et contraintes à vérifier à chaque insert)
Ca pourrait être intéressant de comparer les temps entre Postgresql et SQL Server
Également pour aller plus loin sur les plans d’exécution, sous Postgresql pour que le plan d’exécution ne lise que la bonne partition (et pas toutes les autres), il faut faire un filtre direct sur la table (ex : « where col_date = ‘2010-01-05′ »).
Mais dès l’instant où le filtre sur ta clé de partitionnement est issu d’une condition de jointure, ça ne marche pas la plupart du temps, et Postgresql parcourt toutes les partitions.
Exemple avec « table1″ partitionnée par mois sur col_date et une requête du style « where table1.col_date = table2.col_date and table2.col_date = ‘2010-01-05′ » : Postgresql 8.2 parcourt toutes les partitions de « table1″ et non pas seulement celle correspondante à janvier 2010
Alors qu’Oracle (et aussi SQL Server j’imagine) est capable par association d’en déduire table1.col_date=’2010-01-05′ et de ne lire que la partition de janvier 2010
J’ai rencontré plusieurs fois ces problèmes de mauvais plans d’exécution en Postgresql 8.2, je n’ai pas testé si c’était toujours le cas dans les dernières versions