Qui n’a jamais rêvé d’obtenir des performances pour rechercher des mots partiels contenus dans d’autres mots, comme par exemple tous les mots contenant « bolo » ? Dans un dictionnaire de 128 918 mots, une telle recherche met moins de 50 millisecondes à l’aide des index rotatifs, contre ??? pour le LIKE ‘%bolo%’… Explications…
diabolos, hyperboloïde, bolonaise, bolomètre, diabolo, bolométriques, amphibologie, bolonais, paraboloïde, amphibologique, bolométrique… Tels sont les mots du dictionnaire LEXIQUE du CNRS contenant la chaine de caractères « boblo ».
LE PROBLÈME
Les index des bases de données relationnelles, de type BTree (arbre équilibrés) trient les chaines de caractères par rapport à l’ordre orthographique des chaines de caractères au regard du classement des lettres de l’alphabet et de la collation choisie, cette dernière pouvant être sensible ou non, à la casse, aux accents…. Du fait de cet ordre, il est donc possible de rechercher par intervalle comme c’est le cas de la recherche d’un mot commençant par… En effet, si nous recherchons les mots commençant par « fass » ils sont regroupés les uns à la suite des autres dans l’index, ce qui permet un accès immédiat et la solution est, par exemple la suivante :
- fasse
- fassent
- fasses
- fassiez
- fassions
Pour ce qui est des mots finissant par, l’index ne nous est d’aucune utilité, mais une astuce consiste à créer les mots inversés (par exemple à l’aide d’une colonne calculée), les indexer et rechercher par le même type de LIKE sur l’inverse de la terminaison souhaitée. Par exemple, rechercher tous les mots se terminant par « aide’, il suffit de faire la recherche suivante :
et de renvoyer le mot correspondant !
Bien entendu pour rechercher un mot commençant par… et finissant par…, il suffit de combiner les deux recherches !
Un exemple est apporté par l’extrait de requête suivant :
Mais comment être efficace lorsque l’on recherche une chaine à l’intérieur d’un mot ? C’est là qu’intervient la notion d’index « rotatif »…
LE CONCEPT
Un index « rotatif » est en fait une liste de mots pour laquelle on supprime successivement la lettre du début à chaque tour, d’où le nom d’index « rotatif ».
Par exemple le mot « locomotive » sera ainsi décliné :
- locomotive
- ocomotive
- comotive
- omotive
- motive
- otive
- tive
- ive
- ve
- e
On numérote alors chaque rotation, y compris le mot racine dont par convention on attribuera l’indice 0 comme niveau de rotation. Par exemple le « sous-mot » « motive » aura un indice de rotation de 4 parce qu’on lui aura retiré les 4 premières lettres.
Une fois ces mots Ajoutés dans une table de mots, il suffit de les indexer et d’ajouter une table des références croisées entre les mots racine et les rotations. La recherche peut désormais se faire via un LIKE ‘mot%’ qui permet d’exploiter l’index ! Mais il faut ensuite remonter au mot racine par une jointure à l’aide de la table des références croisées.
LA MÉCANIQUE
Afin de bien distinguer ces objets techniques de votre base, objets qui n’ont rien à voir avec les objets fonctionnels de votre application, je vous conseille de créer un schéma SQL spécifique pour les y stocker logiquement
Les tables pour ce faire.
Deux tables suffisent : la table des mots, et la table des références croisées.
(MOT_ID INT IDENTITY PRIMARY KEY,
--> doit être sensible aux accents mais pas à la casse ! Exemple maïs et
-- mais, sur et sûr, retraite et retraité, congres et congrès !
MOT_MOT VARCHAR(32) COLLATE French_BIN NOT NULL UNIQUE);
(MRT_ID INT IDENTITY PRIMARY KEY,
-- pointe vers la rotation du mot
MOT_ID INT NOT NULL REFERENCES S_XRT.T_MOT (MOT_ID),
-- pointe vers la racine du mot
MOT_ID_RACINE INT NOT NULL REFERENCES S_XRT.T_MOT (MOT_ID),
-- indice de rotation
MRT_ROTATION TINYINT NOT NULL,
UNIQUE (MOT_ID, MOT_ID_RACINE, MRT_ROTATION));
Les routines
Une procédure va permettre d’indexer un mot. En voici le code en Transact SQL :
AS
SET NOCOUNT ON;
SET @MOT = LOWER(LTRIM(RTRIM(@MOT)));
DECLARE @L TINYINT = LEN(@MOT), @ID_MOT INT;
DECLARE @ROTATIONS TABLE
(MOT VARCHAR(32) COLLATE French_BIN,
ROT TINYINT);
-- calcul des rotations, racine comprise (0)
WITH T AS
(SELECT @MOT AS M, 0 AS I
UNION ALL
SELECT RIGHT(M, @L-I - 1), I + 1
FROM T
WHERE I < @L - 1
)
INSERT INTO @ROTATIONS
SELECT * FROM T;
-- insertions des mots manquants
INSERT INTO S_XRT.T_MOT
SELECT MOT
FROM @ROTATIONS
WHERE MOT NOT IN (SELECT MOT_MOT
FROM S_XRT.T_MOT);
-- récupération de l'ID du mot racine
SELECT @ID_MOT = MOT_ID
FROM S_XRT.T_MOT
WHERE MOT_MOT = @MOT;
-- insertions des rotations manquantes
INSERT INTO S_XRT.T_MOT_ROTATION_MRT
SELECT M.MOT_ID, @ID_MOT, R.ROT
FROM @ROTATIONS AS R
JOIN S_XRT.T_MOT AS M
ON R.MOT = M.MOT_MOT
WHERE NOT EXISTS(SELECT *
FROM S_XRT.T_MOT_ROTATION_MRT AS MR
WHERE MR.MOT_ID = M.MOT_ID
AND MR.MOT_ID_RACINE = @ID_MOT
AND MR.MRT_ROTATION = R.ROT);
Enfin, une fonction table constituée d’une simple requête paramétrée, va permettre de retrouver les mots racine à partir des partiels :
RETURNS TABLE
AS
RETURN (SELECT MR.MOT_ID, MR.MOT_MOT
FROM S_XRT.T_MOT AS M
JOIN [S_XRT].[T_MOT_ROTATION_MRT] AS R
ON M.MOT_ID = R.MOT_ID
JOIN S_XRT.T_MOT AS MR
ON R.MOT_ID_RACINE = MR.MOT_ID
WHERE M.MOT_MOT LIKE LOWER(RTRIM(LTRIM(@MOT))) + '%');
QUELQUES TESTS
Nous sommes partis d’une base contenant le dictionnaire LEXIQUE du CNRS, comportant 128 918 mots.
Notre méthode pour les indexer tous a été d’utiliser un curseur pour connaitre le temps moyen mis par la procédure d’indexation. Ce traitement a été effectué sur une machine ayant les caractéristiques suivantes : 2 processeurs XEON, 48 cÅ“urs , 128 Go de RAM, 8 disques SAS en RAID 10 avec SQL Server 2016.
Le temps de traitement a été de 26 minutes et 21 secondes, soit, pour 128 918 mots, 12 ms par mot.
Le traitement a généré :
* 376 567 entrées de mots dans la table S_XRT.T_MOT (représentant 24 Mo)
* 1 168 547 lignes dans la table S_XRT.T_MOT_ROTATION_MRT (représentant 62 Mo)
À noter qu’après réindexation, on observe une diminution du volume des données : 22 et 57 Ko respectivement.
Voici le batch que nous avons utilisé (la table du dictionnaire LEXIQUE du CNRS est dbo.TS_MOT_MOT :
DECLARE C CURSOR
LOCAL FORWARD_ONLY STATIC READ_ONLY
FOR
SELECT MOT_MOT
FROM dbo.TS_MOT_MOT
WHERE MOT_LONGUEUR > 1;
DECLARE @MOT VARCHAR(32);
OPEN C;
FETCH C INTO @MOT;
WHILE @@FETCH_STATUS = 0
BEGIN
EXEC S_XRT.P_INDEXATION_ROTATIVE @MOT;
FETCH C INTO @MOT;
END;
CLOSE C;
DEALLOCATE C;
SELECT DATEDIFF(ms, @T, GETDATE());
L’utilisation de la fonction table en ligne S_XRT.F_SUPER_LIKE, met en moyenne 50 ms quelques soit la racine cherchée si elle est constituée d’au moins 3 caractères. Exemple :
Pour la pire des recherches, le système met moins d’une seconde à trouver les 130 162 mots contenant la lettre e !
Pour comparaison, la recherche des mots comprenant les caractères « eta », d’une part directement dans le dictionnaire à l’aide d’un LIKE ‘%eta%’ et d’autres part dans l’index rotatif donne les métriques suivantes :
* Dictionnaire, LIKE’%eta%’ : temps UC = 652 ms, temps écoulé = 430 ms.
* Index rotatif, S_XRT.F_SUPER_LIKE (‘eta’) : Temps UC = 265 ms, temps écoulé = 50 ms.
Paradoxalement les plans de requête ne reflètent pas vraiment cette différence. les couts des plans apparaissent ainsi :
* Index rotatif, S_XRT.F_SUPER_LIKE (‘eta’) : 3,79 (soit 86 % de l’ensemble
* Dictionnaire, LIKE’%eta%’ : 0,61 (soit 14% de l’ensemble)

Plan de requête SQL Server utilisant une fonction table en ligne et l’index rotatif
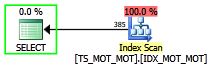
Utilisation directe du LIKE ‘%toto%’
UN PEU D’ASTUCE
Au fur et à mesure de son utilisation, les index rotatifs grandissent de moins en moins, car ils contiennent déjà des rotations utilisables pour d’autres mots. On peut donc prévoir certaines manÅ“uvres pour les rendre plus efficaces encore, comme le précalcul de certaines données, la compression des index ou encore l’utilisation de vues matérialisées (ou indexées sur SQL Server).
À titre d’exemple, nous avons obtenus la métrique suivante : temps UC = 63 ms, temps écoulé = 67 ms, à l’aide de l’une de ces techniques !
LE CODE * LE CODE * LE CODE * LE CODE * LE CODE * LE CODE * LE CODE * LE CODE * LE CODE
Le code SQL
Expert S.G.B.D relationnelles et langage S.Q.L
Moste Valuable Professionnal Microsoft SQL Server
Société SQLspot : modélisation, conseil, formation,
optimisation, audit, tuning, administration SGBDR
Enseignant: CNAM PACA, ISEN Toulon, CESI Aix en Prov.
L’entreprise SQL Spot
Le site web sur le SQL et les SGBDR
![]()

Développez et administrez pour la performance avec SQL Server 2014
Effectivement tu as raison c’est MO !!!!
Bonjour Frédéric, pour la taille occupée par les deux table ne serait-ce pas des MO plutôt que des KO?