Le langage SQL incorpore dans sa norme SQL ISO 13249 des extensions pour la recherche plain texte (2 – Full-Text).
La recherche plain texte permet de retrouver des données contenant certains mots, expressions ou formes fléchies de mots, synonymes, etc. dans les lignes des tables, y compris pour des colonnes de type LOB pouvant contenir de grand textes (CLOB, NCLOB) voire des fichiers électroniques binarisés (BLOB).
Cet article propose une comparaison de la norme avec les solutions proposĂ©es par Oracle MySQL 5.0 et Microsoft SQL Server 2008 pour l’indexation textuelle aussi appelĂ©e indexation de texte intĂ©grale et son corolaire, la recherches plain texte (ou encore la recherche en texte intĂ©gral – Full text search).
NOTA : une partie de cet article est extraite du chapitre 8 du Livre « SQL (3e Ă©dition)« , collection Synthex – Pearson Education 2010 – Auteurs : FrĂ©dĂ©ric Brouard, Christian Soutou, Rudi Bruchezouverez de nombreux autres commentaires sur ce sujet dans cet ouvrage.
0 – Introduction :
L’indexation plain texte, aussi appelĂ©e indexation de texte intĂ©grale, propose de fournir un service de recherche rapide d’informations dĂ©structurĂ©es basĂ©e sur des mots, parties de mots, expressions, formes flĂ©chies, synonymes, etc. contenu dans une ligne d’une table.
Pour satisfaire cette demande SQL propose Ă l’origine diffĂ©rents prĂ©dicats comme LIKE ou SIMILAR et des fonctions particulières (SUBSTRING, CHARACTER_LENGTH…), mais leur utilisation s’avère vite compliquĂ©e et finalement extrĂŞmement couteuse sur un volume de donnĂ©es apprĂ©ciable. En effet aucun index SQL classique ne permet d’accĂ©lĂ©rer de telles recherches.
1 – Principe :
Le principe d’un index textuel, commun aux diffĂ©rents SGBDR est simple :
– on dĂ©coupe les mots de l’ensemble des phrases rĂ©sultant de la concatĂ©nation des diffĂ©rentes colonnes Ă indexer;
– on les rĂ©fĂ©rence par rapport Ă :
• la table;
• la ligne dans la table;
• la colonne dans la ligne de table
• la position ordinale du mot. dans la colonne
L’index textuel est donc composĂ© de deux parties : la liste de tous les mots indexĂ©s, et la rĂ©fĂ©rence croisĂ©e entre les mots et leur position dans l’index textuel (table, ligne, position ordinale).
Bien entendu on ne tient pas compte des signes de ponctuation.
Enfin, il convient de gĂ©rer une liste de mots dits « noirs« , (stop words, noise words), c’est Ă dire des mots vide de sens sur lesquels les recherches n’ont aucun intĂ©rĂŞt, comme par exemple les articles, les pronoms, etc.
2 – Construction d’un index textuel
Chaque Ă©diteur propose sa propre solution de crĂ©ation des index textuel, car la norme n’a rien prĂ©vu Ă ce sujet qui reste dans le domaine physique et non celui de la logique pure, SQL Ă©tant un langage purement logique.
2.1 – solution Oracle MySQL :
Lors de la dĂ©finition d’une table ou bien par modification de la table, on dĂ©finit quelle(s) colonne(s) compose(nt) l’index textuel Ă l’aide de la fonction « FULLTEXT » dont la syntaxe est la suivante :
FULLTEXT [INDEX] [non_index] (colonne1 [, colonne2 [, …] ] ) [WITH PARSER nom_parser ]
Exemple – crĂ©ation d’un index textuel MySQL :
CREATE TABLE T_LIVRE_LVR
(LVR_ID INT NOT NULL PRIMARY KEY,
LVR_TITRE VARCHAR(256) NOT NULL,
LVR_ANNEE_PARUTION SMALLINT,
LVR_RESUME CLOB,
LVR_TEXTE_INTEGAL BLOB,
FULLTEXT(LVR_TITRE, LVR_RESUME))
Ceci indexe les colonnes LVR_TITRE et LVR_RESUME en temps que candidat Ă la recherche plain texte.
2.1 – solution Microsoft SQL Server :
Il faut procĂ©der en deux temps : la crĂ©ation d’un catalogue d’indexation qui dĂ©finit l’emplacement du stockage et la prise en compte de la sensibilitĂ© aux accents et autres caractères diacritiques puis dans un deuxième temps, crĂ©er autant d’index textuels que nĂ©cessaire, avec au moins un index par table Ă indexer, chaque index textuel pouvant avoir sa propre mĂ©thode de population et sa propre liste de mots noirs.
Exemple – 1er temps : crĂ©ation d’un catalogue d’indexation textuel SQL Server…
CREATE FULLTEXT CATALOG FTC_ROMANS
ON FILEGROUP STORAGE_FTS
WITH ACCENT_SENSITIVITY = OFF
AS DEFAULT;
Ce qui crĂ©Ă© un catalogue d’indexation textuelle, qui sera celui Ă dĂ©faut, dont les donnĂ©es seront stockĂ©es dans l’espace de stockage (filegroup) STORAGE_FTS et de nom FTC_ROMANS. Cet index ne sera pas sensible aux accents et autres caractères diacritiques (ACCENT_SENSITIVITY = OFF) et sera le catalogue d’indexation par dĂ©faut de tout nouvel index crĂ©Ă© dans la base (AS DEFAULT)
Exemple – 2e temps : crĂ©ation d’un index textuel MS SQL Server…
CREATE FULLTEXT INDEX
ON T_LIVRE_LVR (LVR_TITRE LANGUAGE French,
LVR_RESUME LANGUAGE French,
LVR_TEXTE_INTEGAL TYPE COLUMN '.rtf' LANGUAGE French)
KEY INDEX PK_LVR
ON FTC_ROMANS
WITH ( CHANGE_TRACKING = MANUAL,
STOPLIST = SYSTEM);
L’index textuel est crĂ©Ă© sur la table T_LIVRE_LVR et sur les colonnes de langue française LVR_TITRE, LVR_RESUME et LVR_TEXTE_INTEGAL, avec pour ce dernier l’indication que cette colonne contient des fichiers Ă©lectroniques au format RTF.
On indique en sus quel index unique servira de clef pour rĂ©fĂ©rencer les lignes de la table (ici PK_LVR qui est l’index sous-jacent Ă la clef primaire) et sur quel catalogue d’indexation textuel on greffe cet index textuel.
Enfin on dĂ©finit la mĂ©thode de population qui peut ĂŞtre manuelle ou au fil de l’eau, et la liste des mots noirs qui peut ĂŞtre celle Ă dĂ©faut (SYSTEM), une liste particulière spĂ©cialement crĂ©Ă©e ou encore aucune (OFF).
3 – PossibilitĂ©s de recherche
La norme SQL permet d’effectuer des recherches de mots dans les documents avec les limites suivantes :
– un ou plusieurs mots avec des combinaisons de ET (&), OU (|) et NON (NOT), au sein de la ligne de la table, d’un paragraphe au sein de la ligne ou encore d’une phrase au sein d’un paragraphe;
– les mots peuvent ĂŞtre exprimĂ©s en partie Ă l’aide de jokers;
– la recherche peut prendre en compte les formes flĂ©chies des mots (pluriels, fĂ©minins, conjugaisons, etc.);
– la proximitĂ© de mots (en distance entre mots, phrases ou paragraphes);
– la recherche peut s’effectuer sur des synonymes ou des « expansions »;
– elle peut inclure un floutage de l’expression (IS ABOUT) ou de certains mots (FUZZY).
La norme SQL propose plusieurs mĂ©thodes d’interrogation, Ă l’aide des fonctions CONTAINS, SCORE et NUMBEROFMATCHES, dĂ©crites ci dessous.
3.1 – Recherches avec CONTAINS
La mĂ©thode CONTAINS( ‘ motif plain texte ‘) retourne 1 si la recherche aboutit pour une ligne d’une table, sinon 0.
Exemple :
SELECT *
FROM T_LIVRE_LVR
WHERE CONTAINS ( ' "roman" | "nouve*" ') = 1
Recherche les lignes de la table T_LIVRE_LVR contenant le mot roman ou un mot commençant par nouv (comme nouveau, nouvel, nouveaux …).
3.2 – Recherches avec SCORE
La mĂ©thode SCORE( ‘ motif plain texte ‘) renvoie un DOUBLE_PRECISION (rĂ©el 64 bits) donnant un indice de pertinence de la recherche.
Exemple :
SELECT *
FROM T_LIVRE_LVR
WHERE SCORE ( ' "roman" | "nouve*" ') > 0.5
Recherche les lignes de la table T_LIVRE_LVR contenant le mot roman ou un mot commençant par nouv (comme nouveau, nouvel, nouveaux …) avec un score supĂ©rieur Ă 0,5.
3.3 – Recherches avec NUMBEROFMATCHES
La mĂ©thode NUMBEROFMATCHES( ‘ motif plain texte ‘) renvoie un INTEGER (entier) indiquant le nombre de fois oĂą le mot ou bien une phrase a Ă©tĂ© trouvĂ© dans la ligne.
Exemple :
SELECT *
FROM T_LIVRE_LVR
WHERE NUMBEROFMATCHES ( ' "roman * nouve*" ') BETWEEN 1 AND 2
Recherche les lignes de la table T_LIVRE_LVR contenant une phrase constituĂ©e du mot roman suivi d’un mot commençant par nouv (comme nouveau, nouvel, nouveaux …) quelque soit la distance entre ces deux mots et Ă condition que ce motif soit prĂ©sent 1 Ă 2 fois.
4 – Motifs de recherche textuelle
Toute la difficultĂ© de la recherche textuelle repose sur le paramètre constituant la recherche elle mĂŞme qui est de type FT_pattern, dĂ©rivĂ© du type CHARACTER VARYING avec une longueur maximale dĂ©pendante de l’implĂ©mentation qui est fait par chaque Ă©diteur de SGBDR.
Un motif plain texte est une chaine de caractères composĂ©e des mots ou expressions Ă chercher accompagnĂ©s d’Ă©ventuels indicateurs. Chaque mot ou expression doit ĂŞtre entourĂ© de guillemets.
Exemples divers…
Type de recherche Expression
------------------------------ ---------------------------------------------------------
Mot simple ' "roman" '
Expression ' "tire bouchon" '
' "tire-bouchon" '
Mot avec joker ' "nouve_*" '
Différents mots (ou) ' "guerre", "paix" '
Synonyme de "guerre" ' THESAURUS "militaire" EXPAND SYNONYM TERM OF "guerre" '
Expansion de "guerre" ' THESAURUS "militaire" EXPAND BROADER TERM OF "guerre" '
Forme fléchie de "nouveau" ' STEMMED FORM OF FRENCH "nouveau" '
Mots dans une mĂŞme phrase ' "tristesse" IN SAME SENTENCE AS "vague" '
Mots dans un mĂŞme paragraphe ' "tristesse" IN SAME PARAGRAPH AS "vague" '
Mots proches ' "guerre" NEAR "paix" WITHIN 3 WORDS IN ORDER '
' "guerre" NEAR "paix" WITHIN 60 CHARACTERS '
' "guerre" NEAR "paix" WITHIN 3 SENTENCES IN ORDER '
' "guerre" NEAR "paix" WITHIN 2 PARAGRAPHS '
Terme flou via Soundex ' SOUNDS LIKE "guerre" '
Terme flou spécifique ' FUZZY FORM OF "russie" '
Texte flou ' IS ABOUT "la guerre et la paix en Russie" '
Combinaison de recherches ' ("roman" & "nouv_*" & STEMMED FORM OF FRENCH "vague") | (THESAURUS "militaire" EXPAND SYNONYM TERM OF "guerre" & "paix") '
Pour les synonymes et expansions, il faut crĂ©er diffĂ©rents thesaurus. Dans notre exemple celui porte le nom « militaire ». En effet un thĂ©saurus est spĂ©cifique Ă une sĂ©mantique particulière. Par exemple le mot four n’a pas la mĂŞme signification en matière de cuisine ou en matière de théâtre…
Une expansion consiste Ă trouver une expression Ă partir d’un terme simple. Par exemple pour le mot guerre on peut dĂ©finir dans le thĂ©saurus, les expressions « conflit armĂ© » et « engagement militaire« .
Une forme flĂ©chie est une dĂ©clinaison d’un mot dans ses diverses acceptations grammaticales : pluriel, fĂ©minin, conjugaison.
La recherche de mots proches peut se faire dans l’ordre de lecture ou indiffĂ©remment (option IN ORDER) et dans un espace limitĂ© aux mots, phrases ou paragraphes (par exemple au plus 3 mots).
Pour la recherche avec un terme flou spécifique, chaque éditeurs peut proposer son propre algorithme éventuellement plugable. Par exemple un Levenshstein.
Pour la recherche de texte flou, chaque Ă©diteur peut proposer sa mĂ©thode, Ă l’image de ce que fait Google par exemple.
5 – traitement des mots noirs
Pour ne pas tenir compte des mots noirs, l’expression de recherche peut commencer par la rĂ©fĂ©rence de langue.
Exemple :
' FRENCH "la guerre et la paix en Russie" '
Propose une mĂ©thode de recherche Ă©quivalente Ă l’expression :
' FRENCH "guerre paix Russie" '
En supposant que les mots la, et et en sont des mots noirs relatifs Ă la langue FRENCH.
6 – Comparaisons des solutions
6.1 – mise en place de l’indexation textuelle.
Les limitations sont sévères avec Oracle MySQL. En effet :
- L’indexation textuelle n’est possible que pour des tables de format ISAM;
- L’index est peuplĂ© de manière synchrone ce qui ralentit les mises Ă jour;
- Il n’est pas possible d’indexer des documents Ă©lectroniques contenus dans une colonne de type BLOB;
- La sensibilitĂ© aux accents n’est pas paramĂ©trable. La recherche est insensible Ă la casse;
- Certains jeux de caractères ne sont pas supportés (en particulier UNICODE);
- Toutes les colonnes d’un mĂŞme index doivent avoir le mĂŞme jeu de caractères et la mĂŞme collation;
- Il n’existe qu’une seule liste de mots noirs pour toutes les langues, mais elle est paramĂ©trable;
- MySQL considère comme mot noir tout mot de moins de n caractères, n étant paramétrable (paramètre ft_min_word_len) et à défaut de 4;
- Il n’est pas possible de faire des recherches de synonyme ou d’expansion, car MySQL n’implĂ©mente pas de thĂ©saurus.
Compte tenu de ces limitations, l’indexation opère a peu près correctement si une seule langue ne comportant aucun accent constitue l’essentiel des donnĂ©es. Compte tenu que que notre langue française comporte de nombreux accents et la cĂ©dille, l’indexation MySQL s’avère difficilement exploitable en production.
Particularité des index textuels Microsoft SQL Server :
- L’index est peuplĂ© de manière asynchrone, soit au fil de l’eau, soit de manière manuelle (par exemple avec une planification journalière) en totalitĂ© (reconstruction) ou par diffĂ©rence (un journal de suivi est activĂ© dans ce dernier cas);
- SQL Server indexe tous les mots, mĂŞme les mots noirs quelle qu’en soit leur longueur. Ce n’est qu’Ă la restitution que les mots noirs sont ignorĂ©s ou pas et en fonction de la langue choisie;
- Il est possible d’indexer n’importe quel type de documents Ă©lectroniques Ă l’aide des ifilters (dll d’extraction de texte par format de fichiers standardisĂ©s). En standard, SQL Server propose 50 formats parmi les plus courants (.doc, .htm, .html, .ini, .log, .ppt, .rtf, .txt, .url, .xls, .xml … );
- La sensibilité aux accents et autres caractères diacritiques est réglée au niveau du catalogue. La recherche est toujours insensible à la casse;
- Il est possible d’effectuer des recherches multilingues pourvu que l’on puisse repĂ©rer la langue dans laquelle l’information a Ă©tĂ© saisie (par exemple en ajoutant Ă la table une colonne indiquant la langue). Dans ce cas il est inutile de prĂ©ciser la langue lors de la construction de l’index;
- Il est possible de créer ses propres listes de mots noirs en fonction de chacune des langues;
- SQL Server implĂ©mente un thĂ©saurus par langue qui se prĂ©sente sous la forme d’un document XML Ă©ditable et permet la recherche des synonymes ou des expansions.
Exemple – extrait d’un thĂ©saurus Microsoft SQL Server en langue française pour la recherche de couleurs dans des textes :
<XML ID="Microsoft Search Thesaurus">
<!-- Commented out (SQL Server 2008)
<thesaurus xmlns="x-schema:tsSchema.xml">
<diacritics_sensitive>0</diacritics_sensitive>
<expansion>
<sub>couleur</sub>
<sub>teinte</sub>
<sub>coloris</sub>
<sub>nuance</sub>
</expansion>
<replacement>
<pat>bleu</pat>
<sub>azur</sub>
<sub>bleu acier</sub>
<sub>bleu canard</sub>
<sub>bleu ciel</sub>
<sub>bleu cobalt</sub>
<sub>bleu de Prusse</sub>
<sub>bleu Ă©lectrique</sub>
<sub>bleu Klein</sub>
<sub>bleu Majorelle</sub>
<sub>bleu nuit</sub>
<sub>bleu outremer</sub>
<sub>bleu pétrole</sub>
<sub>cyan </sub>
<sub>indigo</sub>
<sub>lavande</sub>
<sub>marine</sub>
<sub>pervenche</sub>
<sub>saphir</sub>
<sub>turquoise </sub>
</replacement>
...
</thesaurus>
-->
</XML>
Dans cet exemple les mots couleur, teinte, coloris et nuance sont considérés comme synonymes (substitute) pour la recherche (expansion). Quand au mot bleu (pattern) il ne sera pas recherché, mais les mots et expressions comme azur ou bleu acier le seront (remplacement).
La seule vĂ©ritable restriction de MS SQL Server est de ne permettre qu’un seul thĂ©saurus par langue alors qu’il aurait fallu le faire par langue/sĂ©mantiques.
6.2 – interrogation dans l’index textuel
Oracle MySQL propose 1 seul prĂ©dicat de recherche en tout et pour tout MATCH/AGAINST. Il n’est pas conforme Ă la norme SQL.
SQL Server propose 4 mĂ©thodes pour le recherche textuelle. Deux prĂ©dicats : CONTAINS et FREETEXT; et deux fonctions tables : CONTAINSTABLE et FREETEXTTABLE. CONTAINS est l’un des prĂ©dicats conforme Ă la norme SQL.
Les possibilités de recherche des deux SGBDR sont présentées dans le tableau suivant :
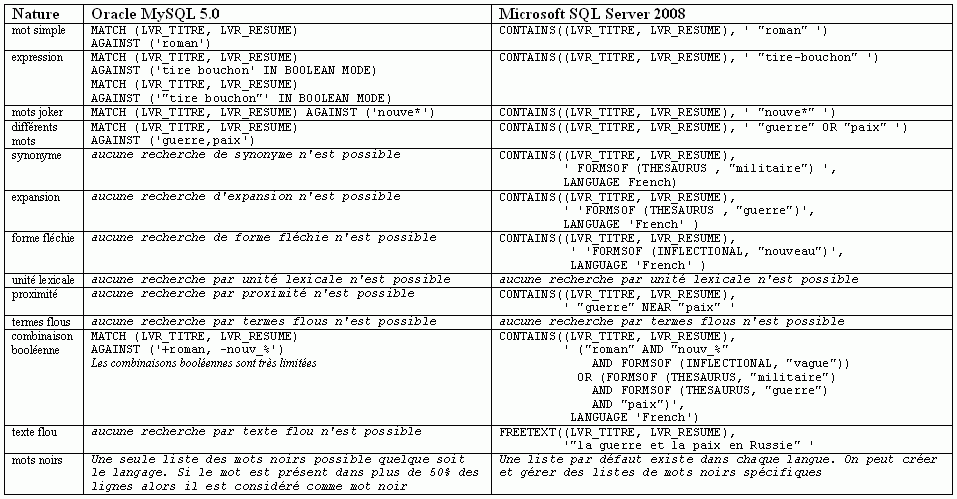
Cliquez ici pour une image plus grosse
Notons que sur 13 possibilitĂ©s, MySQL n’en accepte que 5 et avec des restrictions importantes : liste de mots noirs par langue impossible, gestion des caractères diacritiques mal organisĂ©e, combinaisons boolĂ©ennes très limitĂ©es, pas d’indexations de document Ă©lectroniques…
En revanche, MS SQL Server en accepte directement 10, et il est possible de rĂ©aliser manuellement une recherche par terme flous, car SQL Server met Ă disposition des dĂ©veloppeurs les tables système contenant les mots indexĂ©s comme l’emplacement des mots dans les donnĂ©es. Ceci permet aussi de compter le nombre de mots ou d’expressions correspondant Ă une recherche prĂ©cise et permet de simuler le prĂ©dicat normatif NUMBEROFMATCHES. Enfin, outre la publication de rĂ©sultats pondĂ©rĂ©s (Ă©quivalent du prĂ©dicat normatif SCORE) SQL Server offre la possibilitĂ© de prĂ©voir une pondĂ©ration des expressions recherchĂ©es.
Exemple :
CONTAINSTABLE (dbo.T_CRASH_CRH, *,
' ISABOUT (FORMSOF (INFLECTIONAL, "guerre") weight (.6),
FORMSOF (INFLECTIONAL, "napoléon") weight (.8),
"russie" weight (.7))')
7 – nouvelles fonctionnalitĂ©s avec SQL Server 2012
SQL Server 2012 permet de recherche de manière plus précise les mots proches en spécifiant une distance maximum.
Exemple :
SELECT *
FROM T_ANNONCE_ANC
WHERE CONTAINS(ANC_RESUME 'NEAR((expert, "SQL Server"), 5, TRUE)');
Qui signifie, cherche les ligne de la table T_ANNONCE_ANC dont la colonne ANC_RESUME contient les termes « expert » et « SQL Server » dans cet ordre et avec une distance maximale de 5 mots (y compris mots noirs.
On peut en sus avoir une idĂ©e de l’imbrication des mots dans les phrases et paragrpahes Ă l’aide de la fonction table sys.dm_fts_parser qui indique les cĂ©sures de phrases et de paragraphe.
En sus, SQL Server rajoute la recherche « sĂ©mantique », soit en indiquant Ă SQL Server quels sont les tags dĂ©limitant les zones de texte (par exemple pour un document XML ce peut ĂŞtre des balises de type attributs que l’on repère), soit en utilisant des dictionnaires intĂ©grĂ©s.
8 – conclusion
La complexitĂ© d’une recherche textuelle pertinente est Ă©vidente et les solutions retenues par les deux Ă©diteurs sont diamĂ©tralement opposĂ©s. Sans tenir compte des performances, pour le cas de MySQL il s’agit de faire croire que cela existe dans le SGBDR avec comme rĂ©sultat quelque chose de difficilement exploitable en production, surtout pour des langues latines constituĂ©es pour beaucoup de mots accentuĂ©s. En sus, le moteur d’indexation textuel de MySQL est mal programmĂ© et arrive Ă planter le serveur dans le cas d’une trop forte charge (passage en un seul lot d’un fort volume de donnĂ©es Ă indexer, comme cela arrive lors des imports de donnĂ©es).
En revanche pour SQL Server on est très proche d’une solution implĂ©mentant toutes les possibilitĂ©s de recherches de la norme SQL et facile Ă exploiter tant en matière fonctionnelle qu’en matière administrative. Avec SQL Server, l’accès aux donnĂ©es indexĂ©es, comme les mĂ©thodes de gestion de l’index sont nombreuses et permettent d’indexer d’Ă©normes volumes de donnĂ©es sans que cela ne pĂ©nalise les ressources du serveur, notamment via l’indexation asynchrone en mode fil de l’eau. De mĂŞme, la recherche est très efficace et mĂŞme en concurrence ne pĂ©nalise pas fortement le serveur.
En savoir plus…
A lire en complément :
- Principes de l’indexation textuelle (un Ă©crit qui date un peu !) : http://sqlpro.developpez.com/cours/indextextuelle/
- Les soundex et autres fonctions de consonnances : http://sqlpro.developpez.com/cours/soundex/
- Des fonctions de comparaison de motifs : http://sqlpro.developpez.com/cours/sql/comparaisons-motifs/
--------
Frédéric Brouard, SQLpro - ARCHITECTE DE DONNÉES, http://sqlpro.developpez.com/
Expert bases de données relationnelles et langage SQL. MVP Microsoft SQL Server
www.sqlspot.com : modélisation, conseil, audit, optimisation, tuning, formation
* * * * * Enseignant CNAM PACA - ISEN Toulon - CESI Aix en Provence * * * * *
![]()
Ping : Sql Server : Quelques astuces pour optimiser les requetes « .Net Blog
Bonjour,
Je crois qu’il y a une coquille dans l’article au niveau du MySQL.
Pour ceux que cela intéresse :
CREATE DATABASE testfulltext CHARACTER SET utf8 collate utf8_bin;
USE testfulltext;
CREATE TABLE articles (
id INT UNSIGNED AUTO_INCREMENT NOT NULL PRIMARY KEY,
title VARCHAR(200),
body TEXT,
FULLTEXT (title,body)) TYPE = MyIsam;
INSERT INTO articles VALUES (NULL,’ĂŞtre ou ne pas ĂŞtre çaabcdef Ă abcdef ètre oĂąabcdef OĂ™ABCDEF æxequo ÆXEQUO ñabc øabc Ĺ“uf0 Ă˝abc ĂťABC Ăźabc Ă°abc’, ‘test’);
Si sur cette table, on fait ces select:
SELECT * FROM articles WHERE MATCH (title,body) AGAINST (‘ĂŞtre’);
SELECT * FROM articles WHERE MATCH (title,body) AGAINST (‘çaabcdef’);
SELECT * FROM articles WHERE MATCH (title,body) AGAINST (‘Ă abcdef’);
SELECT * FROM articles WHERE MATCH (title,body) AGAINST (‘ètre’);
SELECT * FROM articles WHERE MATCH (title,body) AGAINST (‘oĂąabcdef’);
SELECT * FROM articles WHERE MATCH (title,body) AGAINST (‘OĂ™ABCDEF’);
SELECT * FROM articles WHERE MATCH (title,body) AGAINST (‘æxequo’);
SELECT * FROM articles WHERE MATCH (title,body) AGAINST (‘ÆXEQUO’);
SELECT * FROM articles WHERE MATCH (title,body) AGAINST (‘ñabc’);
SELECT * FROM articles WHERE MATCH (title,body) AGAINST (‘øabc’);
SELECT * FROM articles WHERE MATCH (title,body) AGAINST (‘Ĺ“uf0′);
SELECT * FROM articles WHERE MATCH (title,body) AGAINST (‘Ă˝abc’);
SELECT * FROM articles WHERE MATCH (title,body) AGAINST (‘ĂťABC’);
SELECT * FROM articles WHERE MATCH (title,body) AGAINST (‘Ăźabc’);
SELECT * FROM articles WHERE MATCH (title,body) AGAINST (‘Ă°abc’);
Ils retournent tous un enregistrement.
Autrement dit, le fulltext ne fonctionne pas en Unicode, mais en utf8 oui.
Donc on peut utiliser le fulltext sur toutes les langues d’Europe, et une très grande partie du monde avec MySQL. Pour le chinois, je ne sais pas car j’ai pas testĂ©. Si quelqu’un s’y connait en mandarin il pourrait faire un test.
C’est quand mĂŞme un article très intĂ©ressante.