Qu’est ce qu’un index ? A quoi ça sert ? Quel gain sont obtenus avec des index ? Comment est structurĂ© un index ? Pourquoi mon index n’est pas utilisĂ© ? Pourquoi les index se fragmentent-ils ?… Voici quelque unes des questions qu’aborde cet article !
1 – Qu’est ce qu’un index ?
DĂ©finition « mathĂ©matique » de l’index (bases de donnĂ©es) : un index est une structure de donnĂ©es redondante organisĂ©e de manière Ă accĂ©lĂ©rer certaines recherches.
Par sa nature un index est une information redondante qui n’est en aucun cas nĂ©cessaire Ă la logique relationnelle (c’est d’ailleurs pourquoi les index n’existent pas dans le langage SQL).
Dans le principe, la technique de l’indexation consiste Ă dĂ©couper la surface de stockage de l’information en plus petites parties ordonnĂ©es et ce de manière rĂ©cursive. Ainsi retrouver une information indexĂ©e consiste Ă naviguer de branche en branche dans l’index en Ă©liminant Ă chaque Ă©tape un grand nombre de cas. Ce parcours peut ĂŞtre fait notamment par dichotomie ou parcours d’arbre. Nous verrons quelques uns des algorithmes en seconde partie du prĂ©sent article.
=> 1.1 – exemples :
Par exemple, si vous devez donner rendez vous Ă une personne qui ne vous connais pas encore, vous pouvez vous contenter de donner le nom de la ville ou vous habitez pour qu’il vous retrouve. Sans prĂ©cision de rue cette personne devra chercher longtemps votre habitation, car il devra visiter un Ă un l’ensemble des logements de la ville. Si vous lui donnez le nom de la rue (dont les nomenclatures ont commencĂ©s au moyen âge) cette recherche sera dĂ©jĂ moins longue. Avec le numĂ©ro dans la rue (notion datant de la rĂ©volution) ce sera quasi immĂ©diat.
Voici donc un index que vous utilisez tous les jours sans le savoir.
MĂŞme chose pour le tĂ©lĂ©phone. Au dĂ©but de son invention, les demoiselles (du tĂ©lĂ©phone) connectais les quelques abonnĂ©es par rĂ©fĂ©rence Ă leur nom dans une ville. C’est ainsi que pour obtenir le marquis de Carabat Ă Pampelune depuis Paris, quartier du Maris, l’opĂ©ratrice du centrale Archive appelais l’opĂ©ratrice de Siant Tropez et les deux opĂ©ratrices opĂ©raient un câblage physique entre les deux points de la ligne.
Puis vint une première numérotation par ville. On le voit ici avec la transformation du central de Mâcon.
A cette même époque Fernand Raynaud avait du mal à obtenir le 22 à Asnières !
Finalement les transformations du tĂ©lĂ©phone, Ă partir des annĂ©es 70 et jusqu’Ă nos jours, permettent aujourd’hui d’accĂ©der Ă quiconque sur la planète Ă partir d’un simple numĂ©ro, relĂ©guant ainsi les opĂ©ratrices au rangs d’assistantes pour la recherche dans les annuaires !
En fait nous sommes environnĂ©s d’un grand nombre d’index sans le savoir, une immatriculation de vĂ©hicule, un numĂ©ro de compte en banque votre n° se sĂ©curitĂ© sociale, un code postal sont autant d’index que vous utilisez tous les jours !
=> 1.2 – IntĂ©rĂŞt de l’index
L’accès aux lignes des tables se fait sĂ©quentiellement, c’est Ă dire que pour trouver une information prĂ©cise, il faut parcourir une Ă une et l’une après l’autre les lignes de la table. Il faudra aussi parcourir toute la table. Par exemple pour chercher un Marcel Dupont dans une table d’individus, il faut lire toutes les lignes, car il peut y en avoir plusieurs et par malchance l’un d’entre eux peut figurer en dernière position dans la table.
Un index permet d’accĂ©lĂ©rer certaines recherches (les plus classiques) par le fait que la structure sous-jacente Ă l’index est spĂ©cialement conçue pour accĂ©lĂ©rer certaines recherches, notamment par le tri des donnĂ©es indexĂ©es.
Ainsi pour rechercher un Marcel Dupont dans un index sur Nom + PrĂ©nom, on peut agir par dichotomie et donc Ă©liminer un nombre important de cas, d’autant plus important que le nombre de donnĂ©es est important (Ă©chelle exponentielle).
L’efficacitĂ© d’une telle recherche est en O(log2(n)) (notation landau), c’est Ă dire que le nombre de cas scrutĂ©s et le gain entre lecture sĂ©quentielle des lignes et lecture dichotomique est le suivant :
Nombre de ligne Nombre d'itération Gain en %
-------------------------- ------------------ -----------
5 3 40
10 4 60
50 6 88
100 7 93
500 9 98,2
1 000 10 99
5 000 13 99,74
10 000 14 99,86
50 000 16 99,968
100 000 17 99,983
500 000 19 99,9962
1 000 000 20 99,998
5 000 000 23 99,99954
10 000 000 24 99,99976
Le gain devient très important Ă mesure que le nombre de ligne croit. Pour une petite table un index n’a donc pas un gain très intĂ©ressant. Nous explorerons plus loin ce point.
On constate donc qu’un index n’est pas nĂ©cessaire Ă l’information, mais permet une efficacitĂ© de recherche optimale (ce pourquoi il est crĂ©Ă© d’ailleurs). Mais attention, pour les recherches pour lequel il est prĂ©vu… Par pour toutes les recherches !
Seul inconvĂ©nient, il constitue une sorte de redondance dans le sens ou il oblige Ă stocker plus de donnĂ©es que l’information de base. Il augmente dons le volume globale de la base, mais nous verrons que, paradoxalement, il permet aussi de rĂ©duire grandement le volume utile de la base !
=> 1.3 – index crĂ©Ă©s automatiquement
Les SGBDR crĂ©Ă©e systĂ©matiquement un index chaque fois que l’on pose une clef primaire (PRIMARY KEY) ou une contrainte d’unicitĂ© (UNIQUE) sur une table. En revanche, il n’y a pas d’index crĂ©Ă© automatiquement par le SGBDR derrière une FOREIGN KEY (clef Ă©trangère).
Certains SGBD (en principe non relationnels) crĂ©Ă© des index systĂ©matiquement sur toutes les colonnes. C’est le cas de Sybase IQ rĂ©cemment rachetĂ© par SAP.
=> 1.4 – composition d’un index (clef d’index et vecteur)
Un index peut ĂŞtre composĂ© de plusieurs colonnes et cet ensemble est appelĂ© clef d’index. Par exemple, sur une table comportant les colonnes A, B, C, D, E, F et G, poser un index sur les colonnes A, C et G font que l’ensemble A, C, G est la clef de l’index.
L’ordre des colonnes de la clef (que l’on appelle vecteur) revĂŞt une importance particulière. En effet un index composĂ© des colonnes A, B, C est totalement diffĂ©rent d’un index crĂ©Ă© sur les colonnes B, C et A. Les effets de chacun de ces deux index sont diffĂ©rent parce que la composition interne des donnĂ©es en vue de l’accĂ©lĂ©ration des recherches n’est pas orientĂ©s dans le mĂŞme sens parce que, dans la structure des index on trouve une organisation ordonnĂ©es… En fait dans un index le contenu des colonnes est concatĂ©nĂ© avant le tri.
Voici par exemple le contenu d’un index composĂ© des colonnes NOM, PRENOM et DATE_NAISSANCE d’une table contenant des individus :
NOM PRENOM DATE_NAISSANCE
--------------- ------------- --------------
ABELARD Alain 26/04/1895
ABELARD Alain 16/08/1969
...
ABELARD Marcel 12/11/1950
...
ABELARD Zoé 17/02/1987
ABELARD Zoé 11/06/1992
...
MARTIN Alain 16/11/1899
MARTIN Alain 25/06/1964
...
MARTIN Marcel 16/08/1969
...
MARTIN Zoé 11/06/1992
...
ZWEIG Alain 21/06/1896
...
ZWEIG Marcel 11/04/1963
...
ZWEIG Zoé 05/08/1974
ZWEIG Zoé 02/01/1989
On observe que le tri de ces 3 colonnes fait que le prĂ©nom est triĂ© relativement au nom, c’est Ă dire qu’il est possible de trouver toute la plage de tous les prĂ©noms de A Ă Z pour un mĂŞme nom comme MARTIN. De mĂŞme pour la date de naissance qui est triĂ©e relativement au tri des colonnes prĂ©cĂ©dente.
On comprend bien que dans un tel ordre relatif l’efficacitĂ© de la recherche sera diffĂ©rente en fonction des cas pratique. Voici un tableau rĂ©sumant l’efficacitĂ© des recherches au regard de la combinaisons de tous les cas de recherches directes :
Recherche Efficacité
---------------------------------- ------------------
NOM + PRENOM + DATE_NAISSANCE Maximale
NOM + PRENOM Très importante
NOM seul Importante
NOM + DATE_NAISSANCE Bonne
PRENOM + DATE_NAISSANCE MĂ©diocre
PRENOM seul Très médiocre
DATE_NAISSANCE seule Très médiocre
On peut s’Ă©tonner de voir que l’index peut ĂŞtre utilisĂ© mĂŞme lorsque l’on recherche des informations « interne » au vecteur comme le prĂ©nom ou la date de naissance. Mais il est souvent moins couteux de chercher dans un index, mĂŞme sĂ©quentiellement, plutĂ´t que globalement dans la table, car la table possède souvent plus de colonnes. Donc, dans la plupart des cas, on lirait des donnĂ©es inutiles qui induisent un traitement plus long. Certes la diffĂ©rence n’est pas très importante, mais dans un SGBDR, chaque milliseconde gagnĂ©e peut se transformer en minute ou en heure en fonction du nombre d’utilisateurs et donc du nombre de fois ou une requĂŞte similaire est envoyĂ©e au serveur !
=> 1.5 – limitation des index
Plus les donnĂ©es d’un, index sont petites, plus l’index est efficace. Plus ces mĂŞmes donnĂ©es sont longues ou composĂ©es d’un grand nombre de colonnes et moins l’index est efficace. C’est pourquoi tous les SGBDR limitent la composition des index.
Voici un tableau rĂ©sumant les limites de l’indexation
| Oracle | SQL Server | PostGreSQL | MySQL (INNOdb) |
---------------------------|---------|----------- |------------|----------------|
Nombre maximal de | 30 Ă 32 | 32 | 32 | inconnue |
colonnes dans un index | (1) | | | |
---------------------------|---------|----------- |------------|----------------|
Longueur maximal de | (2) | 1600 | (3) | 767 |
la clef d'index (octets) | | | | |
---------------------------|---------|----------- |------------|----------------|
Nombre maximal d'index | infini | 1000 | infini | 16 |
par table | | | | |
(1) suivant le type de structure de l’index.
(2) 75% de la taille de la page moins quelques octets techniques
(3) 33% de la taille de la page moins quelques octets techniques
NOTA : les données des tables et index sont stockées dans des pages de longueur fixe pour une même base et dont la longueur peut être spécifiée à la création de la base.
Attention : pour les données littérales, les règles de calcul de longueur sont généralement les suivantes :
Type Longueur
------------ -------------------------------------
CHAR(n) : n
VARCHAR(n) : de 2 (données vides) à n + 3 octets
NCHAR(n) : 2 x n
NVARCHAR(n) : de 2 (données vides) à 2 x n + 3
De plus, certains encodage peu intĂ©ressant pour les bases de donnĂ©es, expandent encore la taille en octets des littĂ©raux stockĂ©es. Par exemple l’utilisation d’UF8 dans MySQL nĂ©cessite 3 octets par caractères ce qui fait que l’on ne peut pas indexer des donnĂ©es de plus de 256 caractères UTF8.
Les donnĂ©es de types Large Objet Binaire (LOB) comme les CLOB (texte ASCII), NCLOB (texte UNICODE) ou les BLOB (Binary) ne sont gĂ©nĂ©ralement pas indexable, sauf Ă travers des services particuliers, comme la recherche plain texte pour les LOB contenant des phrases composĂ©es de mots…
=> 1.6 – types de donnĂ©es indexĂ©es
En principe les donnĂ©es purement relationnelles (donc atomique) sont toutes indexables dans les limites ci avant Ă©voquĂ©es. Cependant certains SGBDR proposent d’indexer aussi des donnĂ©es non atomique pour des objets structurĂ©s dont la structure est connue du serveur, voire, pour les SGBD relationnel objet, lorsque l’objet a Ă©tĂ© spĂ©cialement conçu pour ĂŞtre indexĂ©.
Pour la recherche textuelle il s’agit de crĂ©er un index particulier sur des colonnes atomiques littĂ©rale ou CLOB/NCLOB.
Voici un tableau rĂ©sumant l’indexation des principaux objets non atomiques pour les 4 SGBDR les plus courants :
Oracle SQL Server PostGreSQL MySQL (InnoDB)
FULLTEXT OUI OUI OUI (1) NON
XML OUI OUI NON NON
GEOMETRY OUI OUI OUI NON
GEOGRAPHY NON (2) OUI OUI NON
(1) mais ne fonctionne pas suivant la norme SQL
(2) mais le type GEOMETRY d’Oracle permet de stocker un SRID, ce qui revient Ă utiliser un GEOGRAPHY !
=> 1.7 – crĂ©ation d’un index
Pour crĂ©er un index sur une table, la plupart des Ă©diteurs proposent un pseudo ordre SQL (pseudo car il n’existe pas dans le langage SQL…) CREATE INDEX dont la syntaxe gĂ©nĂ©rale est :
ON ( )
Suivi d’une Ă©ventuelle liste d’option spĂ©cifique Ă chaque Ă©diteur.
::
[ { ASC | DESC } ]
[, [ { ASC | DESC } ]
[, [ { ASC | DESC } ]
... ] ]
Cette liste spĂ©cifie les colonnes et le sens du tri qui a dĂ©faut est ASC pour ascendant. Il y a peu d’intĂ©rĂŞt d’utiliser le sens DESC (descendant) sauf dans le cas d’un index composĂ© de plusieurs colonnes, et ce pour une colonne vis Ă vis des autres. C’est souvent le cas des colonnes temporelles, car on est frĂ©quemment intĂ©ressĂ© de retrouver l’Ă©lĂ©ment le plus rĂ©cent plutĂ´t que l’Ă©lĂ©ment le plus ancien en règle gĂ©nĂ©ral (les clients dont la date de naissance remonte Ă 1889 Ă©tant souvent peu en Ă©tat de continuer Ă acheter !).
En sus de cette syntaxes primaire, il existe des options relationnelles sur l’indexation, que nous allons maintenant dĂ©tailler…
–> 1.7.1 – Indexer une colonne calculĂ©e ou une expression
Certains SGBDR permettent d’indexer des colonnes calculĂ©es ou des expressions dĂ©rivĂ©es des colonnes de la table. Ceci est extrĂŞmement intĂ©ressant dans certains cas pour des requĂŞtes particulières.
Soit, par exemple, une table de contact avec des numĂ©ros de tĂ©lĂ©phone. Nous savons tous que la partie significative d’un numĂ©ro de tĂ©lĂ©phone n’est pas son dĂ©but, mais sa fin. En effet, le dĂ©but peut ĂŞtre exprimĂ© de diffĂ©rentes manière, comme ceci 06 21 12 52 47 ou encore 00 33 6 21 12 52 47… Alors comment faire dans une telle table pour retrouver un numĂ©ro de tĂ©lĂ©phone particulier ? Il faut faire une requĂŞte avec un LIKE comme ceci :
WHERE TEL_NUMERO LIKE '%6 21 12 52 47'
Compte tenu du sens du tri dans un index, une telle requĂŞte ne pourra jamais utiliser de manière efficace l’index, sauf si nous inversons la chaine de caractères composant le numĂ©ro et que nous recherchons « Ă l’envers »…. C’est tout l’intĂ©rĂŞt des index sur colonnes calculĂ©es ou sur expression.
Exemple de crĂ©ation d’un index sur expression dans Oracle :
CREATE INDEX X_PERSONNE_NOM ON T_PERSONNE (UPPER(PRS_NOM));
–> 1.7.2 – Index filtrĂ©s (ou index partiels)
Un index peut ĂŞtre volumineux, et certaines donnĂ©es d’un groupe particulier peu requĂŞtĂ©es. C’est souvent le cas des donnĂ©es anciennes. Par exemple il est courant de manipuler les factures, commandes, bon de livraisons datant de moins d’un mois, un peu moins pour ceux datant de un Ă trois moins, encore moins pour ceux datant de quatre Ă douze mois, quand çà ceux de plus d’un ans, c’est exceptionnel ! Dans un tel cas on aura donc tout intĂ©rĂŞt Ă limiter l’indexation Ă 3 mois voir plus. C’est la notion d’index filtrĂ© qui accueille une clause WHERE.
Exemple de crĂ©ation d’un index filtrĂ© avec MS SQL Server :
CREATE INDEX X_CLIENT ON T_CLIENT (CLI_NOM, CLI_PRENOM) WHERE (CLI_DATE_NAISSANCE > '1900-01-01');
–> 1.7.3 – Index couvrants
Nous avons dit qu’un index Ă©tait une copie partielle des informations de la table. Pour certaines requĂŞte, la seule lecture de l’index suffit Ă rĂ©pondre Ă la requĂŞte. Dans ce cas on parle d’index couvrant, car il couvre la totalitĂ© des besoins de l’information de la requĂŞte par sa simple lecture. Point n’est besoin d’aller rechercher des informations complĂ©mentaires dans la table pour rĂ©pondre Ă la requĂŞte. Lorsque l’index n’est pas couvrant, cela oblige Ă un double parcours : parcourir l’index pour trouver la valeur recherchĂ©, puis une fois les lignes trouvĂ©es dans l’index, revenir sur la table afin de complĂ©ter les informations pour les colonnes qui ne sont pas prĂ©sentes dans l’index…
Voici une mĂŞme requĂŞte, partant de la mĂŞme table, une première fois exĂ©cutĂ©e avec un index traditionnel et la seconde fois avec un index couvrant, et les diffĂ©rences qu’il en rĂ©sulte :
La table en question, qui contient 300 000 lignes :
CREATE TABLE T_PERSONNE_PRS
(PRS_ID INT NOT NULL PRIMARY KEY,
PRS_NOM CHAR(32) NOT NULL,
PRS_PRENOM VARCHAR(25),
PRS_PROFESSION VARCHAR(32));
La requĂŞte en question :
SELECT PRS_NOM, PRS_PRENOM
FROM T_PERSONNE_PRS
WHERE PRS_PROFESSION = 'Informaticien';
L’index non couvrant :
CREATE INDEX X ON T_PERSONNE_PRS (PRS_PROFESSION);
Le plan de requête généré :
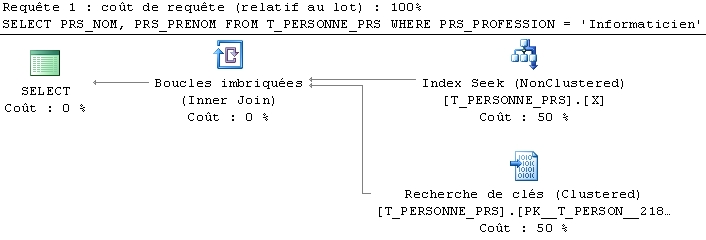
et son coĂ»t : Table ‘T_PERSONNE_PRS’. Nombre d’analyses 1, lectures logiques 7
Et maintenant la version avec l’index couvrant :
CREATE INDEX X ON T_PERSONNE_PRS (PRS_PROFESSION) INCLUDE (PRS_NOM, PRS_PRENOM);
Le plan de requête généré :

Et son coĂ»t : Table ‘T_PERSONNE_PRS’. Nombre d’analyses 1, lectures logiques 4
Bref, on a encore gagnĂ© près de 50%…
NOTA : cet exemple est donné pour MS SQL Server.
C’est la clause INCLUDE, qui permet de rajouter des colonnes non indexĂ©es, mais redondante dont les donnĂ©es seront reprises afin de couvrir la totalitĂ© de la requĂŞte et Ă©viter ainis une double lecture.
Quand on sait la propension non nĂ©gligeable d’informaticiens adorant faire des tables avec un nombre dĂ©lirant de colonnes (plutĂ´t que de gĂ©rer un vrai modèle relationnel), ce genre de technique permet de se sauver d’un mauvais modèle Ă bon compte !
–> 1.7.4 – Index de vues
En principe une vue ne contient pas de donnĂ©es. Mais le but d’une vue indexĂ©e (ou matĂ©rialisĂ©e, terme employĂ© sous Oracle) est de stocker les rĂ©sultats de la vue dans un index. Cela est particulièrement intĂ©ressant dans le cas ou l’on dĂ©sire requĂŞter sur des donnĂ©es très distantes (traversant un grand nombre de tables par des jointures) ou bien encore plus, pour des donnĂ©es agrĂ©gĂ©es (SUM, COUNT en particulier).
L’idĂ©e est de stocker dans un index les rĂ©sultats de la requĂŞte qui construit la vue. J’ai donnĂ© dans cet exemple la puissance gigantesque qui peut se dĂ©gager d’un tel outil : on fait passer d’un coĂ»t de 30 000 Ă 2 une requĂŞte calculant un COUNT !
=> Tableau rĂ©sumant les techniques relationnelles d’indexation
| Oracle | SQL Server | PostGreSQL | MySQL
--------------------|-------------|--------------|------------|--------------
index calculé | OUI | OUI colonne | NON | NON
ou sur expression | expression | calculée | |
--------------------|-------------|--------------|------------|--------------
index filtre | OUI | OUI | OUI | NON
(clause WHERE) | | | |
--------------------|-------------|--------------|------------|--------------
index couvrant | NON | OUI | NON | NON
(clause INCLUDE) | | | |
--------------------|-------------|--------------|------------|--------------
index de vue | Asynchrone | Synchrone | NON | NON
–> 1.7.5 – Index sur LOB
Il existe trois sortes d’index sur LOB classiquement implĂ©mentĂ©s dans les SGBD relationnels objet. Les index textuels prĂ©vus par la norme SQL dans son option FULL TEXT, les index XML et les index sur les donnĂ©es gĂ©omĂ©triques ou gĂ©ographiques (SIG).
Les index textuels permettent des recherches textuelles avec diffĂ©rentes combinaisons dont des recherches par forme flĂ©chies, proximitĂ©s, synonymes… Ă€ lire : http://blog.developpez.com/sqlpro/p9344/langage-sql-norme/indexation-textuelle-full-text-search-no/
Les index sur XML permettent d’accĂ©lĂ©rer certains traitements (recherche de nĹ“uds, de valeurs, de chemin…). Ă€ lire (exemple d’implĂ©mentation d’index XML dans SQL Server) : http://rdonfack.developpez.com/tutoriels/sqlserver/prise-charge-xml-dans-sql-server/
Les index sur objets gĂ©omĂ©triques ou gĂ©ographique permettent d’accĂ©lĂ©rer les traitements des requĂŞtes gĂ©omatiques. Ă€ lire : http://blog.developpez.com/sqlpro/p9414/langage-sql-norme/sql-et-systeme-d-information-geographiqu/
Tous ces index possèdent des structures particulières, plus ou moins complexes, mais le principe est le mĂŞme : organiser l’information pour la rendre plus rapidement accessible.
=> Tableau résumant les techniques relationnelles des index sur LOBs
| Oracle | SQL Server | PostGreSQL | MySQL
--------------------|-------------|--------------|-------------|--------------
indexation | spécifique | norme + | spécifique | spécifique
textuelle | | spécifique | (ts_vector) | et ISAM (1)
--------------------|-------------|--------------|-------------|--------------
XML | OUI | OUI | NON | NON
(clause WHERE) | | | |
--------------------|-------------|--------------|-------------|--------------
SIG | OUI | OUI | OUI | ISAM seulement
(clause INCLUDE) | | | | limitée (2)
--------------------|-------------|--------------|-------------|--------------
(1) L’indexation textuelle version MySQL possède très peu de fonctionnalitĂ©. Lire : http://blog.developpez.com/sqlpro/p9344/langage-sql-norme/indexation-textuelle-full-text-search-no/
(2) Les index spatiaux MySQL sont assez « rustiques » (pas de bounding box ni de niveaux de tesselation) et par consĂ©quent peuvent s’avĂ©rer peu performant
–> 1.7.6 – Options physiques d’indexation
En sus des options relationnelles, il existe des options physiques de crĂ©ation des index qui sont utiles soit pour l’optimisation de l’index lui mĂŞme, soit pour la maintenance des index. Nous en parlerons au chapitre suivant !
* * *Dans la suite (à paraître) de cet article, nous aborderons les sujets suivants :
2 – type de structure d’index
3 – fragmentation et maintenance des index
4 – gain rĂ©el obtenu par un index en fonction des types de requĂŞtes
--------
Frédéric Brouard, SQLpro - ARCHITECTE DE DONNÉES, http://sqlpro.developpez.com/
Expert bases de données relationnelles et langage SQL. MVP Microsoft SQL Server
www.sqlspot.com : modélisation, conseil, audit, optimisation, tuning, formation
* * * * * Enseignant CNAM PACA - ISEN Toulon - CESI Aix en Provence * * * * *
![]()
Bonjour,
Excellent article.
Par ailleurs, ma question est de savoir quelle serait la consĂ©quence de l’indexation de plusieurs champs sur une table donnĂ©e ?
Merci d’avance.
Salut sqlpro
A quand la suite (2/2)? si ce n’est pas trop vous exiger.
PS: puis-je dire Frédéric à la place de sqlpro?
En terme de volumĂ©trie le gain est peu important entre l’index complet (PRS_PROFESSION, PRS_NOM, PRS_PRENOM) et l’index couvrant (PRS_PROFESSION) INCLUDE (PRS_NOM, PRS_PRENOM). En revanche en terme d’utilisation c’est beaucoup plus intĂ©ressant, car on ne stocke pas les donnĂ©es incluses au niveau des pages intermĂ©diaire ce qui simplifie l’aiguillage sur les pages de navigation.
Encore un excellent article qui lève le voile sur les index. J’apprĂ©cie particulièrement la mise en perspective qui est faite avec les principaux SGBDR du marchĂ© : ORACLE, SQL SERVER, PostGreSQL,…
J’aurais bien souhaitĂ© voir le plan de requĂŞte et le coĂ»t d’un index qui n’utilise pas la clause INCLUDE. c’est Ă dire un index du genre
CREATE INDEX X ON T_PERSONNE_PRS (PRS_PROFESSION,PRS_NOM,PRS_PRENOM);
afin de dĂ©duire l’effet de la clause INCLUDE