Beaucoup d’article pseudo techniques prĂ©sentent le COMMIT Ă deux phases (Two Phase Commit ou 2PC) comme Ă©tant ACID, c’est Ă dire respectant les propriĂ©tĂ©s des transactions (ACID signifiant AtomicitĂ©, CohĂ©rence, Isolation, DurabilitĂ©). Or il n’en est rien et la COMMIT Ă deux phases peu parfaitement rendre votre base non intègre… Il faut comprendre que le COMMIT Ă deux phases n’est qu’un vulgaire moyen de coordonner des transactions distribuĂ©es sur diffĂ©rents SGBDR, mais est incapable de garantir la bonne finalitĂ© des diffĂ©rentes transactions unitaires.
1 – Principe du COMMIT Ă deux phases
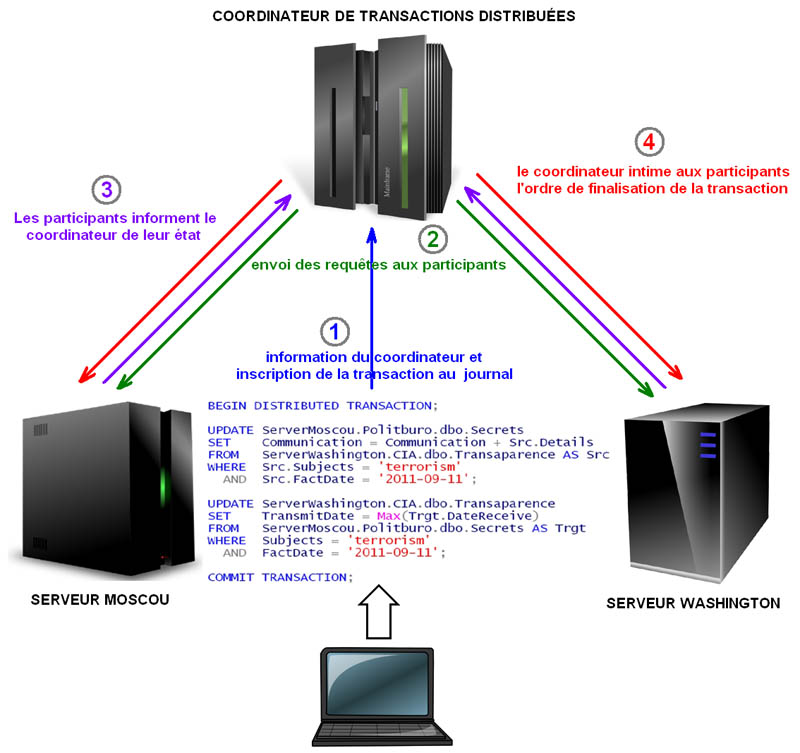
Lorsqu’une transaction concerne la mise Ă jour de donnĂ©es sur plusieurs serveurs indĂ©pendants, et comme chaque base de donnĂ©es possède son propre journal de transaction, il est nĂ©cessaire d’ajouter une couche de coordination des transactions distribuĂ©es.
Le principe du COMMIT Ă deux phases passe donc par un superviseur (ou coordinateur de transactions distribuĂ©es) qui scrute l’Ă©tat des serveurs et ordonne la finalitĂ© globale de la transaction.
La mĂ©thode consiste Ă envoyer les diffĂ©rents ordres SQL Ă tous les serveurs puis demander Ă chacun s’il peut valider la transaction (par exemple si aucune erreur n’est survenue sur aucun serveur).
C’est la première phase dite de scrutation ou de vote.
Si tous les serveurs participant Ă la transaction distribuĂ©e sont dans la capacitĂ© de valider chacun leur propre transaction, alors le coordinateur intime Ă chaque serveur d’appliquer la commande COMMIT. Dans le cas ou un seul des serveurs est dans l’incapacitĂ© de valider, alors le coordinateur prend la dĂ©cision de demander l’annulation et force chacun Ă appliquer un ROLLBACK. C’est un vote Ă l’unanimitĂ©.
C’est la seconde phase dite d’application ou de dĂ©cision.
2 – le problème
Entre le moment ou chaque serveur envoi un message indiquant s’il peut valider et le moment ou le coordinateur renvoie Ă tous les serveurs la confirmation ou l’invalidation, il se peut qu’un serveur tombe en panne.
Il est alors trop tard et les transactions sont appliquées sur les serveurs vivant, tandis que le serveur en panne ne peut pas finaliser la mise à jour.
Si le serveur en panne retrouve sa marche normale, il ne trouvera pas dans son journal de transaction l’ordre de finalisation de la transaction, ce qui se traduit par l’application d’un ROLLBACK implicite.
Le système de données distribué est devenu incohérent !
3 – des moyens de contournement ?
On pourrait bloquer les serveurs vivant jusqu’Ă ce que l’on ait confirmation que chaque serveur ait appliquĂ© la finalisation de la transaction. Mais cette façon de faire entrainerait dĂ©jĂ un allongement des temps de rĂ©ponse significatif, liĂ© au serveur rĂ©pondant le plus tardivement… Et dans le cas ou le serveur en panne a recouvrĂ© la santĂ©, il faudrait qu’on lui force l’application de cette dernière partie de la transaction distribuĂ©e.
On voit immĂ©diatement l’inconvĂ©nient de cette solution : un ralentissement significatif de toutes les transactions et un blocage complet du système en cas de panne d’un des leurs (tous les serveurs attendent) alors que l’intĂ©rĂŞt de distribuer les donnĂ©es est de pouvoir rĂ©partir la charge…
Ce n’est donc gĂ©nĂ©ralement pas cette solution qui est majoritairement appliquĂ© dans les mĂ©canismes de distribution des transactions.
4 – comment savoir ce qui s’est passĂ© ?
Si l’on accepte donc la survenance d’une telle problĂ©matique encore est-il intĂ©ressant de savoir ce qui s’est passĂ©, lorsque cela se passe mal !
En gĂ©nĂ©ral les superviseurs de transactions distribuĂ©es ou coordinateur ou encore moniteurs transactionnels incorporent un journal d’Ă©vĂ©nement (et non un journal de transactions) permettant de savoir l’Ă©tat final des transactions distribuĂ©es.
En cas de panne, le système indique quel serveur a Ă©tĂ© dĂ©faillant et montre la requĂŞte distribuĂ©e qui a Ă©tĂ© en Ă©chec. A vous de remettre manuellement les choses en place… lorsque c’est possible !
Dans l’univers Microsoft, le système est un service intitulĂ© MSDTC, pour « Microsoft Data Transaction Coordinator ». Il est capable de gĂ©rer des transactions distribuĂ©es au protocole standard XA, donc avec n’importe quel SGBDR transactionnel supportant ce protocole, comme SQL Server, Oracle, DB2 UDB… A lire : http://blog.jonathanoliver.com/2011/04/my-beef-with-msdtc-and-two-phase-commits/
5 – Faire autrement ?
Le risque de panne rendant incohĂ©rent un système de bases distribuĂ©es peut ĂŞtre un frein Ă l’utilisation d’une telle technique. Mais il y en a un autre : le temps de rĂ©ponse… loin d’ĂŞtre nĂ©gligeable ! En effet scruter plusieurs serveur via le rĂ©seau dilapide un temps qui, Ă l’Ă©chelle de la plupart des transactions, peut s’avĂ©rer fortement pĂ©nalisant.
Dès lors, on peut choisir un autre mode de gestion des bases de donnĂ©es rĂ©parties. Certains SGBDR comme Oracle ou MS SQL Server proposent des outils pour gĂ©rer les communications de donnĂ©es Ă donnĂ©es entre les serveurs de bases de donnĂ©es (MOM : Middleware Oriented Message) en mode asynchrone, transactionnĂ© et distribuĂ©. C’est le principe de SODA (Service Oriented Database Architecture). Par exemple dans le cas de MS SQL Server, c’est Service Broker qui assure cette couche.
Références :
Problématique du COMMIT à deux phases :
Two Phase Commit Need Have Nothing To Do With ACID or Any Other Kind of Transaction!
Distributed Transactions and Two-Phase Commit (page 15 en particulier)
Le processus de commit (validation) des transactions distribuées. (diapo 19 en particulier)
Service Broker :
Introducing Distributed Messaging using Service Broker in SQL Server 2005
A quoi sert Service Broker ?
--------
Frédéric Brouard, SQLpro - ARCHITECTE DE DONNÉES, http://sqlpro.developpez.com/
Expert bases de données relationnelles et langage SQL. MVP Microsoft SQL Server
www.sqlspot.com : modélisation, conseil, audit, optimisation, tuning, formation
* * * * * Enseignant CNAM PACA - ISEN Toulon - CESI Aix en Provence * * * * *
![]()
Bonjour
Article très intéressant : je suis en plein développement
et j’utilise du two-phase commit sur 2 bases firebird installĂ©es sur 2 serveurs diffĂ©rents (donc 2 moteurs qui tournent)
Que proposez-vous comme alternative pour éviter les problèmes que vous avez cités ?
NB: j’utilise Firebird 2.5
Cordialement