Le dĂ©bat entre faire une seule base de donnĂ©es pour diffĂ©rents clients ou bien autant de base que de client est rĂ©curent et lĂ©gitime. Il y a des avantages et des inconvĂ©nients Ă l’un comme Ă l’autre. Cet article tente d’en montrer tous les aspects afin de faire votre choix en toute connaissance de cause…
0 – Le problème
Imaginons une application qui est utilisĂ©e en ASP (Application Service Provider en anglais, c’est Ă dire « fournisseur de service d’application »), par exemple un Ă©diteur louant son application. Il existe alors deux façons de procĂ©der : faire une seule base mĂ©langeant les donnĂ©es de tous les clients ou bien faire autant de bases qu’il existe de clients.
1 – Une seule base
En procĂ©dant par la crĂ©ation d’une seule base mĂ©langeant les donnĂ©es de tous les clients, on doit se poser la question de la manipulation des donnĂ©es spĂ©cifiques Ă chacun des clients.
La encore deux techniques peuvent être utilisées :
- partitionner par données;
- partitionner la base par schéma SQL.
Dans le premier cas, il s’agit d’introduire dans chaque clef de chaque table un discriminant, un seul schĂ©ma SQL peut ĂŞtre utilisĂ©. Ceci sera le cas dans MySQL qui ne sait toujours pas gĂ©rer des bases multi schĂ©mas….
Dans le second cas, il suffit de crĂ©er autant de schĂ©ma SQL qu’il y a de clients concernĂ©s.
1.1 – Une seule base avec discriminant
Il suffit de rajouter dans toutes les clefs primaires de toutes les tables, Ă l’exception des tables communes, une colonne permettant de savoir d’oĂą vient l’insertion. Pour cela il convient de rajouter une table des clients avec une colonne rĂ©fĂ©rençant les diffĂ©rents clients. Cette table pourrait avoir la forme suivante :
CREATE TABLE T_CLIENT_CLI
(CLI_ID SMALLINT NOT NULL PRIMARY KEY,
CLI_NOM_CLIENT VARCHAR(64) NOT NULL UNIQUE);
DĂ©s lors toutes les tables « primaires » qui ne prĂ©sentent pas des donnĂ©es communes (comme par exemple la liste des codes postaux….) doivent ĂŞtre construites avec une clef primaire incorporant la colonne CLI_ID Ă titre de clef Ă©trangère.
Une table primaire Ă©tant une table qui n’est pas cible d’une intĂ©gritĂ© rĂ©fĂ©rentielle. Par exemple les tables factures et ligne de factures Ă©tant liĂ©es par l’intĂ©gritĂ© rĂ©fĂ©rentielles l’une au client, l’autre aux factures, il n’y a pas lieu d’y ajouter cette colonne, car on sait l’origine des donnĂ©es par les jointures. En revanche une table des clients, comme une table des produits n’est gĂ©nĂ©ralement pas cible de l’IRD (intĂ©gritĂ© rĂ©fĂ©rentielle dĂ©clarative).
Cette modification peut se faire Ă l’aide de SQL dynamique, la forme gĂ©nĂ©rale Ă©tant, pour une table :
ALTER TABLE <NomTable> DROP CONSTRAINT <NomContrainteClefPrimaire>;
ALTER TABLE <NomTable> ADD CLI_ID SMALLINT NOT NULL;
ALTER TABLE <NomTable> ADD CONSTRAINT <NomContrainteClefPrimaire> PRIMARY KEY (CLI_ID, <autresColonnesClef> );
Enfin, la manipulation des données sera simplifiée par la création de vues limitant la visibilité des données aux lignes spécifiques de chacun des clients. À ce niveau deux techniques existent :
- créer autant de vue que de tables et de clients (vues spécifiques);
- crĂ©er une seule vue « gĂ©nĂ©rique » par table en filtrant dynamiquement.
NOTA : contrairement Ă une idĂ©e largement rĂ©pandue on peut parfaitement mettre Ă jour des donnĂ©es des tables Ă travers les vues en appliquant les ordres SQL INSERT, UPDATE ou DELETE directement sur ces vues. Voir les articles que j’ai Ă©crit Ă ce sujet, en particulier :
http://sqlpro.developpez.com/SGBDR/ReglesCodd/
règle n°6 avec exemples et :
http://blog.developpez.com/sqlpro/p9259/ms-sql-server/exemple-d-utilisation-du-mapping-ro-dire/
1.1.1 – Une seule base, discriminant et vues spĂ©cifiques
La première solution (autant de vues que de tables et de clients) devient vite fastidieuse lorsqu’il y a de nombreux clients et multiplie le nombre de vues. De plus cela oblige Ă modifier l’application pour prendre en compte un nom de vue Ă chaque fois diffĂ©rent pour chaque client. Enfin, les diffĂ©rences des noms des vues induisent une perte de performance liĂ©e Ă la persistance dans le cache de procĂ©dure et ce point n’est pas Ă nĂ©gliger !
1.1.2 – Une seule base, discriminant et vues gĂ©nĂ©riques
La seconde solution (des vues gĂ©nĂ©riques) est plus simple Ă mettre en Ĺ“uvre Ă condition de gĂ©rer une bonne sĂ©curitĂ© d’accès au serveur SQL en jouant sur la notion d’utilisateur SQL, ce qui est gĂ©nĂ©ralement une bonne chose !
Cela consiste Ă crĂ©er autant d’utilisateur SQL qu’il y a de client, chaque utilisateur SQL Ă©tant codĂ© avec un nom incorporant son identifiant de client, par exemple sous la forme USER_xxxxx ou xxxxx reprĂ©sente le CLI_ID avec complĂ©tion par des zĂ©ros Ă gauche.
Voici par exemple comment crĂ©er directement tous les utilisateurs de la base sous cette forme Ă l’aide de SQL dynamique (Transact SQL – MS SQL Server) :
DECLARE @SQL VARCHAR(max);
SET @SQL = '';
WITH
T0 AS
(SELECT CAST(CLI_ID AS VARCHAR(5)) AS I,
5 - LEN(CAST(CLI_ID AS VARCHAR(5))) AS L
FROM T_CLIENT_CLI)
SELECT @SQL = @SQL + 'CREATE USER U_' + REPLICATE('0', L) + I + ';'
FROM T0;
EXECUTE (@SQL);
On pourra d’ailleurs profiter de ce script pour donner aux utilisateurs tous les privilèges sur les tables ou les vues, par exemple en rajoutant dans le SELECT final :
Chaque client Ă©tant connectĂ© au serveur Ă l’aide de don nom SQL, dès lors le critère de filtrage des vues pourra ĂŞtre le suivant :
WHERE CLI_ID = CAST(SUBSTRING(USER, 3, 5) AS SMALLINT)
Inconvénient de la solution "une seule base avec discriminant"
Le gros inconvĂ©nient de cette solution est que les donnĂ©es ne sont pas physiquement « cloisonnĂ©es » entre les diffĂ©rents clients, bien que ceci puisse se faire Ă l’aide du partitionnement de donnĂ©es. Et cela peut ĂŞtre une cause rĂ©dhibitoire pour certaines applications ou pour des problĂ©matiques de maintenance. Par exemple il n’est pas possible dans un tel cas de sauvegarder les donnĂ©es d’un seul client indĂ©pendamment ni, bien entendu, de le restaurer…
1.2 – Une seule base avec partitionnement pas schĂ©mas SQL
Le principe consiste Ă crĂ©er autant de schĂ©ma SQL qu’il y a de clients (pour ceux qui ne seraient pas familiarisĂ© avec la notion de schĂ©ma SQL, lire : http://blog.developpez.com/sqlpro/p5835/langage-sql-norme/de-l-interet-des-schema-sql/). Chaque schĂ©ma comportant toutes les tables nĂ©cessaires au fonctionnement de l’application mais avec les donnĂ©es d’un seule client. Pour qu’un client n’utilise pas la table du voisin, on crĂ©Ă© pour chaque client un utilisateur SQL dont c’est le schĂ©ma SQL par dĂ©faut, et l’on renforce la sĂ©curitĂ© par les privilèges SQL comme pour la mĂ©thode prĂ©cĂ©dente.
A nouveau ces schĂ©mas SQL peuvent ĂŞtre crĂ©Ă©s dynamiquement de la façon suivante avec les utilisateurs « autorisĂ©s » :
DECLARE @SQL VARCHAR(max);
SET @SQL = '';
WITH
T0 AS
(SELECT CAST(CLI_ID AS VARCHAR(5)) AS I,
5 - LEN(CAST(CLI_ID AS VARCHAR(5))) AS L
FROM T_CLIENT_CLI)
SELECT @SQL = @SQL + 'CREATE USER U_' + REPLICATE('0', L) + I + ';'
+ 'CREATE SCHEMA S_' + REPLICATE('0', L) + I
+ ' AUTHORIZATION U_' + REPLICATE('0', L) + I + ';'
FROM T0;
PRINT @SQL
EXECUTE (@SQL);
Reste Ă crĂ©er les objets (tables, vues…) dans toute la base.
Il suffit de crĂ©er un script SQL de rĂ©tro-ingĂ©nierie pour la crĂ©ation de tous les objets de la base originale et de lui changer son schĂ©ma. Par exemple dans MS SQL Server, le schĂ©ma par dĂ©faut Ă©tant dbo, il suffit de faire un remplacement de cette chaine de caractères dans le rĂ©tro script de crĂ©ation de tous les objets, avec le nom de schĂ©ma considĂ©rĂ©, pour l’appliquer au nouveau schĂ©ma et crĂ©er ainsi tous les objets.
Mieux : ceci peut ĂŞtre automatisĂ© lors de la crĂ©ation d’un schĂ©ma SQL, par un dĂ©clencheur DDL trappant l’Ă©vĂ©nement « CREATE SCHEMA » et reproduisant le script de crĂ©ation des objets. Et cerise sur le gâteau, point n’est besoin de spĂ©cifier le nom de schĂ©ma en prĂ©fixe de tous les objets si cette crĂ©ation s’effectue directement dans le CREATE SCHEMA ! Dans ce dernier cas on terminera par la crĂ©ation de tous les utilisateurs SQL avec leur schĂ©ma par dĂ©faut et on en profitera pour leur donner tous les privilèges sur le schĂ©ma, par exemple avec la commande SQL :
GRANT ALL ON SCHEMA::S_00007 TO U_00007;
2 – Plusieurs bases
Le principe est on ne peut plus simple : crĂ©er autant de base que de client. Il faudra simplement penser que l’application se connecte Ă la bonne base en fonction du client qui accède Ă l’application.
Pour la crĂ©ation des objets dans chaque nouvelle base on en revient Ă la solution prĂ©cĂ©dente (une seule base, plusieurs schĂ©mas SQL) avec l’avantage de ne pas devoir modifier le script initial.
Le seul problème de cette solution réside dans la multiplicité des bases. Chaque base ouverte publie en mémoire des informations de méta données et oblige à maintenir toujours en mémoire des descripteurs de fichiers pour les lectures physique comme pour les écritures. Multiplier le nombre de bases possède donc des limites qui jouent rapidement sur les performances. Si les serveurs peuvent généralement accepter plusieurs milliers de bases, en pratique il y va tout autrement : à plus de 100 bases, les effets négatifs sur les performances sont visibles. A plus de 10 bases, certaines techniques comme la gestion de la haute disponibilité par mirroring, deviennent fortement pénalisante.
3 – DonnĂ©es communes
On peut choisir de reproduire les données communes (par exemple les tables de codes postaux), comme de les partager.
La redondance des tables communes ne nĂ©cessite aucune modification particulière. NĂ©anmoins elle consomme du volume ce qui nuit rapidement aux performances de manière globale (il faudra donc prĂ©voir une augmentation significative de RAM). De plus elle peut conduire Ă des diffĂ©rences dans les mises Ă jour, sauf si l’on tente de les synchroniser par un mĂ©canisme de rĂ©plication par exemple (mais c’est encore au dĂ©triment des performances du fait de la consommation importante des ressources pour la gestion de la rĂ©plication).
Partager les donnĂ©es communes peut se faire dans des tables communes d’accès uniformisĂ© : dans la mĂŞme base pour les bases sans schĂ©ma, dans le schĂ©ma par dĂ©faut du SGBDR pour la solution avec multi schĂ©mas (c’est dbo par exemple pour MS SQL Server) et enfin dans une base commune pour la solution multi base.
Il y a donc une évolution nécessaire du code des requêtes.
Cette solution est Ă prĂ©fĂ©rer dans tous les cas, car elle limite le volume des donnĂ©es en plus d’offrir aucune redondance.
4 – Évolutions
Pour les bases monolithiques les Ă©volutions de la structure sont rendues très simples. La modification d’une table est immĂ©diatement utilisable.
Pour les bases multi schĂ©ma, il faut reproduire la modification de la table dans tous les schĂ©mas. Ceci peut ĂŞtre fait dynamiquement et de manière synchrone par le biais d’un dĂ©clencheur DDL.
Pour faciliter ce travail, il est intĂ©ressant de disposer d’un schĂ©ma type, dont le seul but est d’ĂŞtre l’origine des modifications de structure. Par exemple ce schĂ©ma pourrait s’intituler S_00000 et contenir un « modèle » de toutes les structures de donnĂ©es. Par ce biais, on peut ensuite appliquer les modifications Ă tous les schĂ©mas.
Voici un exemple de déclencheur DDL permettant un tel travail (MS SQL Server / Transact SQL) :
CREATE TRIGGER E_DDL_MODIFICATION_SCTRUCTURE_SCHEMA_00000
ON DATABASE
FOR DDL_TABLE_VIEW_EVENTS
AS
DECLARE @XMLEVENT XML,
@SQLCMD NVARCHAR(max),
@SCHEMA sysname;
SET @XMLEVENT = EVENTDATA();
SELECT @XMLEVENT
IF @XMLEVENT.().value('(/EVENT_INSTANCE/SchemaName)[1]','sysname') <> 'S_00000'
RETURN;
SET @SQLCMD = @XMLEVENT.value('(/EVENT_INSTANCE/TSQLCommand/CommandText)[1]','nvarchar(max)');
DECLARE C CURSOR
FORWARD_ONLY STATIC READ_ONLY
FOR
SELECT schema_name from INFORMATION_SCHEMA.SCHEMATA
WHERE schema_name LIKE 'S?_%' ESCAPE '?';
OPEN C;
FETCH C INTO @SCHEMA;
WHILE @@FETCH_STATUS = 0
BEGIN
SET @SQLCMD = REPLACE(@SQLCMD, 'S_00000', @SCHEMA);
EXECUTE (@SQLCMD);
FETCH C INTO @SCHEMA;
END;
CLOSE C;
DEALLOCATE C;
GO
Pour la solution multi bases, on peut adopter la mĂŞme stratĂ©gie en proposant une base modèle et en rĂ©percutant les modifications apportĂ©e Ă la base modèle, non aux schĂ©mas, mais aux diffĂ©rentes bases, toujours par le biais d’un dĂ©clencheur DDL.
5 – Maintenance
Pour le cas ou les bases seraient très petites, c’est Ă dire au plus quelques dizaines de Go, la maintenance est favorable Ă la solution en base monolithique. Mais dès que le volume s’accroit, il faut penser Ă rĂ©aliser cela Ă diffĂ©rentes heures (notamment suivant les fuseaux horaires des clients en privilĂ©giant les heures creuses), diffĂ©rentes frĂ©quences (en fonction du taux de mise Ă jour), diffĂ©rentes techniques (sauvegarde complètes, diffĂ©rentielles, du journal de transactions….), voire en parallèle (lancer plusieurs opĂ©rations de maintenance en mĂŞme temps ou multi threadĂ©es)… Ce qui n’est possible que dans le système multi bases ou bien si votre serveur le permet, en jouant sur les espaces de stockage et les schĂ©mas.
En particulier dans le modèle de base partitionnĂ© par schĂ©ma la maintenance peut se faire au choix, globalement (une seule procĂ©dure pour toute la base), ou bien par schĂ©ma pour la maintenance logique (dĂ©fragmentation, vĂ©rification…) et par storage pour la maintenance physique (sauvegarde), laissant ainsi une grande latitude de maintenance.
Enfin, si le SSGBDR est apte, comme c’est le cas de SQL Server, on peut effectuer la sauvegarde d’une mĂŞme base en parallèle sur diffĂ©rents supports, mĂŞme hĂ©tĂ©rogènes (disques locaux, SAN, distant, bande…)
6 – Tableau rĂ©capitulatif :
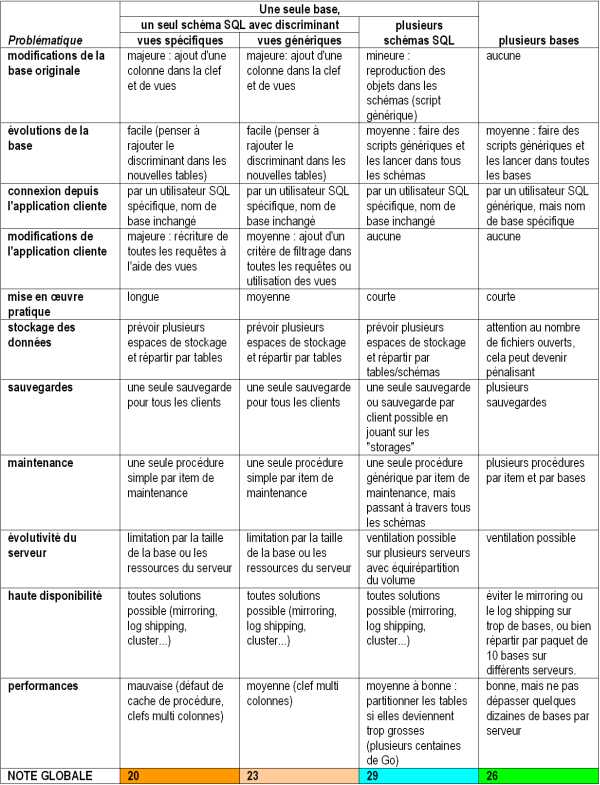
EXPLICATIONS :
- Modification de la base originale : quel faut-il faire Ă la base originale, non conçue au dĂ©part pour de multiples client afin d’utiliser la solution (par exemple ajout de vues, d’utilisateurs….)
- Évolution de la base originale : comment modifier les objets de la base en cas d’Ă©volution de la structure (ajout de nouvelles tables ou de nouvelles colonnes par exemple).
- Connexion depuis l’application cliente : que faut-il changer dans le mode de connexion de l’application cliente pour la solution envisagĂ©e.
- Modification de l’application cliente : que faut-il modifier dans le code de l’application pour que la solution fonctionne
- Mise en œuvre pratique : quel effort global faut-il faire pour la solution envisagée
Stockage des donnĂ©es : comment peut-on rĂ©partir les donnĂ©es dans les « storages » (filegroups, tablespaces….) et les fichiers - Sauvegardes : quelle stratĂ©gie adopter pour faire les sauvegardes.
- Maintenance : comment faut-il faire la maintenance de la base, notamment en matière de défragmentation des index, vérification de consistance des données ou encore import export
- ÉvolutivitĂ© du serveur : comment faire en cas de nĂ©cessitĂ© de faire Ă©voluer les ressources matĂ©rielles du serveur (scalability) afin d’assurer une bonne adĂ©quation ressources/performances.
- Haute disponibilitĂ© : de quelle manière assurer la haute disponibilitĂ©, c’est Ă dire le passage Ă une machine de secours en cas d’indisponibilitĂ© du serveur principal
- Performances : comment sont affecté les performances en fonction de la solution adoptée
- NOTE GLOBALE : elle est calculée en donnant une note de 1 à 3 à chaque item du tableau et en faisant la somme.
7 – Conclusion :
On voit assez clairement que le meilleur compromis entre souplesse, facilitĂ© de codage et maintenance repose sur une base unique avec un partitionnement par schĂ©ma. Ce système sera d’autant plus intĂ©ressant que le serveur possède la capacitĂ© d’une bonne gestion des espaces de stockage ainsi que la possibilitĂ© de faire des sauvegardes par fichiers ou « storage » y compris en mode complet, diffĂ©rentiel, voire avec parallĂ©lisation du stockage. Cela exclue d’emblĂ©e des SGBDR comme MySQL qui ne sont pas capable de gĂ©rer plusieurs schĂ©mas, ne permettent pas de rĂ©aliser des dĂ©clencheurs DDL, ni de jouer des sauvegardes partielles par storage !
Mais si les bases deviennent Ă©normes (plusieurs centaines de Go chacune), alors la solution d’utiliser plusieurs bases, et par facilitĂ© plusieurs serveurs Ă terme, sera la solution la plus adaptĂ©e.
--------
Frédéric Brouard, SQLpro - ARCHITECTE DE DONNÉES, http://sqlpro.developpez.com/
Expert bases de données relationnelles et langage SQL. MVP Microsoft SQL Server
www.sqlspot.com : modélisation, conseil, audit, optimisation, tuning, formation
* * * * * Enseignant CNAM PACA - ISEN Toulon - CESI Aix en Provence * * * * *
![]()
Bonjour, je dĂ©veloppe une application J2EE et j’ai adoptĂ© la première mĂ©thode de partionner par donnĂ©es car j’utilise Mysql mais j’ai un souci c’est lorsque un des utilisateurs vient d’insĂ©rer un nouveau enregistrement comment je fais pour rĂ©cupĂ©rer son CLI_ID et l’insĂ©rer comme clĂ© Ă©trangère??
Oui PostGreSQL implémente parfaitement la notion de schémas SQL qui fait partie intégrante de la norme SQL.
Est-ce que PostgresSQL sait gérer des bases multi schémas ?
Pour les données communes il y a effectivement deux niveaux :
1) les données externes, qui sont communes et partagées.
2) les données du référentiel interne qui peut être partagé ou spécifique
Dans le premier cas, aucun problème : liste de codes postaux, nomenclature ISO…
Dans le second cas, nous pouvons encore avoir des donnĂ©es strictement partagĂ©es, comme le sexe d’une personne ou encore des donnĂ©es semi partagĂ©es. CivilitĂ© en est un bon exemple :
les M. Mme. et Mlle. peuvent ĂŞtre communs, mais il est possible de rajouter d’autres Ă©lĂ©ments (Monseigneur, Son Altesse….). Aussi dans les modèles que je met au point, toutes les tables de rĂ©fĂ©rence ont une colonne « BASE » de type boolĂ©en qui si elle vaut 1 indique que la donnĂ©es est immuable et sert au fonctionnement de la base.
On peut donc Ă©tendre cette notion en faisant en sorte de modifier cette colonne en « SPECIFIQUE » et si elle vaut NULL ĂŞtre commune, sinon avoir le n° du client qui l’a saisie. Ce choix est plus pratique pour une base monolithique.
Une autre manière de faire est de prĂ©voir en sus du rĂ©fĂ©rentiel commun, des tables Ă©quivalentes et vide, dans chaque base, dont on fait l’union des donnĂ©es dans une vue spĂ©cifique au client. Ce dernier choix Ă©tant plus pratique dans des bases Ă©clatĂ©es.
Quand Ă la restauration, c’est un faux problème… C’est du mĂŞme niveau de responsabilitĂ© que celui de l’hĂ©bergeur de site web face Ă une mutualisation des ressources. Encore faut-il que le client soit au courant !
De toutes façon et en pratique il est rare que l’on restaure une base en totalitĂ© si il y a eu une petite corruption. GĂ©nĂ©ralement on tente de recomposer les donnĂ©es manquantes en les extrayant de la sauvegarde pour les replacer dans la base de production. Ce qui n’est mĂŞme pas nĂ©cessaire si les donnĂ©es manquantes sont celles d’un index non clustered.
Il me semble que la problĂ©matique de restauration de base de donnĂ©es n’est pas examinĂ©e pour les diffĂ©rents scĂ©narios. Prenons le cas d’une corruption de base (page de donnĂ©es endommagĂ©es par exemple), et Ă la restauration de(s) base(s).
Quel est le poids de cette problématique sur les différents choix ?
A+
On en vient donc a du data management .. je voulais y venir
++
On parle de point de verite dans la literature mais qui possede la verite ? Le client de la base 1 ou le client de la base 2 ?
Aucun d’entres eux, si on prend la decision de ne considĂ©rer communes que des donnĂ©es qui ne sont pas directement modifiables par les clients, comme par exemple, celles donnĂ©es en exemple de la table des code postaux, ou des pays, devises, etc…..
On laisse le soin Ă un « administrateur », superviseur, modĂ©rateur, superclient, … de pouvoir modifier ces donnĂ©es-lĂ .
On peut etendre encore la problematique sur le point 3 :
Faire un « referentiel » des donnnes communes est une bonne chose comme tu l’as dit mais elle fait apparaitre la problematique suivante : Qui mettra a jour les donnees. On parle de point de verite dans la literature mais qui possede la verite ? Le client de la base 1 ou le client de la base 2 ? Il faudra certainement implementer des regles de gestion a ce niveau …
++
Re-
Je sors juste d’une mission chez un client qui a 3000 bases sur une seule instance. On avait fait un audit chez lui en 2007, on avait dĂ©jĂ prĂ©conisĂ© de migrer sur des schĂ©mas. CoĂ»t de redĂ©veloppement faramineux, donc ils sont restĂ©s sur le principe 1 client = 1 base.
Le plus gros problème chez eux reste la maintenance, et notamment le backup. Pas de possibilité de passer les bases en FULL et générer 3000 backups logs 6 ou 8 fois par jour, donc toutes les bases en SIMPLE et 1 backup par nuit qui dure 8 ou 9 heures. Ils ont envisagé de passer par du VDI snapshot, mais je leur ai déconseillé (VDI créé 3 threads par base pour figer les IOs avant de générer le snapshot du volume, 3 threads x 3000 bases x 2Mb de stack en 64 bits, laisse tomber, tu peux descendre en salle machine et tirer la prise). Je leur ai écrit un petit backup.exe en C# sur 8 threads, ça roule comme ça.
Donc les solutions qui impliquent du redĂ©veloppement dans ce que j’en ai vu, c’est chaud. Les dĂ©veloppeurs sont dans leur trucs, ils n’ont pas la vision de l’exploitation, du temps de backup ou de dbcc, etc… Il faut prendre la dĂ©cision de passer par des schĂ©mas dès le dĂ©part sinon ça devient vite la galère.
Profite bien de tes vacances, et salut Ă elsuket de ma part A+
David B.