Suite au prĂ©cĂ©dent article consacrĂ© Ă ce sujet, je me suis penchĂ© sur diffĂ©rentes solutions publiĂ©e sur le net et leurs coĂ»ts d’exĂ©cution. Voici une Ă©tude pratique avec un test de comparaisons des diffĂ©rentes requĂŞtes sur les diffĂ©rents SGBDR, que sont MS SQL Server, MySQL et PostGreSQL. Cette Ă©tude constitue un excellent benchmark de SGBDR pour des requĂŞtes moyennement difficiles (elles ne portent jamais que sur une seule table !).
Rappel du problème : partant d’une table contenant des intervalles (pĂ©riodes de temps, plage d’entiers ou autres…), c’est Ă dire une information continue bornĂ©e par deux colonnes (DEBUT et FIN par exemple), comment faire en sorte d’agrĂ©ger ces intervalles lorsque certains se recoupent ?
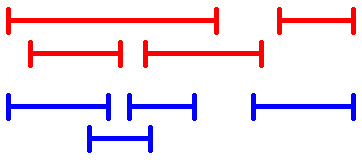
Par couleurs, les intervalles présentés ci dessus se recoupent pour certains.
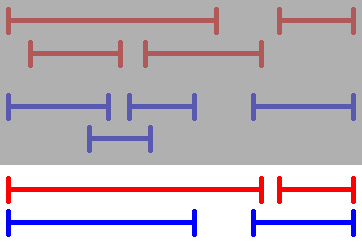
RĂ©sultat de l’agrĂ©gation des intervalles par couleurs.
En anglais cette fonction s’appelle « packing intervals ».
Exemple :
Partant de la table (SQL Server, les versions pour MySQL et PostGreSQL sont exposées ci après) :
CREATE TABLE T_INTERVAL_ITV
( ITV_ID INT NOT NULL IDENTITY PRIMARY KEY,
ITV_ITEM VARCHAR(16) NOT NULL,
ITV_DEBUT DATETIME2(0) NOT NULL,
ITV_FIN DATETIME2(0) NOT NULL,
CONSTRAINT CHK_ITV_FIN_DEBUT CHECK (ITV_FIN >= ITV_DEBUT));
contenant les données suivantes :
INSERT INTO T_INTERVAL_ITV VALUES('Item1', '2011-12-01 08:00:00', '2011-12-01 08:30:00');
INSERT INTO T_INTERVAL_ITV VALUES('Item1', '2011-12-01 08:00:00', '2011-12-01 08:30:00');
INSERT INTO T_INTERVAL_ITV VALUES('Item1', '2011-12-01 08:30:00', '2011-12-01 09:00:00');
INSERT INTO T_INTERVAL_ITV VALUES('Item1', '2011-12-01 09:00:00', '2011-12-01 09:30:00');
INSERT INTO T_INTERVAL_ITV VALUES('Item1', '2011-12-01 10:00:00', '2011-12-01 11:00:00');
INSERT INTO T_INTERVAL_ITV VALUES('Item1', '2011-12-01 10:30:00', '2011-12-01 12:00:00');
INSERT INTO T_INTERVAL_ITV VALUES('Item1', '2011-12-01 11:30:00', '2011-12-01 12:30:00');
INSERT INTO T_INTERVAL_ITV VALUES('Item2', '2011-12-01 08:00:00', '2011-12-01 10:30:00');
INSERT INTO T_INTERVAL_ITV VALUES('Item2', '2011-12-01 08:30:00', '2011-12-01 10:00:00');
INSERT INTO T_INTERVAL_ITV VALUES('Item2', '2011-12-01 09:00:00', '2011-12-01 09:30:00');
INSERT INTO T_INTERVAL_ITV VALUES('Item2', '2011-12-01 11:00:00', '2011-12-01 11:30:00');
INSERT INTO T_INTERVAL_ITV VALUES('Item2', '2011-12-01 11:32:00', '2011-12-01 12:00:00');
INSERT INTO T_INTERVAL_ITV VALUES('Item2', '2011-12-01 12:04:00', '2011-12-01 12:30:00');
INSERT INTO T_INTERVAL_ITV VALUES('Item3', '2011-12-01 08:00:00', '2011-12-01 09:00:00');
INSERT INTO T_INTERVAL_ITV VALUES('Item3', '2011-12-01 08:00:00', '2011-12-01 08:30:00');
INSERT INTO T_INTERVAL_ITV VALUES('Item3', '2011-12-01 08:30:00', '2011-12-01 09:00:00');
INSERT INTO T_INTERVAL_ITV VALUES('Item3', '2011-12-01 09:30:00', '2011-12-01 09:30:00');
Comment obtenir le résultat suivant, qui compacte les périodes qui se chevauchent :
ITV_ITEM ITV_DEBUT ITV_FIN
--------- ----------------------- -----------------------
Item1 2011-12-01 08:00:00 2011-12-01 09:30:00
Item1 2011-12-01 10:00:00 2011-12-01 12:30:00
Item2 2011-12-01 08:00:00 2011-12-01 10:30:00
Item2 2011-12-01 11:00:00 2011-12-01 11:30:00
Item2 2011-12-01 11:32:00 2011-12-01 12:00:00
Item2 2011-12-01 12:04:00 2011-12-01 12:30:00
Item3 2011-12-01 08:00:00 2011-12-01 09:00:00
Item3 2011-12-01 09:30:00 2011-12-01 09:30:00
Dans cet article, nous avions publié plusieurs méthodes de calculs.
Les voici, adaptées à la table de notre exemple :
1 – solution « classique »
WITH
T0 AS
(SELECT PRE.ITV_ITEM,
PRE.ITV_DEBUT AS D1, PRE.ITV_FIN AS F1,
DER.ITV_DEBUT AS D2, DER.ITV_FIN AS F2
FROM T_INTERVAL_ITV PRE
INNER JOIN T_INTERVAL_ITV DER
ON PRE.ITV_DEBUT <= DER.ITV_FIN
AND PRE.ITV_ITEM = DER.ITV_ITEM)
SELECT DISTINCT ITV_ITEM, D1 AS ITV_DEBUT, F2 AS ITV_FIN
FROM T0 AS I
WHERE NOT EXISTS (SELECT *
FROM T_INTERVAL_ITV SI1
WHERE (SI1.ITV_DEBUT < I.D1
AND I.D1 <= SI1.ITV_FIN
AND I.ITV_ITEM = SI1.ITV_ITEM )
OR (SI1.ITV_DEBUT <= I.F2
AND I.F2 < SI1.ITV_FIN
AND I.ITV_ITEM = SI1.ITV_ITEM))
AND NOT EXISTS (SELECT *
FROM T_INTERVAL_ITV SI2
WHERE D1 < SI2.ITV_DEBUT
AND SI2.ITV_DEBUT <= F2
AND I.ITV_ITEM = SI2.ITV_ITEM
AND NOT EXISTS (SELECT *
FROM T_INTERVAL_ITV SI3
WHERE SI3.ITV_DEBUT < SI2.ITV_DEBUT
AND SI2.ITV_DEBUT <= SI3.ITV_FIN
AND SI2.ITV_ITEM = SI3.ITV_ITEM ));
2 – solution classique avec table dĂ©rivĂ©e ou CTE par SnodGrass
WITH T
AS (SELECT F.ITV_DEBUT, L.ITV_FIN, F.ITV_ITEM
FROM T_INTERVAL_ITV AS F
JOIN T_INTERVAL_ITV AS L
ON F.ITV_FIN <= L.ITV_FIN
AND F.ITV_ITEM = L.ITV_ITEM
INNER JOIN T_INTERVAL_ITV AS E
ON F.ITV_ITEM = E.ITV_ITEM
GROUP BY F.ITV_DEBUT, L.ITV_FIN, F.ITV_ITEM
HAVING COUNT(CASE
WHEN (E.ITV_DEBUT < F.ITV_DEBUT AND F.ITV_DEBUT <= E.ITV_FIN)
OR (E.ITV_DEBUT <= L.ITV_FIN AND L.ITV_FIN < E.ITV_FIN)
THEN 1
END) = 0)
SELECT ITV_ITEM, ITV_DEBUT, MIN(ITV_FIN) AS ITV_FIN
FROM T
GROUP BY ITV_ITEM, ITV_DEBUT;
3 – solution rĂ©cursive (F. Brouard)
WITH
T0 AS -- suprime les périodes incluses
(SELECT DISTINCT Tout.ITV_ITEM, Tout.ITV_DEBUT, Tout.ITV_FIN
FROM T_INTERVAL_ITV AS Tout
WHERE NOT EXISTS(SELECT *
FROM T_INTERVAL_ITV AS Tin
WHERE Tout.ITV_DEBUT >= Tin.ITV_DEBUT
AND Tout.ITV_FIN < Tin.ITV_FIN
AND Tout.ITV_ITEM = Tin.ITV_ITEM)),
T1 AS -- ancres : périodes de tête...
(SELECT Ta.*, 1 AS ITERATION
FROM T0 AS Ta
WHERE NOT EXISTS(SELECT *
FROM T0 AS Tb
WHERE Tb.ITV_FIN >= Ta.ITV_DEBUT
AND Tb.ITV_FIN < Ta.ITV_FIN
AND Tb.ITV_ITEM = Ta.ITV_ITEM)
UNION ALL -- itération sur période dont le debut est inclus dans les bornes de la période ancre
SELECT T1.ITV_ITEM, T1.ITV_DEBUT, T0.ITV_FIN, T1.ITERATION + 1
FROM T1
INNER JOIN T0
ON T1.ITV_DEBUT < T0.ITV_DEBUT
AND T1.ITV_FIN >= T0.ITV_DEBUT
AND T1.ITV_FIN < T0.ITV_FIN
AND T1.ITV_ITEM = T0.ITV_ITEM),
T2 AS
(SELECT *, ROW_NUMBER() OVER(PARTITION BY ITV_ITEM, ITV_DEBUT ORDER BY DATEDIFF(s, ITV_DEBUT, ITV_FIN) DESC) AS N1,
ROW_NUMBER() OVER(PARTITION BY ITV_ITEM, ITV_FIN ORDER BY DATEDIFF(s, ITV_DEBUT, ITV_FIN) DESC) AS N2
FROM T1)
SELECT ITV_ITEM, ITV_DEBUT, ITV_FIN, N1, N2
FROM T2
WHERE N1 = 1 AND N2 = 1;
4 – solution de GeriReshef
Elle utilise les fonctions de fenĂŞtrage.
WITH T1 As
(SELECT ITV_ITEM, ITV_DEBUT Temps
FROM T_INTERVAL_ITV
UniON All
SELECT ITV_ITEM, ITV_FIN FROM T_INTERVAL_ITV),
T2 As
(SELECT Row_Number() OVER(PARTITION BY ITV_ITEM ORDER BY Temps) Nm, ITV_ITEM, Temps
FROM T1 T1_1),
T3 As
(SELECT T2_1.Nm-Row_Number() OVER(PARTITION BY T2_1.ITV_ITEM ORDER BY T2_1.Temps,T2_2.Temps) Nm1,
T2_1.ITV_ITEM, T2_1.Temps ITV_DEBUT, T2_2.Temps ITV_FIN
FROM T2 T2_1
Inner join T2 T2_2
ON T2_1.ITV_ITEM=T2_2.ITV_ITEM
And T2_1.Nm=T2_2.Nm-1
WHERE Exists (SELECT *
FROM T_INTERVAL_ITV S
WHERE S.ITV_ITEM=T2_1.ITV_ITEM
And (S.ITV_DEBUT < T2_2.Temps And S.ITV_FIN>T2_1.Temps))
Or T2_1.Temps = T2_2.Temps)
SELECT ITV_ITEM, Min(ITV_DEBUT) ITV_DEBUT, Max(ITV_FIN) ITV_FIN
FROM T3
GROUP BY ITV_ITEM, Nm1
5 – solution de Malpashaa n°1
Elle utilise les fonctions de fenêtrage, mais aussi le CROSS APPLY (intrajointure) spécifique à MS SQL Server.
WITH T_DEBUT AS
(
SELECT U.ITV_ITEM, ST.ITV_DEBUT,
ROW_NUMBER() OVER(PARTITION BY U.ITV_ITEM ORDER BY ST.ITV_DEBUT) AS row_num
FROM (SELECT DISTINCT ITV_ITEM
FROM T_INTERVAL_ITV) AS U
CROSS APPLY (SELECT DISTINCT S1.ITV_DEBUT
FROM (SELECT S.ITV_DEBUT, ROW_NUMBER() OVER(ORDER BY S.ITV_DEBUT) AS row_num
FROM T_INTERVAL_ITV AS S
WHERE S.ITV_ITEM = U.ITV_ITEM) AS S1
LEFT OUTER JOIN (SELECT S.ITV_FIN, ROW_NUMBER() OVER(ORDER BY S.ITV_DEBUT) AS row_num
FROM T_INTERVAL_ITV AS S
WHERE S.ITV_ITEM = U.ITV_ITEM) AS S2
ON S2.row_num = S1.row_num - 1
AND S2.ITV_FIN >= S1.ITV_DEBUT
WHERE S2.row_num IS NULL) AS ST),
T_FIN AS
(SELECT U.ITV_ITEM, ET.ITV_FIN, ROW_NUMBER() OVER(PARTITION BY U.ITV_ITEM ORDER BY ET.ITV_FIN) AS row_num
FROM (SELECT DISTINCT ITV_ITEM
FROM T_INTERVAL_ITV) AS U
CROSS APPLY (SELECT DISTINCT S1.ITV_FIN
FROM (SELECT S.ITV_FIN, ROW_NUMBER() OVER(ORDER BY S.ITV_FIN) AS row_num
FROM T_INTERVAL_ITV AS S
WHERE S.ITV_ITEM = U.ITV_ITEM) AS S1
LEFT OUTER JOIN (SELECT S.ITV_DEBUT, ROW_NUMBER() OVER(ORDER BY S.ITV_FIN) AS row_num
FROM T_INTERVAL_ITV AS S
WHERE S.ITV_ITEM = U.ITV_ITEM) AS S2
ON S2.row_num = S1.row_num + 1
AND S2.ITV_DEBUT <= S1.ITV_FIN
WHERE S2.row_num IS NULL) AS ET)
SELECT TD.ITV_ITEM, TD.ITV_DEBUT, TF.ITV_FIN
FROM T_DEBUT AS TD
INNER JOIN T_FIN AS TF
ON TF.ITV_ITEM = TD.ITV_ITEM
AND TF.row_num = TD.row_num
6 – solution de Malpashaa n°2
Elle utilise les mêmes outils que la précédente (fenêtrage et intrajointure).
SELECT U.ITV_ITEM, ST.ITV_DEBUT, ET.ITV_FIN
FROM (SELECT DISTINCT ITV_ITEM
FROM T_INTERVAL_ITV) AS U
CROSS APPLY (SELECT ST.ITV_DEBUT, ROW_NUMBER() OVER(ORDER BY ST.ITV_DEBUT) AS row_num
FROM (SELECT DISTINCT S1.ITV_DEBUT
FROM (SELECT S.ITV_DEBUT, ROW_NUMBER() OVER(ORDER BY S.ITV_DEBUT) AS row_num
FROM T_INTERVAL_ITV AS S
WHERE S.ITV_ITEM = U.ITV_ITEM) AS S1
LEFT OUTER JOIN (SELECT S.ITV_FIN, ROW_NUMBER() OVER(ORDER BY S.ITV_DEBUT) AS row_num
FROM T_INTERVAL_ITV AS S
WHERE S.ITV_ITEM = U.ITV_ITEM) AS S2
ON S2.row_num = S1.row_num - 1
AND S2.ITV_FIN >= S1.ITV_DEBUT
WHERE S2.row_num IS NULL) AS ST) AS ST
CROSS APPLY (SELECT ET.ITV_FIN, ROW_NUMBER() OVER(ORDER BY ET.ITV_FIN) AS row_num
FROM (SELECT DISTINCT S1.ITV_FIN
FROM (SELECT S.ITV_FIN, ROW_NUMBER() OVER(ORDER BY S.ITV_FIN) AS row_num
FROM T_INTERVAL_ITV AS S
WHERE S.ITV_ITEM = U.ITV_ITEM) AS S1
LEFT OUTER JOIN (SELECT S.ITV_DEBUT, ROW_NUMBER() OVER(ORDER BY S.ITV_FIN) AS row_num
FROM T_INTERVAL_ITV AS S
WHERE S.ITV_ITEM = U.ITV_ITEM) AS S2
ON S2.row_num = S1.row_num + 1
AND S2.ITV_DEBUT <= S1.ITV_FIN
WHERE S2.row_num IS NULL) AS ET) AS ET
WHERE ET.row_num = ST.row_num
7 – solution de Stefan Gustafsson
Elle utilise une table temporaire, les fonctions de fenĂŞtrage, l’intra-jointure et une fonction table de nombres….
IF object_id('tempdb..#intervals') is not null
DROP TABLE #intervals;
WITH
cte1 AS
(
SELECT *, DATEDIFF(hour, 0, ITV_DEBUT)+n-1 AS hash
FROM T_INTERVAL_ITV
CROSS APPLY dbo.F_NUM(DATEDIFF(hour, 0, ITV_FIN)-datediff(hour, 0, ITV_DEBUT)+1) t
),
cte2 AS
(
SELECT DISTINCTITV_ITEM, ITV_FIN
FROM T_INTERVAL_ITV a
WHERE NOT EXISTS(SELECT *
FROM cte1 b
WHERE a.ITV_ITEM=b.ITV_ITEM
AND b.ITV_DEBUT<=a.ITV_FIN
AND b.ITV_FIN>a.ITV_FIN
AND b.hash=datediff(hour, 0, a.ITV_FIN))
)
SELECT *, ROW_NUMBER() OVER (PARTITION BY ITV_ITEM ORDER BY ITV_FIN) as rn
into #intervals
FROM cte2;
-- add informatiON about the start of each interval by locating the first sessiON after each interval
with
cte1 AS
(
SELECT a.ITV_ITEM, a.ITV_FIN, isnull(b.ITV_FIN,'19000101') as pe
FROM #intervals a
LEFT OUTER JOIN #intervals b
ON a.ITV_ITEM=b.ITV_ITEM and a.rn=b.rn+1
),
cte2 AS
(
SELECT ITV_ITEM,
(SELECT MIN(b.ITV_DEBUT)
FROM T_INTERVAL_ITV b
WHERE a.ITV_ITEM=b.ITV_ITEM and b.ITV_DEBUT>a.pe) as ITV_DEBUT,
ITV_FIN
FROM cte1 a
),
cte3 AS
(
SELECT ITV_ITEM, ITV_DEBUT, MAX(DATEDIFF(s, ITV_DEBUT, ITV_FIN)) AS DURATION
FROM cte2
WHERE ITV_DEBUT IS NOT NULL
GROUP BY ITV_ITEM, ITV_DEBUT
)
SELECT ITV_ITEM, ITV_DEBUT, DATEADD(ms, DURATION, ITV_DEBUT) AS ITV_FIN
FROM cte3
NOTA : on peut rĂ©cire cette dernière solution sous la forme d’une seule requĂŞte :
WITH
cte1 AS
(
SELECT *, datediff(hour, 0, ITV_DEBUT)+n-1 AS hash
FROM T_INTERVAL_ITV
cross apply dbo.F_NUM(datediff(hour, 0, ITV_FIN)-datediff(hour, 0, ITV_DEBUT)+1) t
),
cte2 AS
(
SELECT distinct ITV_ITEM, ITV_FIN
FROM T_INTERVAL_ITV a
WHERE not exists(SELECT *
FROM cte1 b
WHERE a.ITV_ITEM=b.ITV_ITEM
and b.ITV_DEBUT<=a.ITV_FIN
and b.ITV_FIN>a.ITV_FIN
and b.hash=datediff(hour, 0, a.ITV_FIN))
),
cte3 AS
(
SELECT *, row_number() OVER (PARTITION BY ITV_ITEM ORDER BY ITV_FIN) as rn
FROM cte2
),
-- add informatiON about the start of each interval by locating the first sessiON after each interval
cte4 AS
(
SELECT a.ITV_ITEM, a.ITV_FIN, isnull(b.ITV_FIN,'19000101') as pe
FROM cte3 a
left OUTER join cte3 b
ON a.ITV_ITEM=b.ITV_ITEM and a.rn=b.rn+1
),
cte5 AS
(
SELECT ITV_ITEM,
(SELECT min(b.ITV_DEBUT)
FROM T_INTERVAL_ITV b
WHERE a.ITV_ITEM=b.ITV_ITEM and b.ITV_DEBUT>a.pe) as ITV_DEBUT,
ITV_FIN
FROM cte4 a
),
cte6 AS
(
SELECT ITV_ITEM, ITV_DEBUT, MAX(DATEDIFF(s, ITV_DEBUT, ITV_FIN)) AS DURATION
FROM cte5
WHERE ITV_DEBUT IS NOT NULL
GROUP BY ITV_ITEM, ITV_DEBUT
)
SELECT ITV_ITEM, ITV_DEBUT, DATEADD(ms, DURATION, ITV_DEBUT) AS ITV_FIN
FROM cte6
CONDITION DES TESTS
Caractéristique de la machine de test :
– HP xw4600 Workstation
– CPU Intel Core 2 Quad CPU (Q9450) cadencĂ© Ă 2.66 Ghz
– RAM : 3,5 Go
– OS : Windows XP Pro SP2 32 bits
Les installations des SGBDR ont Ă©tĂ© effectuĂ©es de manière standard Ă partir des tĂ©lĂ©chargement disponible sur Interet. Aucun paramĂ©trage système ni SGBDR n’a Ă©tĂ© effectuĂ© sur aucun SGBDR en particulier.
Les tests ont Ă©tĂ© lancĂ© alors qu’aucun autre applicatif ne tournait.
TESTS avec SQL Server 2008 R2 (client SSMS)
Temps d’exĂ©cution sans indexation (1000, 3000 et 10 000 lignes dans la table) :
Lignes m Sol. 1 Sol. 2 Sol. 3 Sol. 4 Sol. 5 Sol. 6 Sol. 7
------- - --------------- ----------- ---------- ------- ------ ------- -------
1 000 d 26 787 4 370 846 130 107 367 746
c 26 078 12 233 562 62 31 343 514
a 36 182 35 2 442 1 995 42 1 273 2 800
l 289 456 107 089 24 399 6 481 336 10 184 97 76
3 000 d 429 767 197 300 4 346 406 137 137 1 093
c 1 090 704 484 968 4 282 344 31 157 1 280
a 312 480 18 6 307 5 992 42 55 8 298
l 5 624 476 8 151 436 135 321 24 311 756 8 151 31 439
10 000 d 6 352 003 982 463 43 100 786 260 357 3 430
c 18 345 749 2 973 080 42 750 1 294 125 782 4 889
a 1 805 119 55 20 951 19 993 82 105 28 000
l 101 086 196 10 100 933 1 245 360 97 914 4 592 35 971 113 753
Temps d’exĂ©cution avec indexation (1000, 3000 et 10 000 lignes dans la table) :
Lignes m Sol. 1 Sol. 2 Sol. 3 Sol. 4 Sol. 5 Sol. 6 Sol. 7
------- - --------------- ----------- ---------- ------- ------- ------- ------
1 000 d 1 317 1 353 140 53 77 230 277
c 1 141Â 79 438 47 31 0 203 237
a 76 672 50 511 2 542 1 991 42 1 233 1 589
l 164 414 141 441 9 672 5 210 134 3 465 2 701
3 000 d 13 723 32 034 373 153 117 114 790
c 33 281 484 968 265 78 16 170 516
a 422 455 451 510 7 609 5 990 42 45 9 100
l 1 209 104 2 347 898 30 972 15 069 258 7 692 31 439
10 000 d 11 651 720 276 880 16 497 440 223 307 2 470
c 33 989 656 784 001 16 281 296 93 626 1 813
a 1 747 887 2 505 015 30 306 19 973 82 105 15 912
l 1 410 898 170 16 971 803 1 325 129 56 501 680 31711 32 247
« m » signifie « mesure » et ces mesures sont :
– d : durĂ©e du traitement en millisecondes
– c : durĂ©e d’utilisation du CPU en millisecondes
– a : nombre d’analyses (parcours d’index)
– l : nombre de lectures logiques (IO)
NOTA : il est normal de trouver un temps CPU plus long que le temps écoulé, les tests ayant été efectué sur une machine utilisant un processeur quadri coeur.
Les tests ont été poursuivi uniquement avec la solution 5 :
Lignes m Solution 5
------------ - -----------
30 000 d 924
c 172
a 162
l 1 894
100 000 d 1 647
c 703
a 402
l 5 734
300 000 d 8 846
c 2 235
a 802
l 15 402
1 000 000 d 15 773
c 10 341
a 2 010
l 50 212
3 000 000 d 42 147
c 25 578
a 4 002
l 139 702
Les index posés sont les suivants :
CREATE INDEX X_ITV_ITM_FIN_DEB ON T_INTERVAL_ITV(ITV_ITEM, ITV_FIN, ITV_DEBUT);
CREATE INDEX X_ITV_ITM_DEB_I_FIN ON T_INTERVAL_ITV(ITV_ITEM, ITV_DEBUT) INCLUDE (ITV_FIN);
CREATE INDEX X_ITV_ITM_DEB_FIN ON T_INTERVAL_ITV(ITV_ITEM, ITV_DEBUT, ITV_FIN);
Dans l’ordre, les algorithmes les plus efficaces en terme de durĂ©e intrinsèque sont : 5, 6, 4, 7, 3, 2 et 1. Le classement ne change d’ailleurs pas lors de l’indexation. Pour 10 000 lignes, les algorithmes suivants dĂ©passent la seconde en durĂ©e d’exĂ©cution : 7, 3, 2, 1 (mĂŞme avec indexation).
Pour la suite du test, nous les avons Ă©liminĂ©s et nous avons continuĂ© le test jusqu’Ă 10 millions de lignes sur un serveur donc les caractĂ©ristiques sont les suivantes : HP DL 385 G2 Opteron Dual Core 2,40 Ghz, RAM 10 Go / Windows 2008 server 64 bits / MS SQL Server 2008 Enterprise 64 bits.
Lignes m Sol. 4 Sol. 5 Sol. 6
----------- - ------------ ------------ ------------
1 000 d 263 297 366
c 31 16 312
a 0 42 1 307
l 1 994 134 3 673
3 000 d 360 140 140
c 218 15 156
a 5 993 42 55
l 15 030 252 7 667
10 000 d 1 290 220 390
c 1 076 125 842
a 19 974 82 95
l 56 770 686 31 953
30 000 d 2 350 580 1 380
c 1 529 281 3 432
a 59 938 162 205
l 186 173 1 862 95 262
100 000 d 8 400 1 336 5 164
c 6 084 905 15 067
a 199 833 402 505
l 884 699 5 848 379 187
300 000 d 34 167 4 130 24 583
c 22 979 3 088 64 505
a 599 572 802 1 005
l 2 926 484 15 237 1 321 308
1 000 000 d 120 153 8 787 118 716
c 92 914 13 135 275 451
a 2 161 497 2 010 2 505
l 11 500 895 50 542 5 021 976
3 000 000 d 157 564 38 280 649 486
c 444 704 27 113 1 273 512
a 5 996 798 4 002 5 005
l 38 274 039 139 840 25 593 284
On constatera que dans les grandes cardinalitĂ©s, la solution 6 qui s’avĂ©rait l’une des meilleures commence Ă plonger rapidement. Cela est sans doute du Ă un changement de plan. En dĂ©finitive la meilleure solution est la 5 (première requĂŞte de Malpashaa).
TEST avec MySQL 5.5 InnoDB (Client Toad for MySQL) :
Seules les deux premières requĂŞtes peuvent s’exĂ©cuter sur MySQL. En effet ce SGBDR fortement Ă la traĂ®ne en matière de SQL, n’implĂ©mente toujours pas les fonctions de fenĂŞtrage introduite avec la norme SQL de 2003… ni bien entendu le CROSS APPLY (intra jointure) spĂ©cificitĂ© de MS SQL Server. C’est pourquoi seules les deux premières requĂŞtes ont Ă©tĂ© jouĂ©es avec les index (voir script de test ci après).
Les résultats de durée en millisecondes sont les suivants :
Lignes Classique (1) Snodgrass (2)
--------- ------------- --------------
1 000 6 312 20 453
3 000 37 798 abandon(1)
10 000 1 326 316 --> soit plus de 22 minutes pour la version classique...
30 000 abandon(1)
(1) après plus de 30 minutes de traitement.
MySQL comparé à SQL Server :
Comparaisons sur requĂŞtes identiques :
Si l’on compare avec MS SQL Server Ă MySQL, et pour les requĂŞtes identiques, les rĂ©sultats sont les suivants :
Solution classique : MySQL va de 5 fois moins rapide Ă 9 fois plus (10 000 lignes).
Si on compare MySQL à SQL Server version non indexée, la différence est moindre.
Solution Snodgrass : 15 fois moins rapide avant abandon (plus de 30 minutes).
Comparaisons sur les meilleurs résultats de MySQL aux meilleurs résultats de SQL Server :
Si l’on compare les meilleurs rĂ©sultats de MySQL aux meilleurs de SQL Server, la diffĂ©rence est Ă©norme :
1 000 lignes : MySQL est 59 fois moins rapide
3 000 lignes : MySQL est 275 fois moins rapide
10 000 lignes : MySQL est 5947 fois moins rapide
Enfin, Ă partir de 3 000 lignes MySQL met, dans le meilleur des cas, dĂ©jĂ plus de 30 minutes pour offrir un rĂ©sultat, ce qui est inexploitable en production, alors que SQL Server, sur la mĂŞme machine et pour la meilleure requĂŞte ne dĂ©passe les trente secondes qu’après 1 millions de ligne, soit un Ă©cart de 333 fois !
Pour un SGBDR qui se targue d’ĂŞtre le meilleur ce benchmark est sans concession. MySQL est inexploitable avec des requĂŞtes quelque peu complexes et dès que la volumĂ©trie dĂ©passe quelque milliers de lignes !
TEST avec PostGreSQL 8.4 (Client pgAdminIII) :
4 requĂŞtes peuvent s’effectuer sur PostGreSQL. C’est Ă dire toutes sauf celles implĂ©mentant l’intrajointure (opĂ©rateur CROSS APPLY). Ce sont les requĂŞtes Classique (1), Snodgrass (2), rĂ©cursive (3), GeriReshef (4).
Voici les durées des requêtes :
Lignes 1 - Classique 2 - Snodgrass 3 - récursive 4 - GeriReshef
--------------- --------------- --------------- --------------- ----------------
1 000 625 25 734 2 593 281
3 000 12 921 abandon (2) 557 485 312
10 000 59 015 abandon (1) 1 297
30 000 222 516 3 984
100 000 607 296 15 641
300 000 abandon (1) 117 719
1 000 000 466 468
(1) abandon au bout de 30 minutes sans résultat
(2) abandon, la requête ayant durée 55 minutes et 20 secondes
PostGresSQL comparé à SQL Server :
Comparaisons sur requĂŞtes identiques :
Pour la solution 1, PG est plus rapide, entre 29 et 43 fois
Pour la solution 2, PG est moins rapide de 6
Pour la solution 3, PG est moins rapide de 3 Ă 128 fois
Pour la solution 4, PG est moins rapide, d’environ 3 fois.
Comparaisons sur les meilleurs résultats de PostGreSQL aux meilleurs résultats de SQL Server :
IntrisĂ©quement, pour la comparaison des meilleures solutions, (version 5 pour SQL Server et version 4 pour PostGreSQL), PostGreSQL est entre 3 et 13 fois moins rapide que SQL Server, tant qu’on n’atteint pas le million de lignes ou l’Ă©cart devient alors important (30 fois, peu ĂŞtre Ă cause du manque de cache…), ce qui est très honorable, sachant que PostGreSQL ne sait toujours pas multithreader une mĂŞme requĂŞte et donc jouer ses traitements en parallèle.
PostGresSQL comparé à MySQL :
Comparaisons sur requĂŞtes identiques :
Pour la solution 1, PG est plus rapide, entre 3 et 22 fois
Pour la solution 2, PG est moins rapide de 1,25 fois
Comparaisons sur les meilleurs résultats de PostGreSQL face aux meilleurs résultats de MySQL :
IntrisĂ©quement, pour la comparaison des meilleures solutions, (version 4 pour postGreSQL et version 1 pour MySQL), PostGreSQL est entre 22 et 1022 fois plus rapide que MySQL, ce qui est très Ă©norme. Ceci est sans aucun doute du Ă la qualitĂ© de son optmiseur, qui, bien que loin d’Ă©galer ceux d’Oracle ou SQL Server sur certaines subtilitĂ©s, sait se dĂ©brouiller relativement bien avec les index qu’on lui donne.
Bref, on ne peut qu’encourager les utilisateurs dĂ©sirant du vrai libre Ă prendre PostGreSQL compte tenu de la diffĂ©rence de performances et du manque cinglant des fonctionnalitĂ©s de MySQL. Quand Ă ceux qui dĂ©sire des performances extrĂŞmes, ils peuvent se tourner vers SQL Server, qui existe en version gratuite, quoique bridĂ©e avec SQL Server Express 2008 R2 permettant des bases jusqu’Ă 10 Go. Mais après, il faut payer !
COMPARAISON GLOBALES
| SQL Server | PostGreSQL | MySQL
-------------------|------------|------------|------------
Nombre de ligne | 3 000 000 | 300 000 | 3 000
traitées en 120 s | | |
-------------------|------------|------------|------------
Différence de | 0 % | 90 % | 99,9 %
performances | 0 | 10 fois - | 1000 fois -
ADDENDUM – SCRIPTS SQL
Du aux « alĂ©as » des gĂ©nĂ©rateurs alĂ©atoires incorporĂ©s dans les diffĂ©rentes SGBDR, nous n’avons pas produit un code identique pour la gĂ©nĂ©ration des lignes, mais ajustĂ© chaque code afin que la cardinalitĂ© du rĂ©sultat soit homogène.
Script pour MS SQL Server
Voici comment nous avons généré les lignes en grand nombre pour nos essais :
-- création d'une fonction table de génération de nombre pour aider au remplissage
CREATE FUNCTION F_NUM (@max_num INT)
RETURNS @T TABLE (n INT)
AS
BEGIN
IF @max_num <0 RETURN;
DECLARE @N INT;
SET @N = 1;
WHILE @N <= @max_num
BEGIN
INSERT INTO @T VALUES (@N)
SET @N = @N + 1;
END
RETURN;
END
GO
-- Procédure de génération de lignes (n items x m intervals) aléatoires
CREATE PROCEDURE P_GENERATE_ROWS
@debut_interval DATETIME2(0),
@num_items INT,
@intervals_par_item INT,
@duree_max_ms INT
AS
DECLARE @fin_interval DATETIME2(0)
SET @fin_interval = DATEADD(day, CAST(FLOOR(0.04 * @intervals_par_item) AS INT), @debut_interval);
TRUNCATE TABLE T_INTERVAL_ITV;
WITH T AS
(SELECT 'Item' + RIGHT('000000000' + CAST(U.n AS VARCHAR(10)), 10) AS ITV_ITEM,
DATEADD(ms, ABS(CHECKSUM(NEWID())) % 86400000,
DATEADD(day, ABS(CHECKSUM(NEWID())) % DATEDIFF(day, @debut_interval, @fin_interval), @debut_interval)) AS ITV_DEBUT
FROM F_NUM(@num_items) AS U
CROSS JOIN F_NUM(@intervals_par_item) AS I)
INSERT INTO T_INTERVAL_ITV
(ITV_ITEM, ITV_DEBUT, ITV_FIN)
SELECT ITV_ITEM, ITV_DEBUT, DATEADD(ms, ABS(CHECKSUM(NEWID())) % (@duree_max_ms + 1), ITV_DEBUT) AS ITV_FIN
FROM T;
GO
Script pour MySQL :
/* création de la table : */
CREATE TABLE T_INTERVAL_ITV
( ITV_ID INT NOT NULL AUTO_INCREMENT PRIMARY KEY,
ITV_ITEM VARCHAR(16) NOT NULL,
ITV_DEBUT TIMESTAMP NOT NULL,
ITV_FIN TIMESTAMP NOT NULL,
CONSTRAINT CHK_ITV_FIN_DEBUT CHECK (ITV_FIN >= ITV_DEBUT));
CREATE INDEX X_ITV_ITM_FIN_DEB
ON T_INTERVAL_ITV(ITV_ITEM, ITV_FIN, ITV_DEBUT);
CREATE INDEX X_ITV_ITM_DEB_FIN
ON T_INTERVAL_ITV(ITV_ITEM, ITV_DEBUT, ITV_FIN);
delimiter |
/* création de la procédure de génération des lignes : */
CREATE PROCEDURE P_GENERATE_ROWS (
debut_interval TIMESTAMP,
num_items INT,
intervals_par_item INT,
duree_max_s INT)
LANGUAGE SQL
DETERMINISTIC
MODIFIES SQL DATA
BEGIN
DECLARE fin_interval TIMESTAMP;
DECLARE i, j INT;
DECLARE itm VARCHAR(16);
DECLARE d, f TIMESTAMP;
DECLARE duree INT;
SET fin_interval = DATE_ADD(debut_interval, INTERVAL duree_max_s SECOND);
SET i = 1;
SET j = 1;
whileI: WHILE i <= num_items DO
whileJ: WHILE j <= intervals_par_item DO
SET d = DATE_ADD(debut_interval, INTERVAL RAND() * duree_max_s * 10 SECOND);
SET duree = FLOOR(RAND() * duree_max_s);
SET f = DATE_ADD(d, INTERVAL duree SECOND);
SET itm = CONCAT('Item', i);
INSERT INTO T_INTERVAL_ITV (ITV_ITEM, ITV_DEBUT, ITV_FIN) VALUES (itm, d, f);
SET j = j + 1;
END WHILE whileJ;
SET j = 1;
SET i = i + 1;
END WHILE whileI;
END
|
/* génération des lignes de la table : */
TRUNCATE TABLE t_interval_itv;
CALL P_GENERATE_ROWS ('2001-01-01', 10, 100, 3600); /* test avec 1 000 lignes */
/* 1 - solution "classique" */
SELECT DISTINCT ITV_ITEM, D1 AS ITV_DEBUT, F2 AS ITV_FIN
FROM (SELECT PRE.ITV_ITEM,
PRE.ITV_DEBUT AS D1, PRE.ITV_FIN AS F1,
DER.ITV_DEBUT AS D2, DER.ITV_FIN AS F2
FROM T_INTERVAL_ITV PRE
INNER JOIN T_INTERVAL_ITV DER
ON PRE.ITV_DEBUT <= DER.ITV_FIN
AND PRE.ITV_ITEM = DER.ITV_ITEM) AS I
WHERE NOT EXISTS (SELECT *
FROM T_INTERVAL_ITV SI1
WHERE (SI1.ITV_DEBUT < I.D1
AND I.D1 <= SI1.ITV_FIN
AND I.ITV_ITEM = SI1.ITV_ITEM )
OR (SI1.ITV_DEBUT <= I.F2
AND I.F2 < SI1.ITV_FIN
AND I.ITV_ITEM = SI1.ITV_ITEM))
AND NOT EXISTS (SELECT *
FROM T_INTERVAL_ITV SI2
WHERE D1 < SI2.ITV_DEBUT
AND SI2.ITV_DEBUT <= F2
AND I.ITV_ITEM = SI2.ITV_ITEM
AND NOT EXISTS (SELECT *
FROM T_INTERVAL_ITV SI3
WHERE SI3.ITV_DEBUT < SI2.ITV_DEBUT
AND SI2.ITV_DEBUT <= SI3.ITV_FIN
AND SI2.ITV_ITEM = SI3.ITV_ITEM ));
/* 2 - solution SnodGrass */
SELECT ITV_ITEM, ITV_DEBUT, MIN(ITV_FIN) AS ITV_FIN
FROM (SELECT F.ITV_DEBUT, L.ITV_FIN, F.ITV_ITEM
FROM T_INTERVAL_ITV AS F
INNER JOIN T_INTERVAL_ITV AS L
ON F.ITV_FIN <= L.ITV_FIN
AND F.ITV_ITEM = L.ITV_ITEM
INNER JOIN T_INTERVAL_ITV AS E
ON F.ITV_ITEM = E.ITV_ITEM
GROUP BY F.ITV_DEBUT, L.ITV_FIN, F.ITV_ITEM
HAVING COUNT(CASE
WHEN (E.ITV_DEBUT < F.ITV_DEBUT AND F.ITV_DEBUT <= E.ITV_FIN)
OR (E.ITV_DEBUT <= L.ITV_FIN AND L.ITV_FIN < E.ITV_FIN)
THEN 1
END) = 0) AS T
GROUP BY ITV_ITEM, ITV_DEBUT;
Le test a été recommencé avec 3 000 lignes, puis 10 000 lignes.
Script pour PostGreSQL
-- création de la table :
CREATE TABLE t_interval_itv
(
itv_id serial NOT NULL,
itv_item character varying(16) NOT NULL,
itv_debut timestamp without time zone NOT NULL,
itv_fin timestamp without time zone NOT NULL,
CONSTRAINT t_interval_itv_pkey PRIMARY KEY (itv_id),
CONSTRAINT chk_itv_fin_debut CHECK (itv_fin >= itv_debut)
)
WITH (
OIDS=FALSE
);
-- création des index :
CREATE INDEX X_ITV_ITM_FIN_DEB ON T_INTERVAL_ITV(ITV_ITEM, ITV_FIN, ITV_DEBUT);
CREATE INDEX X_ITV_ITM_DEB_FIN ON T_INTERVAL_ITV(ITV_ITEM, ITV_DEBUT, ITV_FIN);
-- création de la procédure d'alimentation :
-- création de la procédure d'alimentation :
CREATE OR REPLACE FUNCTION P_GENERATE_ROWS (
debut_interval TIMESTAMP,
num_items INT,
intervals_par_item INT,
duree_max_ms INT )
RETURNS void AS $$
DECLARE fin_interval TIMESTAMP;
DECLARE i INT;
j INT;
itm VARCHAR(16);
DECLARE d TIMESTAMP;
DECLARE f TIMESTAMP;
DECLARE duree INT;
DECLARE deb INT;
BEGIN
TRUNCATE TABLE t_interval_itv;
fin_interval := debut_interval + FLOOR(intervals_par_item * 0.04) * INTERVAL '1 DAY';
i := 1;
j := 1;
<<whileI>>WHILE i <= num_items LOOP
<<whileJ>>WHILE j <= intervals_par_item LOOP
deb := FLOOR(RANDOM() * 2 * duree_max_ms * intervals_par_item / num_items );
d := debut_interval + deb * INTERVAL '1 MILLISECOND';
duree := FLOOR(RANDOM() * duree_max_ms );
f := d + duree * INTERVAL '1 MILLISECOND';
itm := 'Item' || CAST(i AS VARCHAR(16));
INSERT INTO T_INTERVAL_ITV (ITV_ITEM, ITV_DEBUT, ITV_FIN) VALUES (itm, d, f);
j := j + 1;
END LOOP whileJ;
j := 1;
i := i + 1;
END LOOP whileI;
END; $$ LANGUAGE plpgsql;
-- exécution de la génération
SELECT P_GENERATE_ROWS ('2001-01-01', 10, 100, 3600);
/* test des requĂŞtes */
-- solution 1 classique
WITH
T0 AS
(SELECT PRE.ITV_ITEM,
PRE.ITV_DEBUT AS D1, PRE.ITV_FIN AS F1,
DER.ITV_DEBUT AS D2, DER.ITV_FIN AS F2
FROM T_INTERVAL_ITV PRE
INNER JOIN T_INTERVAL_ITV DER
ON PRE.ITV_DEBUT <= DER.ITV_FIN
AND PRE.ITV_ITEM = DER.ITV_ITEM)
SELECT DISTINCT ITV_ITEM, D1 AS ITV_DEBUT, F2 AS ITV_FIN
FROM T0 AS I
WHERE NOT EXISTS (SELECT *
FROM T_INTERVAL_ITV SI1
WHERE (SI1.ITV_DEBUT < I.D1
AND I.D1 <= SI1.ITV_FIN
AND I.ITV_ITEM = SI1.ITV_ITEM )
OR (SI1.ITV_DEBUT <= I.F2
AND I.F2 < SI1.ITV_FIN
AND I.ITV_ITEM = SI1.ITV_ITEM))
AND NOT EXISTS (SELECT *
FROM T_INTERVAL_ITV SI2
WHERE D1 < SI2.ITV_DEBUT
AND SI2.ITV_DEBUT <= F2
AND I.ITV_ITEM = SI2.ITV_ITEM
AND NOT EXISTS (SELECT *
FROM T_INTERVAL_ITV SI3
WHERE SI3.ITV_DEBUT < SI2.ITV_DEBUT
AND SI2.ITV_DEBUT <= SI3.ITV_FIN
AND SI2.ITV_ITEM = SI3.ITV_ITEM ));
-- solution 2 SnodGrass
WITH T
AS (SELECT F.ITV_DEBUT, L.ITV_FIN, F.ITV_ITEM
FROM T_INTERVAL_ITV AS F
JOIN T_INTERVAL_ITV AS L
ON F.ITV_FIN <= L.ITV_FIN
AND F.ITV_ITEM = L.ITV_ITEM
INNER JOIN T_INTERVAL_ITV AS E
ON F.ITV_ITEM = E.ITV_ITEM
GROUP BY F.ITV_DEBUT, L.ITV_FIN, F.ITV_ITEM
HAVING COUNT(CASE
WHEN (E.ITV_DEBUT < F.ITV_DEBUT AND F.ITV_DEBUT <= E.ITV_FIN)
OR (E.ITV_DEBUT <= L.ITV_FIN AND L.ITV_FIN < E.ITV_FIN)
THEN 1
END) = 0)
SELECT ITV_ITEM, ITV_DEBUT, MIN(ITV_FIN) AS ITV_FIN
FROM T
GROUP BY ITV_ITEM, ITV_DEBUT;
-- solution 3 récursive
WITH RECURSIVE
T0 AS -- suprime les périodes incluses
(SELECT DISTINCT Tout.ITV_ITEM, Tout.ITV_DEBUT, Tout.ITV_FIN
FROM T_INTERVAL_ITV AS Tout
WHERE NOT EXISTS(SELECT *
FROM T_INTERVAL_ITV AS Tin
WHERE Tout.ITV_DEBUT >= Tin.ITV_DEBUT
AND Tout.ITV_FIN < Tin.ITV_FIN
AND Tout.ITV_ITEM = Tin.ITV_ITEM)),
T1 AS -- ancres : périodes de tête...
(SELECT Ta.*, 1 AS ITERATION
FROM T0 AS Ta
WHERE NOT EXISTS(SELECT *
FROM T0 AS Tb
WHERE Tb.ITV_FIN >= Ta.ITV_DEBUT
AND Tb.ITV_FIN < Ta.ITV_FIN
AND Tb.ITV_ITEM = Ta.ITV_ITEM)
UNION ALL -- itération sur période dont le debut est inclus dans les bornes de la période ancre
SELECT T1.ITV_ITEM, T1.ITV_DEBUT, T0.ITV_FIN, T1.ITERATION + 1
FROM T1
INNER JOIN T0
ON T1.ITV_DEBUT < T0.ITV_DEBUT
AND T1.ITV_FIN >= T0.ITV_DEBUT
AND T1.ITV_FIN < T0.ITV_FIN
AND T1.ITV_ITEM = T0.ITV_ITEM),
T2 AS
(SELECT *, ROW_NUMBER() OVER(PARTITION BY ITV_ITEM, ITV_DEBUT ORDER BY ITV_DEBUT - ITV_FIN DESC) AS N1,
ROW_NUMBER() OVER(PARTITION BY ITV_ITEM, ITV_FIN ORDER BY ITV_DEBUT, ITV_FIN DESC) AS N2
FROM T1)
SELECT ITV_ITEM, ITV_DEBUT, ITV_FIN
FROM T2
WHERE N1 = 1 AND N2 = 1;
-- solution 4 GeriReshef
WITH T1 As
(SELECT ITV_ITEM, ITV_DEBUT Temps
FROM T_INTERVAL_ITV
UniON All
SELECT ITV_ITEM, ITV_FIN FROM T_INTERVAL_ITV),
T2 As
(SELECT Row_Number() OVER(PARTITION BY ITV_ITEM ORDER BY Temps) Nm, ITV_ITEM, Temps
FROM T1 T1_1),
T3 As
(SELECT T2_1.Nm-Row_Number() OVER(PARTITION BY T2_1.ITV_ITEM ORDER BY T2_1.Temps,T2_2.Temps) Nm1,
T2_1.ITV_ITEM, T2_1.Temps ITV_DEBUT, T2_2.Temps ITV_FIN
FROM T2 T2_1
Inner join T2 T2_2
ON T2_1.ITV_ITEM=T2_2.ITV_ITEM
And T2_1.Nm=T2_2.Nm-1
WHERE Exists (SELECT *
FROM T_INTERVAL_ITV S
WHERE S.ITV_ITEM=T2_1.ITV_ITEM
And (S.ITV_DEBUT < T2_2.Temps And S.ITV_FIN>T2_1.Temps))
Or T2_1.Temps = T2_2.Temps)
SELECT ITV_ITEM, Min(ITV_DEBUT) ITV_DEBUT, Max(ITV_FIN) ITV_FIN
FROM T3
GROUP BY ITV_ITEM, Nm1;
Sources :
WEB :
http://www.doc.ic.ac.uk/~pjm/teaching/student_projects/jaymin_patel.pdf
http://www.cs.aau.dk/~csj/Thesis/
http://www.sqlmag.com/blogs/puzzled-by-t-sql/tabid/1023/entryid/76057/TSQL-Challenge-Packing-Date-and-Temps-Intervals.aspx
LIVRES:
Spatio-temporal SQL – JosĂ© R. Rios Viqueira and Nikos A. Lorentzos – In « Advances in Informatics Lecture Notes in Computer Science », 2003, Volume 2563/2003, p101-114, – Springer Verlag
Temporal Data & the Relational Model – C.J. Date, Hugh Darwen, Nikos Lorentzos – Morgan Kaufmann 2002 Managing Time in Relational Databases – Tom Johnston – Morgan Kaufmann 2010
The TSQL2 Temporal Query Language – Richard T. Snodgrass – Springer 1995
--------
Frédéric Brouard, SQLpro - ARCHITECTE DE DONNÉES, http://sqlpro.developpez.com/
Expert bases de données relationnelles et langage SQL. MVP Microsoft SQL Server
www.sqlspot.com : modélisation, conseil, audit, optimisation, tuning, formation
* * * * * Enseignant CNAM PACA - ISEN Toulon - CESI Aix en Provence * * * * *
![]()
Bonjour,
Dans le cadre d’un projet, je dois faire une agrĂ©gation d’intervalle.
J’ai tentĂ© d’utiliser la solution 5 puisque dans mon cas la table concernĂ©e comporte un peu plus d’un million de lignes et qu’on peut voir dans cet article que :
On constatera que dans les grandes cardinalités, la solution 6 qui s’avérait l’une des meilleures commence à plonger rapidement. Cela est sans doute du à un changement de plan. En définitive la meilleure solution est la 5 (première requête de Malpashaa).
Malheureusement, une anomalie est remontĂ©e…
En fait, lorsque la pĂ©riode A se termine quand une pĂ©riode B commence, il n’y a pas de souci.
Mais si on rajoute une période C qui commence durant A et se termine durant B alors B et C sont ignorées.
Voici, le script pour faire le test :
INSERT INTO T_INTERVAL_ITV VALUES('Item1', '2017-01-01 00:00:00', '2018-12-01 00:00:00');
INSERT INTO T_INTERVAL_ITV VALUES('Item1', '2017-06-01 00:00:00', '2018-06-01 00:00:00');
Les autres solutions fonctionnent correctement (sauf la solution 6 du mĂŞme auteur) )
)
Pour info, je suis sous SQL Server 2012, je me demande si les intrajointures n’ont pas changĂ©es entre 2008 R2 et 2012 mais je vais laisser les experts nous expliquer pourquoi (il est possible que l’erreur vienne de moi après tout
Visiblement Fred_34, vous n’avez pas compris…. A maintes reprises je vous ai signalĂ© dans les forums que je faisait un comparatif de performance de requĂŞtes et non de procĂ©dures stockĂ©es. Tous les SGBD relationnels savant faire des procĂ©dures stockĂ©es… Sauf que vous ĂŞtes totalement en dehors du sujet en plus de polluer les articles des autres et qui plus est avec un code honteusement mal Ă©crit, faux, en plus de ne pas ĂŞtre indentĂ©….
Mais rien ne vous empĂŞche d’Ă©crire un article sur les performances comparĂ©es des procĂ©dures stockĂ©es de Oracle MySQL, PostGreSQL et Microsoft SQL Server !
DĂ©cidĂ©ment…
Revoici le code, mais il faut remplacer DIFFERENT, INFERIEUR ET INFERIEUR OU EGAL
Si vous le pouvez, n’hĂ©sitez pas Ă supprimez ces posts !
use test;
delimiter $$
drop procedure if exists aggregation$$
create procedure aggregation()
READS SQL DATA
BEGIN
DECLARE currentItem VARCHAR(16) ;
DECLARE currentDebut timestamp;
DECLARE currentFin timestamp;
DECLARE noMoreRow INT DEFAULT 0;
DECLARE previousItem VARCHAR(16) default « »;
DECLARE previousDebut timestamp ;
DECLARE previousFin timestamp ;
DECLARE myCursor CURSOR FOR SELECT ITV_ITEM,ITV_DEBUT,ITV_FIN FROM `t_interval_itv` order by ITV_ITEM,ITV_DEBUT;
DECLARE CONTINUE HANDLER FOR NOT FOUND SET noMoreRow=1;
CREATE TEMPORARY TABLE IF NOT EXISTS `t_interval_itv_temp` (
`ITV_ITEM` varchar(16) NOT NULL,
`ITV_DEBUT` timestamp NOT NULL ,
`ITV_FIN` timestamp NOT NULL ,
PRIMARY KEY (`ITV_ITEM`,`ITV_DEBUT`))ENGINE=MyISAM;
TRUNCATE TABLE `t_interval_itv_temp`;
OPEN myCursor;
myLoop:LOOP
FETCH myCursor INTO currentItem,currentDebut,currentFin;
IF noMoreRow=1 THEN
LEAVE myLoop;
END IF;
IF(previousItem DIFFERENT currentItem) THEN
INSERT INTO `t_interval_itv_temp` (ITV_ITEM,ITV_DEBUT,ITV_FIN) VALUES (currentItem,currentDebut,currentFin);
SET previousItem=currentItem;
SET previousDebut=currentDebut;
SET previousFin=currentFin;
ELSE
IF(previousFin INFERIEUR currentFin) THEN
IF(currentDebut INFERIEUR OU EGAL reviousFin) THEN
UPDATE `t_interval_itv_temp` SET ITV_DEBUT =previousDebut ,ITV_FIN =currentFin WHERE (ITV_ITEM=previousItem AND ITV_DEBUT=previousDebut);
ELSE
INSERT INTO `t_interval_itv_temp` (ITV_ITEM,ITV_DEBUT,ITV_FIN) VALUES (currentItem,currentDebut,currentFin);
SET previousDebut=currentDebut;
END IF;
SET previousFin=currentFin;
END IF;
END IF;
END LOOP myLoop;
CLOSE myCursor;
select * from t_interval_itv_temp;
drop table t_interval_itv_temp;
END;
$$
DELIMITER ;
Oups, il y a un bout qui manque…
IF(previousFin
Bonjour,
Voici une procédure pour Mysql.
Si vous avez un minimum d’objectivitĂ© (Ce que je doute vu la qualitĂ© des rĂ©sultats fournis pour MySQL), vous referez quelques tests avec cette mĂ©thode.
A mon avis, elle est juste et n’a pas grand chose Ă envier Ă vos requĂŞtes incomprĂ©hensibles pour le commun des mortels.
Cdt,
Fred
delimiter $$
drop procedure if exists aggregation$$
create procedure aggregation()
READS SQL DATA
BEGIN
DECLARE currentItem VARCHAR(16) ;
DECLARE currentDebut timestamp;
DECLARE currentFin timestamp;
DECLARE noMoreRow INT DEFAULT 0;
DECLARE previousItem VARCHAR(16) default « »;
DECLARE previousDebut timestamp ;
DECLARE previousFin timestamp ;
DECLARE myCursor CURSOR FOR SELECT ITV_ITEM,ITV_DEBUT,ITV_FIN FROM `t_interval_itv` order by ITV_ITEM,ITV_DEBUT;
DECLARE CONTINUE HANDLER FOR NOT FOUND SET noMoreRow=1;
CREATE TEMPORARY TABLE IF NOT EXISTS `t_interval_itv_temp` (
`ITV_ITEM` varchar(16) NOT NULL,
`ITV_DEBUT` timestamp NOT NULL ,
`ITV_FIN` timestamp NOT NULL ,
PRIMARY KEY (`ITV_ITEM`,`ITV_DEBUT`))ENGINE=MyISAM;
TRUNCATE TABLE `t_interval_itv_temp`;
OPEN myCursor;
myLoop:LOOP
FETCH myCursor INTO currentItem,currentDebut,currentFin;
IF noMoreRow=1 THEN
LEAVE myLoop;
END IF;
IF(previousItemcurrentItem) THEN
INSERT INTO `t_interval_itv_temp` (ITV_ITEM,ITV_DEBUT,ITV_FIN) VALUES (currentItem,currentDebut,currentFin);
SET previousItem=currentItem;
SET previousDebut=currentDebut;
SET previousFin=currentFin;
ELSE
IF(previousFin
cinephil : Toujours en lecture rapide, je suis Ă©tonnĂ© de ne pas voir de solution utilisant OVERLAPS ; cette fonction n’est-elle implantĂ©e sur aucun SGBD testĂ© ou bien n’est-elle tout simplement pas appropriĂ©e sur ce problème ?
Non OVERLAPS n’aurait pas Ă©tĂ© d’un grand intĂ©rĂŞt pour ce cas de figure, car il retourne un boolĂ©en lĂ ou il nous faudrait une pĂ©riode….
ced : je suis Ă©tonnĂ© que MySQL arrive Ă faire tourner les 2 premières requĂŞtes, vue qu’elles ont une clause WITH
Comme vous pouvez le constater dans le paragraphe « Script pour MS SQL Server » les requĂŞtes ont Ă©tĂ© rĂ©crites sans clause WITH pour MySQL.
ced : Deuxième remarque : une comparaison pur et dur des 3 SGBDR annoncĂ©e telle que, sans connaĂ®tre un peu mieux les paramètres de configuration de chacun, n’a pas beaucoup de sens.
Vous avez raison, j’ai omis de dire que c’Ă©tait l’installation par dĂ©faut avec aucun paramĂ©trage pour aucun serveur. Je vais rectifier ce point dans « condition du test ».
Mais comme chacun des SGBDR peut ĂŞtre paramĂ©trĂ©, cela n’a pas grand sens. Il faudrait trouver un spĂ©cialiste de chacun des SGBDR, ce qui n’est pas chose courante dans la grande majoritĂ© des SGBDR en exploitation !
Mais, pour rappel, la table avec 10 000 lignes dedans, fait moins de 400 Ko… Donc, avec 32 MB, vous traitez 800 000 lignes en mĂ©moire avec PG !
Or la diffĂ©rence se voit bien avant… L’argument du mauvais tuning de PG n’est donc pas recevable !
NOTA : les erreurs d’interprĂ©tation ont Ă©tĂ© rectifiĂ©e.. Ou avais-je la tĂŞte !
Bonjour,
Je suis Ă©tonnĂ© que MySQL arrive Ă faire tourner les 2 premières requĂŞtes, vue qu’elles ont une clause WITH que, Ă ma connaissance, MySQL ne supporte pas encore… Ou alors la version 5.5 les prend en charge ?
Deuxième remarque : une comparaison pur et dur des 3 SGBDR annoncĂ©e telle que, sans connaĂ®tre un peu mieux les paramètres de configuration de chacun, n’a pas beaucoup de sens.
Quels paramètres ont Ă©tĂ© appliquĂ©s ? Ceux par dĂ©faut après installation ? Parce que, par exemple, pour PostgreSQL, certains paramètres sont clairement faibles dans l’installation par dĂ©faut et mĂ©ritent quelques petits ajustements pour amĂ©liorer nettement les performances de requĂŞtes un peu gourmandes (shared_buffers, par exemple). Idem pour MySQL, dont il existe plusieurs versions du fichier de configuration (my.ini) dont le choix modifie sensiblement le comportement en termes de performances.
Je ne sais pas comment SQL Server est paramĂ©trĂ© par dĂ©faut. En tout cas, le processeur et la RAM du serveur ne font pas tout, loin s’en faut…
En lecture rapide, il m’a semblĂ© aussi qu’il y a quelques coquilles dans l’interprĂ©tation des rĂ©sultats !
Toujours en lecture rapide, je suis Ă©tonnĂ© de ne pas voir de solution utilisant OVERLAPS ; cette fonction n’est-elle implantĂ©e sur aucun SGBD testĂ© ou bien n’est-elle tout simplement pas appropriĂ©e sur ce problème ?