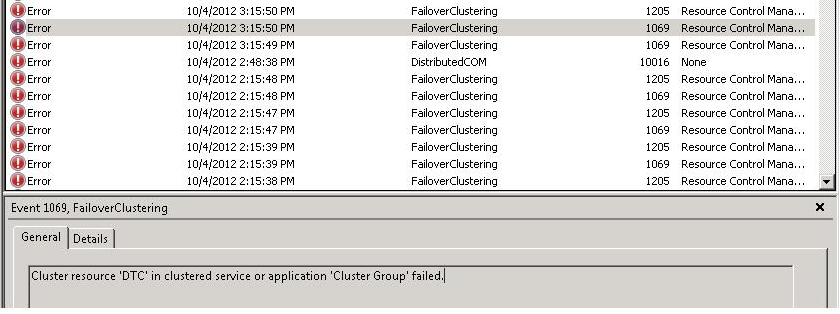
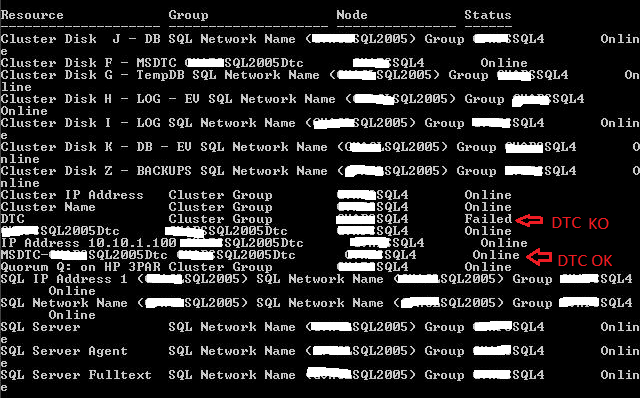
Instant File Initialization est une option connue des DBA et permet d’accĂ©lĂ©rer certaines opĂ©rations faisant de la rĂ©servation d’espace disque. Avec SQL Server cela se traduit par les opĂ©rations de crĂ©ation, restauration de bases de donnĂ©es ou encore ajout de fichiers, modification de taille ou encore expansion de fichiers … Bref cette option est souvent très bĂ©nĂ©fique pour les performances mais celle-ci exige quelques prĂ©requis qui sont les suivants :
- Le fichier n’est pas un fichier journal d’une base de donnĂ©es
- Le système d’exploitation supporte l’utilisation de la fonction SetFileValidData()
- Le compte de service SQL possède le privilège SE_MANAGE_VOLUME_NAME
- Le fichier n’est pas un fichier sparse
- Le fichier n’est pas concernĂ©e par du chiffrement TDE
- Trace flag 1806 n’est pas activĂ© sur l’instance SQL (ce traceflag dĂ©sactive l’utilisation de cette fonctionnalitĂ©)
Ce qui nous intĂ©resse ici c’est l’utilisation de la fonction SetFileValidData(). Nous voila donc plongĂ© dans la documentation des API Windows et de notre fonction SetFileValidData(). Voici ce que la documentation nous propose :
Sets the valid data length of the specified file. This function is useful in very limited scenarios. For more information, see the Remarks section.
Dans la section remarques nous avons :
The SetFileValidData function sets the logical end of a file. To set the size of a file, use the SetEndOfFile function. The physical file size is also referred to as the end of the file.
Each file stream has the following properties:
- File size: the size of the data in a file, to the byte.
- Allocation size: the size of the space that is allocated for a file on a disk, which is always an even multiple of the cluster size.
- Valid data length: the length of the data in a file that is actually written, to the byte. This value is always less than or equal to the file size.
…
The SetFileValidData function allows you to avoid filling data with zeros when writing nonsequentially to a file. The function makes the data in the file valid without writing to the file. As a result, although some performance gain may be realized, existing data on disk from previously existing files can inadvertently become available to unintended readers
…
A caller must have the SE_MANAGE_VOLUME_NAME privilege enabled when opening a file initially
Pour rĂ©sumer : cette fonction va nous permettre d’Ă©viter le remplissage de zĂ©ros dans un fichier lorsque les Ă©critures ne sont pas sĂ©quentielles
Pourquoi pour des opĂ©rations non sĂ©quentielles ? Effectivement si l’on Ă©crit de manière sĂ©quentielle dans un fichier la phase d’Ă©criture de zĂ©ro est relativement rapide puisque l’on Ă©crit toujours Ă la suite des donnĂ©es prĂ©cĂ©dentes
Cependant si l’on Ă©crit de manière alĂ©atoire, le problème est tout autre. Imaginez que l’on Ă©crive la première au dĂ©but du fichier et la 2ème fois Ă la fin, il va donc falloir remplir de zĂ©ros le fichier de la première Ă©criture jusqu’Ă la 2ème. La documentation le stipule bien : chaque fichier doit possĂ©der notamment une propriĂ©tĂ© Valid data length qui correspond Ă la longueur des donnĂ©es Ă©crites dans le fichier. Cette opĂ©ration, vous l’avez compris, peut prendre du temps en fonction de la longueur Ă initialiser. SQL Server Ă©crit de manière alĂ©atoire dans le fichier mĂŞme lors de son initialisation. C’est la raison pour laquelle l’utilisation de cette option est très intĂ©ressante ici.
Ecriture séquentielle :

Ecriture aléatoire :

L’utilisation de procmon peut nous permettre de visualiser l’utilisation des fonctions SetEndOfFile() et SetFileValidData(). J’ai simplement crĂ©Ă© une base de donnĂ©es simple avec le fichier de donnĂ©es TestIntantFileInitializationWith.mdf.
- Dans le cas oĂą Instant File Initialization n’est pas activĂ©

On ne voit ici que l’utilisation de la fonction SetEndOfFile(). Cette fonction est utilisĂ©e dans tous les cas pour fixer physiquement la fin du fichier. Dans le cas prĂ©sent la fin du fichier est fixĂ©e Ă 10485760 octets soit 10Go.
- Dans le cas où Instant File Initialization est activé

Une fonction supplémentaire est utilisée ici SetFileValidDate() qui permet de valider la longueur des données dans le fichier mdf : ValidDataLength : 10485760 (10Go de données dans un fichier de 10Go)
David BARBARIN (Mikedavem)
MVP SQL Server