Après quelques missions d’architecture sur l’implémentation d’architectures AlwaysOn chez divers clients il est temps de faire un point sur les possibilités de configuration du quorum du cluster Windows. En effet, pour rappel SQL Server AlwaysOn ou SQL Server FCI se basent tous les 2 sur une couche Windows Failover Cluster Service (WFCS). Par conséquent le bon fonctionnement des groupes de disponibilités AlwaysOn ou des instances en cluster SQL reposent en quelque sorte sur celui du cluster Windows. Lorsqu’on parle de cluster Windows on arrive très vite à parler de quorum. La notion même de quorum n’est d’ailleurs pas uniquement associée au cluster. On peut la retrouver également lorsqu’on parle d’architecture en miroir avec SQL Server en mode synchrone et basculement automatique. Le but de ce billet est simplement de parcourir un peu les différentes possibilités de configuration du quorum avec WFSC à partir de 2008 R2 et de faire un focus sur les dernières innovations proposées par Windows Server 2012 et Windows Server 2012 R2.
 Windows Server 2008 R2
Windows Server 2008 R2
Au fur et à mesure des versions Microsoft a fait évoluer ses modèles de quorum dans un processus continue d’amélioration de disponibilité du cluster Windows dans des scénarios de plus en plus divers. Par exemple on est passé de 2 modèles de quorum avec Windows 2003 à 4 à partir de Windows 2008. Windows 2008 a plus tard introduit la notion de paramétrage des poids de vote (avec l’application du KB2494036) qui peut s’avérer très utile dans des scénarios de type “géo-cluster”. Cependant si le paramétrage du poids de vote se révèle très utile dans certains cas il n’en reste pas moins que celui-ci reste statique. En fonction de la situation c’est à l’administrateur de cluster de changer la configuration des poids de vote afin de garantir le quorum lors de la défaillances de nœuds.
L’image suivante montre 3 scénarios pour une architecture cluster Windows et pourquoi la nature statique du paramétrage du poids de vote peut poser problème :

Dans cette architecture le nœud 4 est sur un site distant. Comme nous ne voulons pas que ce nœud influence le vote du quorum en cas de coupure réseau entre les 2 sites nous pouvons lui supprimer la possibilité de voter dans l’établissement du quorum.
Scénario 1 :
Dans ce scénario il nous reste donc 3 nœuds qui peuvent voter (node 1, node 2 et node 3). Dans ce cas nous avons la possibilité d’utiliser le modèle de quorum “nœuds majoritaire” parce que le nombre de nœuds est impair ici. Dans cette configuration nous pouvons perdre jusqu’à 2 nœuds : le nœud 4 qui n’influence pas le vote du quorum via notre configuration et un des nœuds restants. Dans le cas où le nœud 4 aurait un vote nous ne pourrions perdre qu’un seul nœud.
Scénario 2 :
Dans ce scénario nous perdons le nœud 2 suite à une défaillance matérielle. Dans ce cas le cluster reste en ligne puisqu’il faut au minimum 2 nœuds pour effectuer le quorum. Cependant la perte d’un autre nœud risque à ce moment de compromettre la disponibilité du cluster. Dans ce cas l’administrateur du cluster Windows a 2 plusieurs possibilités :
- Changer le quorum en ajoutant un témoin pour augmenter le nombre de votes possibles afin d’avoir la majorité en cas de défaillance d’un nœud
- changer le nombre de votes possible à 1 seul nœud et en cas de défaillance du nœud 1 le cluster resterait en ligne (Dans notre exemple le nœud 3 perd sa possibilité de voter lors du quorum).
Scénario 3 :
Le nœud 2 a été réparé et est à nouveau opérationnel. Il faut de nouveau changer la configuration de poids de vote des nœuds pour augmenter la disponibilité du cluster en cas défaillance. En effet le vote étant ciblé uniquement sur un seul nœud, il devient le SPOF de cette topologie haute disponibilité. L’administrateur du cluster doit à nouveau activer le vote pour les nœuds 2 et 3 afin de garder en ligne le cluster Windows.
Pour résumer, le but du jeu ici est de jouer avec le poids de votes des nœuds tout en gardant à l’esprit qu’il faut garder plus 50% des votes pour garder le quorum en ligne !!
Windows Server 2012
Windows Server 2012 a changé la donne et a introduit le concept de quorum dynamique. Cette nouvelle fonctionnalité est intéressante car elle permet au cluster de recalculer à la volée le nombre de votes nécessaires pour que le cluster reste au maximum disponible. Ainsi il est possible d’avoir un cluster en ligne avec moins de 50% des nœuds restants. A noter qu’il est toujours possible d’exclure des nœuds dans le vote du quorum avec un recalcul automatique qui ne tiendra compte uniquement que des nœuds restants.
En reprenant les scénarios décrits précédemment :
Scénario 1 :

On peut voir qu’il existe une nouvelle propriété appelée DynamicWeight. Le nœud 4 ne dispose pas de poids de vote (NodeWeight = 0) et par conséquent celui-ci ne sera pas pris en compte dans le calcul dynamique du quorum (dynamicweight=0) contrairement aux autres nœuds (NodeWeight et Dynamicweight = 1).
Scénario 2 :

On voit ici que le nœud 2 a subit une défaillance (State = Down) et que le calcul dynamique du quorum a été effectué par le cluster Windows. Par conséquent seul le nœud 3 possède un poids de vote ce qui permettra de garder en ligne le cluster en cas de défaillance d’un autre nœud de la topologie (nœud 1 ou 3).

L’arrêt du nœud 3 a déclenché à nouveau le recalcul du quorum par le cluster Windows. Ce dernier a transféré le poids de vote au seul nœud restant en ligne (nœud 1).

Les nœuds 2 et 3 ont été remis en ligne et à nouveau le cluster Windows a recalculé le poids de vote des nœuds pour le quorum.
Même si cette fonctionnalité présente des avantages certains, elle n’est cependant pas parfaite. En effet pour que le quorum se recalcule correctement, il faut que la défaillance des nœuds soit séquentielle dans le temps et que le recalcul du quorum ait eu le temps de s’effectuer. De plus l’introduction d’une ressource témoin avec Windows Server 2012 reste inchangé par rapport à Windows Server 2008 R2 à savoir que le témoin possède un poids de vote statique dans tous les cas ce qui diminue paradoxalement la disponibilité du cluster dans certains cas. Modifions notre architecture en y ajoutant un nœud supplémentaire de la façon suivante :

L’ajout d’un nœud pose ici un problème quant à l’établissement du quorum en cas de défaillance d’un des nœuds autre que nœud 5. Celui-ci comme dans l’architecture précédente n’est pas pris en compte dans le vote du quorum, ce qui laisse un nombre pair de nœuds qui peuvent voter. Dans cette configuration et sans quorum dynamique la défaillance de 2 nœuds ferait tomber à coup sûr l’ensemble du cluster Windows. En d’autres termes, la défaillance d’un seul nœud est supportée dans cette configuration. L’ajout d’une ressource témoin permet de pallier ce problème en ajoutant un vote supplémentaire afin d’augmenter le nombre de nœuds qui peuvent être défaillants à 2. Cependant avec l’utilisation du quorum dynamique, le recalcul se fera en tenant compte uniquement les nœuds du cluster restants en ligne. Le nombre de vote final sera donc composé de celui des nœuds restants + celui de la ressource témoin. Que se passera-t-il au moment où il restera un seul nœud en ligne et si l’on perd notre ressource témoin ? Malheureusement le quorum ne pourra être établi car il faudrait avoir au minimum 2 votes.

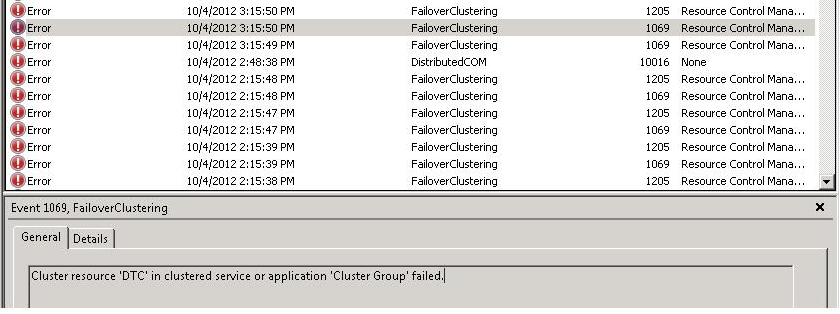
Ci-dessous un extrait de ce que l’on peut retrouver dans les logs du cluster Windows dans le cas où l’on perd une ressource témoin et par la suite le dernier nœud permettant au cluster Windows de rester en ligne.
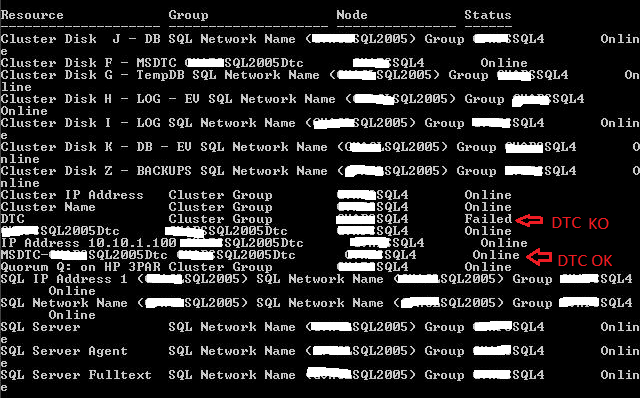
Ici la ressource témoin est un dossier partagé qui n’est plus accessible ([RES] File Share Witness … Failed to create / Failed to validate etc …). Cependant le cluster peut encore rester en ligne puisque 2 nœuds sont encore présents pour faire le quorum (2 votes sur 3).

Cependant si l’on perd le dernier nœud (ici SQL122) comme montré ci-dessous …

… le début des problèmes commence puisque le cluster, malgré l’utilisation du quorum dynamique, se base encore sur le vote de la ressource témoin comme montré ci-dessous (File Share Witness is quorum and we’re one off quorum …). En effet à ce moment il n’existe plus qu’un seul vote sur 3 pour réaliser le quorum ce qui n’est plus suffisant. Après quelques secondes le cluster Windows


Windows Server 2012 R2
C’est ici que Windows Server 2012 R2 va avoir toute son utilité avec l’utilisation du témoin dynamique. Cette fonctionnalité permet de pallier au problème que nous venons de voir précédemment. Le vote du témoin est maintenant lui aussi dynamique et le cluster Windows recalcule le nombre de votes en fonction de la situation en tenant compte de ce nouvel élément.
L’image suivante montre la même situation que précédemment avec une topologie SQL Server 2014 décrite-dessus avec 5 nœuds dont un qui n’aura pas de vote pendant l’établissement du quorum. Au final nous avons 4 nœuds avec un poids de vote à 1.

On a également une ressource témoin de type FileShareWitness mais avec une nouvelle propriété WitnessDynamicWeight reflétant le caractère dynamique de la ressource témoin.


Que se passe-t-il si l’on perd la ressource témoin ?

On peut voir que la répartition des votes octroyés aux nœuds du cluster a changé dynamiquement. Premièrement le système a supprimé le vote de la ressource témoin et il a ensuite recalculé les votes de chaque nœud en supprimant celui octroyé au nœud 2 (SQL142). Cette nouvelle configuration prend en compte le fait que le nombre de nœuds restants pouvant voter est devenu pair et qu’il faut supprimer un vote à un des nœuds pour que celui-ci devienne impair.

En arrêtant successivement les nœuds 2 et 4 le quorum est de nouveau recalculé comme avec Windows 2012. Le nœud 3 est le seul à posséder un poids de vote car il possède le groupe de ressource système (nom réseau + IP du cluster Windows). Cela permet également en cas de défaillance du nœud 1 (ou éventuellement du nœud 3) de garder le cluster Windows en ligne

L’utilisation du témoin dynamique est également intéressante dans des configurations géo-clusters où le nombre de nœuds sur chaque site est équivalent. Prenons par exemple la configuration suivante :

Le cluster Windows possède 4 nœuds répartis par pair sur chaque site. Tous les nœuds du cluster peuvent voter et comme nous sommes dans une configuration où le nombre de nœuds par site est pair une ressource témoin a été ajouté sur le 1er site pour augmenter la disponibilité du cluster en cas de défaillance du lien réseau inter-sites. En effet sans cette ressource témoin, si une défaillance survenait sur ce lien réseau nous pourrions être dans un cas de “split brain” avec l’apparition d’un partitionnement du cluster Windows en 2 parties. De plus le nombre de votes dans ce cas ne suffirait plus puisque la perte d’un seul nœud ne serait plus acceptable. Avec l’introduction du témoin nous éliminons du coup ce phénomène de “split brain” et nous augmentons en même temps le nombre global de nœuds qui pouvant être défaillants soit 2 nœuds. Cependant la perte de cette ressource témoin en mode statique nous ramènerait au problème décrit un peu plus haut dans le billet . L’utilisation du témoin dynamique plus une nouvelle fonctionnalité de Windows Server 2012 R2 appelée “tie breaker” permet de garder le nombre de noeuds restants pouvant voter impair. C’est ce que nous pouvons voir ici après la perte du témoin :

Cependant si ce recalcul dynamique est bénéfique ici il serait intéressant aussi de pouvoir contrôler quels nœuds auront la priorité sur les autres pendant le recalcul. Dans notre cas nous voudrions par exemple garder un maximum de disponibilité sur le site A et donc donner la priorité aux serveurs correspondants. Heureusement pour nous il est possible de configurer des priorités par nœud avec la propriété de cluster LowerQuorumPriorityNodeID.


On voit ici que l’assignement des poids de vote a changé en fonction de notre paramétrage.

Maintenant si nous perdons totalement le site 2 nous pourrons garantir que le cluster Windows sera encore en ligne.
Bonne configuration de quorum !!
David BARBARIN (Mikedavem)
MVP et MCM SQL Server